Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
-
ArXiv URL: http://arxiv.org/abs/2312.06674v1
-
作者: Qing Hu; Michael Tontchev; K. Upasani; Davide Testuggine; Yuning Mao; Krithika Iyer; Hakan Inan; Brian Fuller; Madian Khabsa; Jianfeng Chi; 等1人
-
发布机构: Meta
TL;DR
本文提出 Llama Guard,一个基于 Llama2-7b 的开源模型,通过将其构建为一种遵循指令的分类器,为人类与AI的对话提供可定制的、高效的输入-输出内容安全防护。
关键定义
本文提出了一套用于评估对话安全的风险分类体系,并基于此构建了 Llama Guard。其核心概念是:
- 安全风险分类体系 (Safety Risk Taxonomy):本文定义了一套包含六个类别的风险内容分类标准,用于指导内容安全分类器的开发。这套体系并非旨在覆盖所有风险,而是作为一个通用且可扩展的范例。
- 输入-输出防护 (Input-Output Safeguard):一种机制,用于审查进入和离开大型语言模型 (Large Language Model, LLM) 的所有内容。它不仅要评估用户输入(prompt)的安全性,还要评估AI智能体生成响应(response)的安全性,以防止模型产生违反政策或有害的内容。
- 指令遵循任务 (Instruction-following Task):本文将内容安全分类问题框架化为一个指令遵循任务。模型接收包含安全指南、对话内容和输出格式要求的指令,然后生成分类结果。这使得模型能够通过更改指令来适应不同的安全策略。
- 提示与响应分类 (Prompt vs. Response Classification):本文明确区分了对用户提示和AI响应的分类任务。由于用户和AI智能体在对话中扮演不同角色(用户通常是请求信息,智能体通常是提供信息),对二者的安全评估标准也应有所不同。Llama Guard 通过在指令中明确任务类型,用同一个模型实现了这两种不同的分类。
相关工作
目前,为生成式AI产品部署内容安全护栏是行业推荐的最佳实践。开发者通常会考虑使用现有的内容审核工具,如 Perspective API、OpenAI Content Moderation API 和 Azure Content Safety API。
然而,这些现有工具在用作会话AI的输入-输出护栏时存在几个关键瓶颈:
- 角色不分:它们没有区分评估用户提示(输入)和AI响应(输出)所带来的安全风险,而这两者在语义和意图上通常是不同的。
- 策略固定:每个工具都执行一套固定的安全策略,用户无法根据自身需求或新出现的风险进行调整。
- 闭源且不可定制:这些工具大多只提供API访问,用户无法通过微调(fine-tuning)来适配特定的用例。
- 模型能力有限:它们大多基于传统的、规模较小的Transformer模型,其理解和推理能力相比于先进的大型语言模型(LLM)有所欠缺。
本文旨在解决上述问题,通过利用LLM作为审核骨干,创建一个开放、可定制且能区分对话角色的输入-输出安全防护模型。
本文方法
本文的核心方法是将内容安全分类任务转化为一个大型语言模型(LLM)的指令遵循任务,并基于此训练了 Llama Guard 模型。
方法本质:作为指令遵循任务的安全分类
Llama Guard 将安全分类任务解构成一个结构化的指令,该指令包含四个关键要素:
- 安全指南 (Guidelines):指令中明确列出需要评估的风险类别及其描述。这使得模型只关注当前任务所定义的风险范畴。Llama Guard 使用了本文定义的六类风险分类体系进行训练,但用户可以在推理时提供新的指南。
- 分类类型 (Type of classification):指令明确指出当前任务是“提示分类”(prompt classification)还是“响应分类”(response classification)。通过指令措辞的简单改变,同一个模型就能处理这两个语义上不同的任务。
- 对话内容 (The conversation):指令包含需要被评估的对话回合,可以是单轮或多轮。
- 输出格式 (Output format):指令规定了模型必须遵循的输出格式。Llama Guard 的输出包含两部分:首先判断为“safe”或“unsafe”;如果为“unsafe”,则需在下一行指出违反的具体风险类别代码(如 O1, O2)。这种格式同时支持二元分类和多标签分类。
下图展示了 Llama Guard 的提示分类和响应分类任务的指令示例:

创新点
- LLM 作为审核器:使用强大的 Llama2-7b 模型作为基础,替代了传统的小型分类模型,利用了LLM更强的语言理解和推理能力。
- 高度可定制性:通过将安全分类体系作为模型输入的一部分,用户可以在不重新训练模型的情况下,通过零样本(zero-shot)或少样本(few-shot)提示来适应新的安全策略。用户只需在推理时更改指令中的指南描述即可。
- 统一模型,区分角色:首次仅通过更改指令文本,就在单个模型中实现了对用户提示和AI响应的区分评估,无需为两个任务维护不同模型,大大简化了部署。
- 开放与可扩展:本文公开了 Llama Guard 的模型权重,允许研究者和开发者自由使用、微调,以满足特定的安全需求,摆脱了对付费和有速率限制的API的依赖。
模型与训练
- 基础模型:Llama Guard 基于 Llama2-7b 模型构建,选择最小尺寸主要是为了便于用户部署和降低推理成本。
- 数据集:利用 Anthropic 的无害性人类偏好数据作为起点,通过内部 Llama 模型生成响应,并由内部专家红队(red team)依据本文定义的6类风险分类体系(见下表)进行标注。最终数据集包含 13,997 个提示和响应样本。
| 类别 | 提示数 | 响应数 |
|---|---|---|
| 暴力与仇恨 | 1750 | 1909 |
| 性相关内容 | 283 | 347 |
| 犯罪策划 | 3915 | 4292 |
| 枪支与非法武器 | 166 | 222 |
| 受管制或管制物品 | 566 | 581 |
| 自杀与自残 | 89 | 96 |
| 安全 | 7228 | 6550 |
- 训练细节:模型在8个A100 80GB GPU上训练了约1个epoch。为了增强模型的泛化能力,训练中使用了数据增强技术,如在输入指令中随机丢弃未被违反的风险类别,或丢弃所有被违反的类别并将标签改为“safe”,以训练模型仅依赖指令中提供的类别进行判断。
实验结论
本文通过在一系列公开和内部数据集上的实验,验证了 Llama Guard 的性能和适应性。
关键实验结果
- 在自有测试集上表现卓越:在与自身分类体系对齐的测试集上,Llama Guard 的性能远超现有的内容审核API(如 OpenAI Moderation API 和 Perspective API)。无论是在整体二元分类还是各风险子类的评估上,都表现出非常高的准确率(AUPRC 分数达到0.945-0.953)。
| 提示分类 | 响应分类 | |||
|---|---|---|---|---|
| 自有测试集 (提示) | OpenAI Mod | ToxicChat | 自有测试集 (响应) | |
| Llama Guard | 0.945 | 0.847 | 0.626 | 0.953 |
| OpenAI API | 0.764 | 0.856 | 0.588 | 0.769 |
| Perspective API | 0.728 | 0.787 | 0.532 | 0.699 |
- 强大的跨策略适应能力:
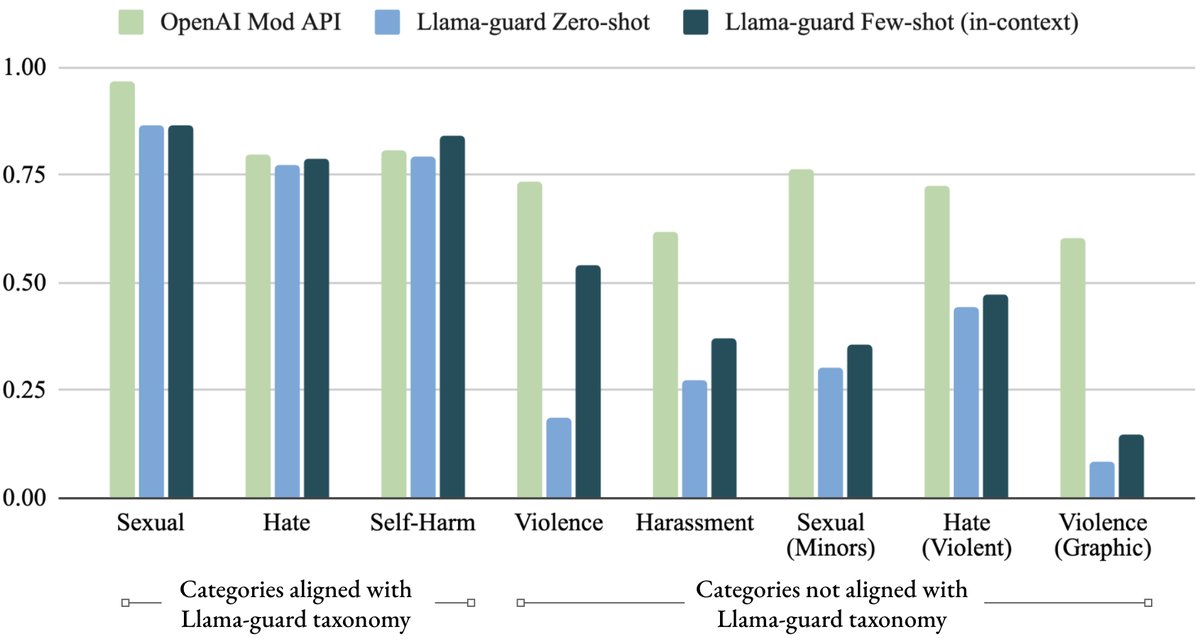
- 零样本适应:在未经过任何针对性训练的情况下,Llama Guard 在 ToxicChat 数据集上的表现优于所有基线。在 OpenAI Moderation 数据集上,其零样本性能也与专门为此数据集训练的 OpenAI Moderation API 相当。
- 少样本适应:通过在推理提示中加入少量(2-4个)与目标分类体系相关的示例(in-context examples),Llama Guard 在 OpenAI Moderation 数据集上的性能甚至超越了 OpenAI 自己的工具。这证明了其通过提示进行低成本、高效适应的能力。
| 方法 | AUPRC |
|---|---|
| OpenAI Mod API (基线) | 0.856 |
| Llama Guard (无适应) | 0.837 |
| Llama Guard 零样本 (使用OpenAI分类体系) | 0.847 |
| Llama Guard 少样本 (使用描述和上下文示例) | 0.872 |
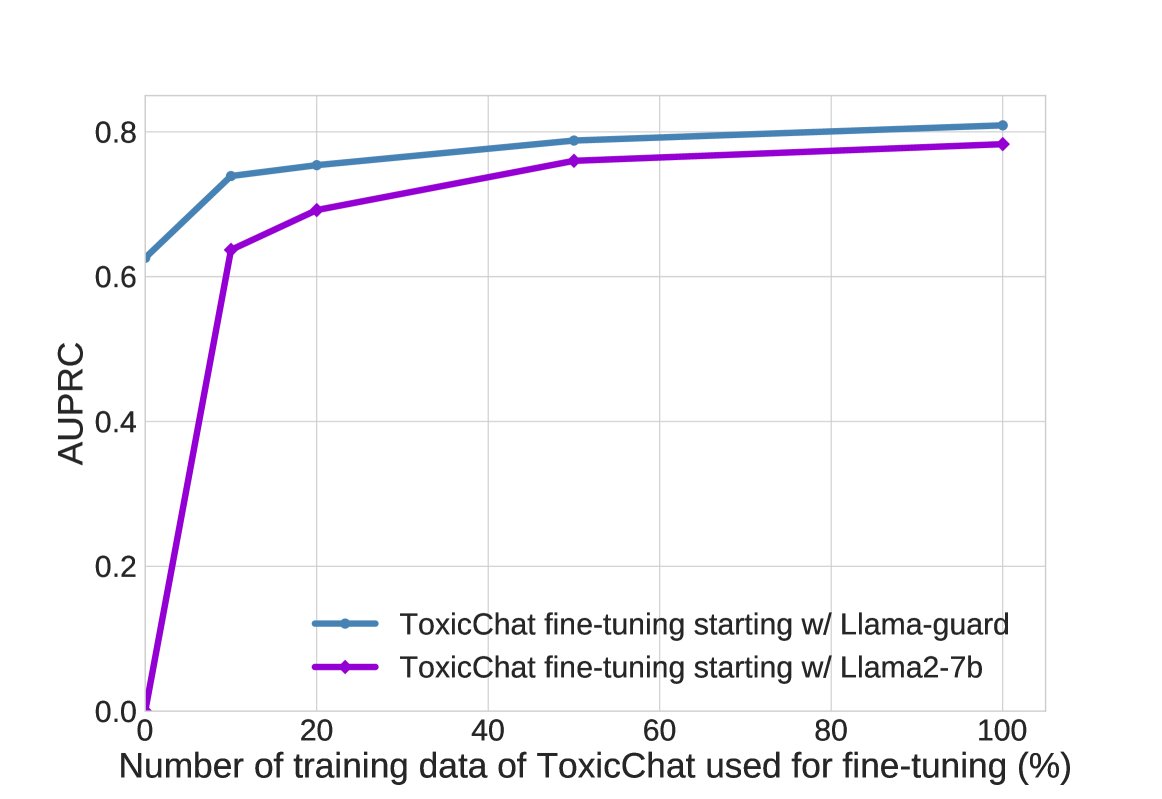
- 微调适应的高效性:实验证明,对 Llama Guard 进行微调以适应新的数据集(如 ToxicChat)比从头开始微调 Llama2-7b 模型要高效得多。Llama Guard 仅需使用 20% 的 ToxicChat 训练数据,就能达到 Llama2-7b 使用 100% 数据训练后的性能水平,这表明 Llama Guard 的初始安全训练为后续适应新任务提供了极好的起点。
总结
实验结果有力地证明,Llama Guard 不仅在其原生安全策略上表现出色,更重要的是,它具备前所未有的适应性。无论是通过零样本/少样本提示,还是通过高效的微调,Llama Guard 都能快速、低成本地适应新的安全需求和分类体系,使其成为一个强大且灵活的开源内容安全解决方案。