LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
-
ArXiv URL: http://arxiv.org/abs/2303.16199v3
-
作者: Aojun Zhou; Shilin Yan; Xiangfei Hu; Y. Qiao; Hongsheng Li; Jiaming Han; Pan Lu; Renrui Zhang; Peng Gao
-
发布机构: CPII of InnoHK; CUHK; Shanghai Artificial Intelligence Laboratory; University of California
TL;DR
本文提出了一种名为 LLaMA-Adapter 的高效微调方法,它通过引入一个仅有1.2M可学习参数、带有零初始化注意力的轻量级适配器,在冻结 LLaMA 模型主体的情况下,实现了快速(1小时内)、高效的指令微调,并能轻松扩展到多模态任务。
关键定义
- LLaMA-Adapter: 一种为大型语言模型 LLaMA 设计的轻量级适配方法。它通过在模型中插入极少量的可学习参数,实现高效的指令遵循能力微调,而无需改动或训练模型本身的7B参数。
- 适配提示 (Adaption Prompts): 一组可学习的向量(或称为 soft prompts),作为前缀被拼接到 Transformer 高层网络中的词 token 序列上。这些提示旨在学习和编码指令信息,以引导模型的生成过程。
- 零初始化注意力 (Zero-initialized Attention): 本文的核心创新机制。它修改了标准自注意力模块,引入一个可学习的门控因子 \(g\),并将其初始化为零。这个门控因子用于控制“适配提示”在注意力计算中的影响,从而在训练初期保留模型的预训练知识,后续再逐步注入新的指令知识。
- 零门控 (Zero Gating): 指零初始化注意力机制中那个被初始化为零的可学习门控因子 \(g\)。它的作用是自适应地调节来自适配提示的信息流强度,确保训练初期的稳定性和最终的优越性能。
相关工作
当前,通过指令微调(Instruction Tuning)使大型语言模型(LLMs)具备遵循人类指令的能力是研究热点,例如 InstructGPT 和 Stanford Alpaca。Alpaca 通过对 LLaMA 7B 模型的全参数微调取得了巨大成功,但这种方式计算和时间成本高昂,难以快速部署和迁移。
参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)技术,如 Prompt Tuning、LoRA 和 Adapter,旨在通过只训练少量参数来解决这个问题。然而,现有方法在应用于 LLaMA 这类模型的指令微调时,或效率有待提升,或难以扩展到多模态输入(如图像)。
本文旨在解决的核心问题是:如何以最低的计算成本(最少的可训练参数和最短的训练时间)对 LLaMA 进行指令微调,使其达到与全参数微调相当的性能,并且该方法应具备良好的扩展性,能够处理多模态指令。
本文方法
核心架构:适配器提示
本文提出的 LLaMA-Adapter 方法在冻结整个 LLaMA 预训练模型(7B参数)的基础上,仅引入了少量的可学习模块。
其核心设计是在 LLaMA 的 $N$ 层 Transformer 结构中的顶部 $L$ 层($L \le N$),插入一组可学习的适配提示 (Adaption Prompts),记为 ${P_l}_{l=1}^L$。在第 $l$ 层,长度为 $K$ 的适配提示 $P_l$ 会被拼接到长度为 $M$ 的词 token 序列 $T_l$ 前面,形成新的输入序列:
\[[P_l; T_l] \in \mathbb{R}^{(K+M)\times C}\]其中 $C$ 是特征维度。通过这种方式,在 $P_l$ 中学习到的指令知识,可以通过后续的注意力层来引导 $T_l$ 生成符合指令的上下文响应。
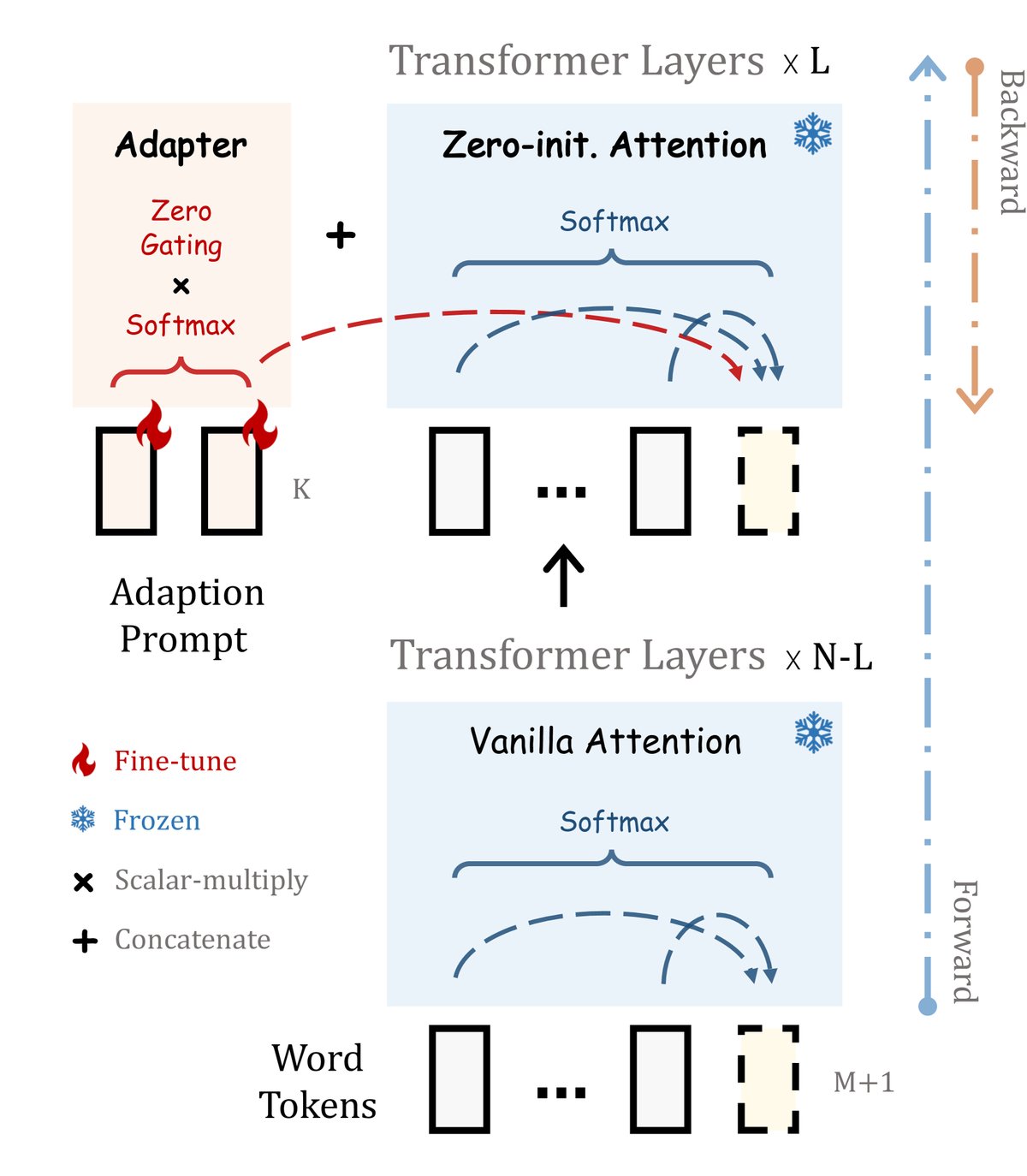
创新点:零初始化注意力
为了解决随机初始化的适配提示在训练初期可能引入噪声、干扰模型原有知识的问题,本文提出了一种创新的零初始化注意力 (Zero-initialized Attention) 机制。
在标准的自注意力计算中,注意力分数 $S_l$ 来自查询 $Q_l$ 和键 $K_l$ 的点积。本文将键 $K_l$ 对应的注意力分数 $S_l$ 拆分为两部分:一部分来自适配提示 ($S_l^K$),另一部分来自词 token ($S_l^{M+1}$)。
关键的改动在于,引入一个可学习的、初始化为零的门控因子 (gating factor) $g_l$,并用它来调节来自适配提示的注意力分数。修改后的注意力分数 $S_l^g$ 计算如下:
\[S_l^g = [\operatorname{softmax}(S_l^K) \cdot \operatorname{tanh}(g_l); \ \ \operatorname{softmax}(S_l^{M+1})]^T\]这里,\(tanh\) 激活函数将 $g_l$ 的值约束在-1到1之间。
优点
- 训练稳定性: 在训练初期,$g_l$ 的值接近于零,使得 $\operatorname{tanh}(g_l) \approx 0$。这意味着来自适配提示的信息流几乎被完全“关闭”,模型主要依赖其强大的预训练知识进行生成,从而避免了随机噪声的干扰,保证了训练过程的稳定。
- 知识的渐进式注入: 随着训练的进行,模型会逐渐学习并增大 $g_l$ 的值,从而“打开”门控,将从适配提示中学到的指令知识平滑地、自适应地注入到模型中。
- 保留预训练知识: 该机制通过对两部分分数分别进行 softmax,并只对提示部分施加门控,确保了词 token 之间的原始注意力分布不受干扰,有效保留了 LLaMA 的强大基础能力。
扩展性:多模态推理
LLaMA-Adapter 的架构具有很强的灵活性,可以简单地扩展到多模态任务,如处理图像条件的指令。
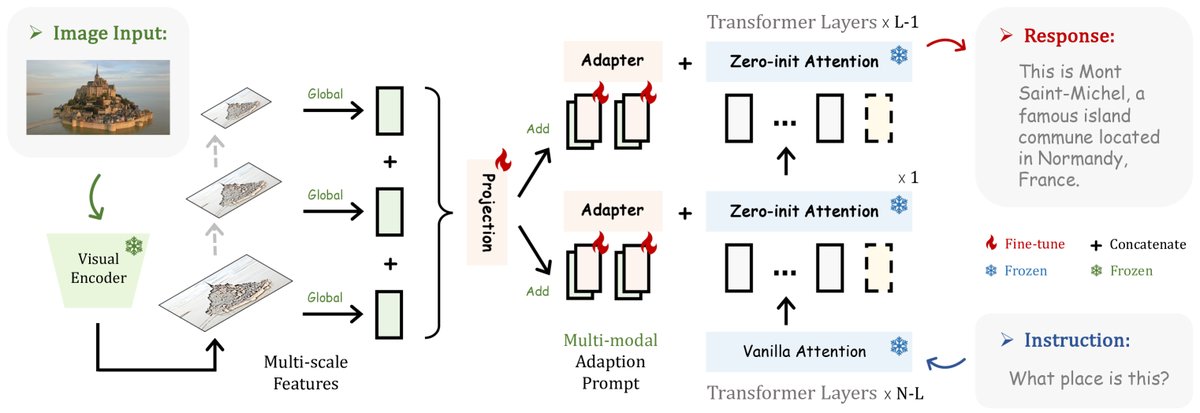
具体实现方法是:
- 使用一个预训练的视觉编码器(如 CLIP)提取图像的全局特征 $I_p$。
-
将该图像特征 $I_p$ 逐元素地添加到每一层的适配提示 $P_l$ 上,形成包含视觉信息的多模态提示 $P_l^v$:
\[P_l^v = P_l + \operatorname{Repeat}(I_p)\] - 之后的过程与纯文本任务完全相同,零初始化注意力机制会学习如何将这些包含图像语义的提示信息融合到语言模型中。
这种设计使得模型只需训练适配器和少量的投影层,就能高效地具备理解视觉内容并根据其进行推理和生成的能力。
实验结论

效率与性能
- 高效性: LLaMA-Adapter 仅用 1.2M 可学习参数和在8卡A100上 1小时 的训练时间,就完成了 LLaMA 7B 模型的指令微调。相比之下,全参数微调的 Alpaca 需要训练 7B 参数,耗时 3小时;Alpaca-LoRA 也需要 4.2M 参数和 1.5小时。
| 模型 | 可调参数 | 存储空间 | 训练时间 |
|---|---|---|---|
| Alpaca | 7B | 13G | 3 小时 |
| Alpaca-LoRA | 4.2M | 16.8M | 1.5 小时 |
| LLaMA-Adapter | 1.2M | 4.7M | 1 小时 |
- 指令遵循能力:
- 在定性评估中(问答、翻译、代码生成),LLaMA-Adapter 生成的回答质量与全参数微调的 Alpaca 相当。
- 在由 GPT-4 作为裁判的定量评估中,LLaMA-Adapter 的胜率高于 Alpaca 和 Alpaca-LoRA。
多模态能力
- 在 ScienceQA 数据集上,多模态 LLaMA-Adapter (1.8M 可调参数) 取得了 85.19% 的准确率,优于包括 GPT-3.5/GPT-4 在内的众多基线模型。
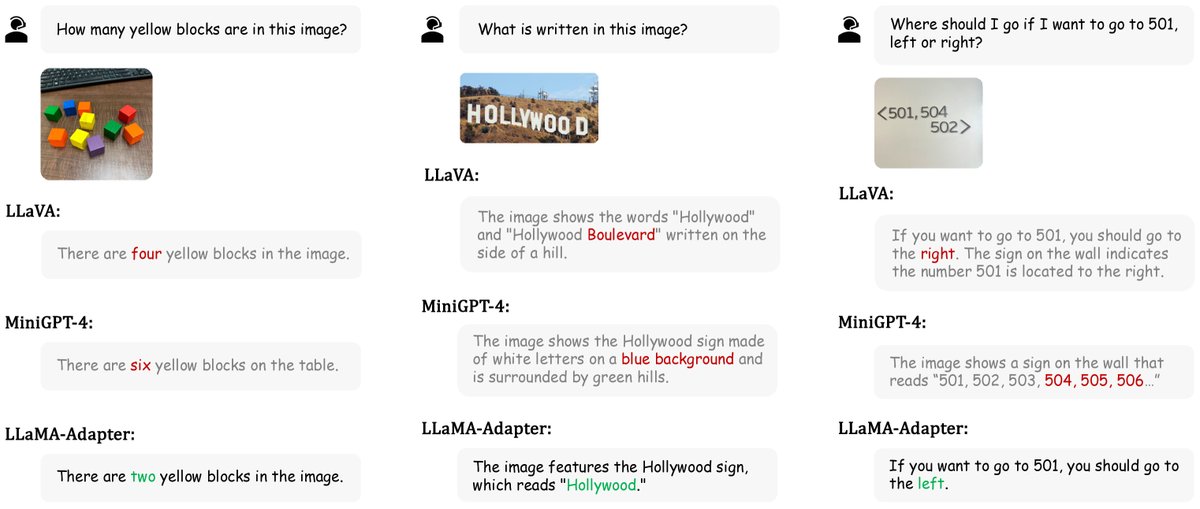
- 在 MME、MMBench、LVLM-eHub 等多个零样本多模态评测基准上,LLaMA-Adapter 取得了与 LLaVA 和 MiniGPT-4 等需要全参数微调或更大模型的方法相竞争的性能,展示了其高效调优策略的优势。
消融研究
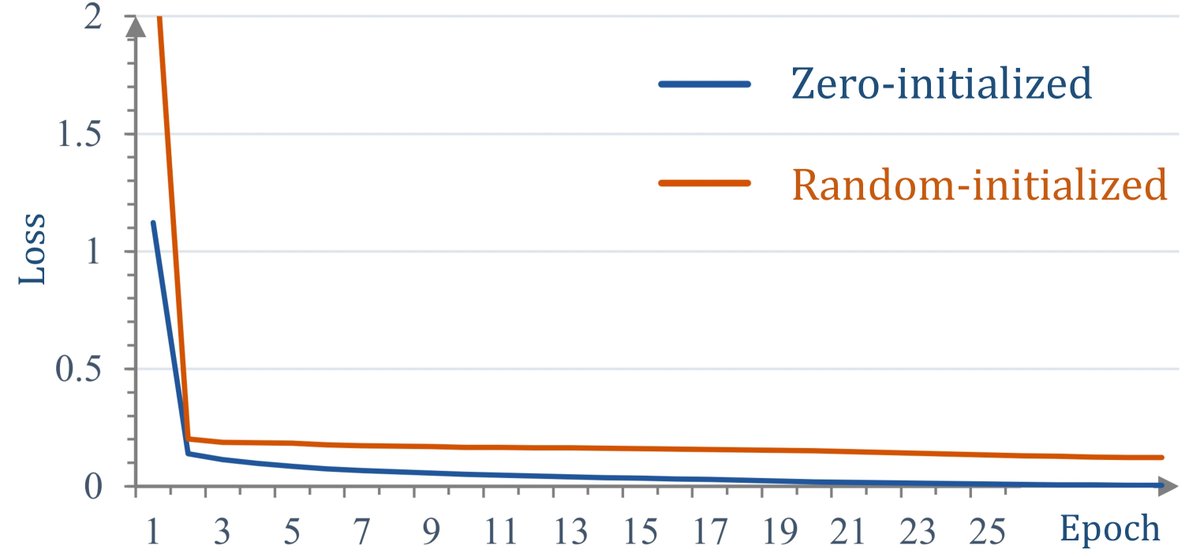
- 零初始化注意力的重要性: 如果去除零初始化,改为随机初始化门控因子,模型在 ScienceQA 上的准确率从 83.85% 骤降至 40.77%(下降了43.08%),几乎等同于随机猜测。训练损失曲线也表明,零初始化使得模型收敛更快、损失更低,验证了该设计的关键作用。
泛化性
- 本文提出的零初始化注意力机制不仅适用于 LLaMA,还可以泛化到其他预训练模型。在对 ViT (视觉)、RoBERTa (语言) 和 CLIP (视觉-语言) 的参数高效微调任务中,该方法均取得了优于全参数微调和其他 PEFT 方法的性能。
最终结论
LLaMA-Adapter 是一种极其高效且有效的指令微调方法。其核心创新“零初始化注意力机制”通过渐进式地注入新知识,同时保留预训练模型的原有能力,成功地解决了高效微调中的训练稳定性问题。该方法以极小的参数量和训练成本,实现了与全参数微调相媲美的性能,并展现出强大的多模态扩展能力和广泛的泛化性。