Loong: Synthesize Long Chain-of-Thoughts at Scale through Verifiers
-
ArXiv URL: http://arxiv.org/abs/2509.03059v1
-
作者: Zhaowei Wang; Bowen Li; Ziyang Wang; Bernard Ghanem; Yifan Wu; Guohao Li; Jinhe Bi; Fangru Lin; Hao Sun; Yunpu Ma; 等38人
-
发布机构: CAMEL-AI.org
TL;DR
本文提出了Loong项目,一个旨在通过人工审查的种子数据集(LoongBench)和模块化的合成环境(LoongEnv),大规模生成跨多个推理领域、可自动验证的长链思维(Chain-of-Thoughts)数据,以解决高质量训练数据稀缺的问题,并为基于可验证奖励的强化学习(RLVR)提供支持。
关键定义
- Loong项目 (Loong Project):一个用于在多个推理密集型领域大规模生成合成数据并进行验证的开源框架。它旨在通过自动化流程克服高质量数据集稀缺的瓶颈,为训练和对齐大型语言模型提供支持。
- LoongBench:一个由人工审查的高质量种子数据集,包含12个推理密集型领域的8,729个样本。每个样本均包含自然语言问题、可执行的Python代码(作为推理过程)以及经过代码执行验证的最终答案。它是数据合成过程的起点。
- LoongEnv:一个模块化的合成数据生成环境。它利用LoongBench中的种子样本,通过多种提示策略(如Few-shot、Self-Instruct、Evol-Instruct)生成新的、结构更多样、难度更高的问题-代码-答案三元组。
- 智能体-环境循环 (Agent-Environment Loop):Loong项目的核心工作流。首先,数据生成器产生合成问题和可执行的解决方案代码;其次,代码被执行以获得可信的答案;然后,一个待训练的智能体(LLM)尝试解决该问题;最后,验证器比对智能体的答案与代码执行结果,为强化学习提供奖励信号。
- 可验证奖励强化学习 (Reinforcement Learning with Verifiable Reward, RLVR):一个沿用并作为本文核心动机的已有概念。其核心思想是,使用可自动验证的奖励信号(如代码执行结果)来训练模型,而不是依赖昂贵且主观的人工标注。Loong框架旨在为RLVR提供大规模、高质量的训练数据。
相关工作
目前,利用可验证奖励的强化学习(RLVR)已显著提升了大型语言模型(LLM)在数学和编程等领域的推理能力。这些领域的成功得益于两个关键因素:1)答案的正确性可以被轻松地自动验证(例如通过代码执行);2)存在大量高质量、已验证的训练数据集。
然而,许多其他同样需要复杂推理能力的领域,如逻辑学、图论、物理学和金融学,普遍面临着高质量、可验证数据集严重不足的瓶颈。由于人工标注成本极高,为这些领域大规模创建训练数据变得不切实际。这限制了模型在这些领域学习特定推理模式的能力。
本文旨在解决的核心问题是:如何在数学和编程之外的、缺乏大规模标注数据的推理领域中,实现与数学和编程领域相媲美的模型推理性能? 其解决方案是构建一个能够以低成本、可扩展的方式,自动生成大量高质量、可验证的训练数据的框架。
本文方法
本文提出了Loong项目,一个旨在通过合成数据生成和可验证奖励来对齐LLM的模块化框架。其核心思想是:配备代码解释器的LLM在解决复杂问题时,通常比仅依赖自然语言推理的LLM更可靠。 该框架主要由LoongBench(种子数据集)和LoongEnv(合成环境)两个核心组件构成。
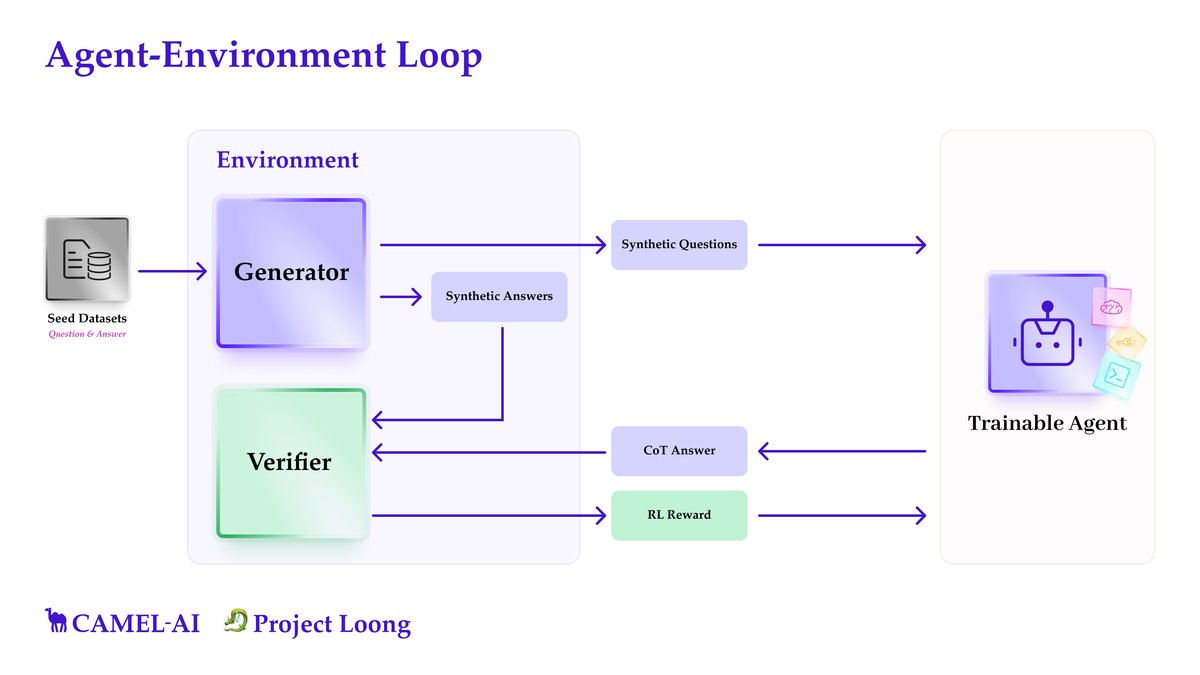
上图展示了Loong项目的智能体-环境循环。首先,生成器利用种子数据创建合成问题及对应的可执行代码。然后,代码被执行以生成可验证的答案。接着,一个待训练的智能体(LLM)被要求通过生成自然语言思维链(CoT)来解决这些问题。最后,一个验证器比较智能体的答案和代码生成的答案,这个比对结果可以作为强化学习的奖励信号。
LoongBench:跨领域的人工审查种子数据集
LoongBench是一个包含8,729个高质量样本的种子数据集,覆盖12个推理密集型领域。它的目的不是直接用于大规模训练,而是作为引导LLM生成合成数据的起点。
数据点结构:
- 自然语言问题。
- 经验证的最终答案。
- 作为推理过程的可执行Python代码。
- 相关的元数据(如来源、领域、难度、依赖库等)。
领域与规模:
| 领域 | 主要依赖库 | 规模 |
|---|---|---|
| 高等数学 (Advanced Maths) | sympy | 1,611 |
| 高等物理 (Advanced Physics) | sympy, numpy | 429 |
| 化学 (Chemistry) | rdkit, numpy | 3,076 |
| 计算生物学 (Computational Biology) | - | 51 |
| 金融 (Finance) | QuantLib | 235 |
| 棋盘游戏 (Board Game) | - | 926 |
| 图与离散数学 (Graph & Discrete Maths) | networkx | 178 |
| 逻辑 (Logic) | python-constraint | 130 |
| 数学规划 (Mathematical Programming) | gurobipy, cvxpy, pyscipopt, statsmodel | 76 |
| 医学 (Medicine) | medcalc-bench | 916 |
| 安全 (Security & Safety) | cryptography, gmpy2, pycryptodome | 516 |
| 编程 (Programming) | - | 585 |
数据收集示例:
- 高等数学:从MATH数据集中筛选高难度问题,利用o3-mini模型生成SymPy解题代码,并通过MathVerifier工具验证代码结果与标准答案的一致性。
- 图与离散数学:从\(networkx\)库的官方文档中提取代码示例,利用GPT-4o-mini将代码功能改写为具体的图论问题。
- 安全:从CTF-Wiki中手动整理加密学挑战题目,并利用GPT-4o生成题目变体和完善解题代码。
- 其他领域:均采用类似方法,结合领域特定资源(如Scibench、QuantLib、MedCalc-Bench)和LLM辅助,生成带有可执行代码的问题。
LoongEnv:模块化的合成数据生成环境
LoongEnv是一个灵活的合成数据生成器,它接收LoongBench的种子数据,旨在生成数量庞大且可控的训练数据。
问题合成策略: LoongEnv支持多种策略来从种子样本生成新问题:
- 少样本提示 (Few-shot prompting):将少量种子样本作为示例,提示模型生成类似风格的新问题。
- 自指令 (Self-Instruct):通过递归提示,让模型生成更多样化、结构更复杂的指令/问题。
- 进化指令 (Evol-Instruct):通过对种子问题进行变异操作(如泛化、具体化、增加复杂性)来“进化”出新问题。
答案合成与验证:
- 答案合成:对于每个合成的问题,一个“编码器智能体”会生成相应的Python代码,并通过执行代码得到结果。
- 验证器 (Verifiers):为确保合成数据的质量,框架引入了验证机制。通过比较两种独立方法得出的答案来确认正确性:1)生成器自己执行代码得出的答案;2) 另一个独立的LLM通过自然语言CoT推理得出的答案。如果两者一致,则认为该答案可信。这种机制旨在减少错误,并为后续的RL训练提供可靠的奖励信号。
未来方向: 该框架的最终目标是支持可验证奖励的强化学习 (RLVR)。智能体生成的答案只有在通过验证器确认与可信的合成答案语义一致时,才能获得正向奖励。
实验结论
本文通过实验评估了当前SOTA模型在LoongBench上的表现,并分析了LoongEnv生成合成数据的质量。
LoongBench 基准测试
在LoongBench上对一系列开源和闭源模型进行了测试,主要发现如下:
| 领域 | GPT4.1-mini | o3-mini | Grok-3 | Claude-3.7 | DeepSeek-r1 | Qwen3-8B |
|---|---|---|---|---|---|---|
| 高等数学 | 91.4 | 97.4 | 92.3 | 79.3 | 96.7 | 79.2 |
| 高等物理 | 71.8 | 75.3 | 69.0 | 63.9 | 77.4 | 59.2 |
| 化学 | 75.2 | 79.5 | 71.2 | 80.7 | 74.7 | 79.7 |
| 计算生物学 | 90.2 | 88.2 | 96.1 | 90.2 | 88.2 | 86.2 |
| 金融 | 23.8 | 24.3 | 19.1 | 22.0 | 24.3 | 12.8 |
| 游戏 | 92.0 | 96.0 | 93.0 | 95.1 | 97.3 | 43.2 |
| 图论 | 80.9 | 82.0 | 80.1 | 73.6 | 83.7 | 62.9 |
| 逻辑 | 65.4 | 61.6 | 55.4 | 46.9 | 62.3 | 39.2 |
| 数学规划 | 11.8 | 9.2 | 6.4 | 13.2 | 10.5 | 10.0 |
| 医学 | 59.6 | 46.3 | 50.7 | 54.1 | 52.6 | 28.4 |
| 安全 | 25.6 | 11.2 | 22.3 | 4.7 | 28.7 | 7.9 |
| 编程 | 98.6 | 100.0 | 91.5 | 97.4 | 98.8 | 81.7 |
核心结论:
- 难度分布合理:LoongBench覆盖了从简单(如编程,准确率接近100%)到极具挑战性(如数学规划,准确率仅10%左右)的多个领域,使其成为一个有区分度的基准。
- 推理优化模型表现优异:专为推理任务优化的模型(如o3-mini和DeepSeek-r1)在大多数领域中表现最佳,证明了该基准能有效评估模型的多步结构化推理能力。
- 开源模型仍有差距:在策略性和逻辑性要求高的领域(如游戏、逻辑),开源模型(如Qwen3-8B)与顶尖闭源模型之间仍存在显著性能差距。
LoongEnv 合成数据分析
通过三种策略(Few-shot、Self-Instruct、Evol-Instruct)生成合成数据,并从正确性、多样性和难度三个维度进行分析。
正确性与可靠性
- Few-shot 策略最可靠,生成的代码执行成功率和验证通过率最高。
- Evol-Instruct 策略的可靠性最低,产生了大量无法执行或被“裁判”拒绝的代码。
- 结论:简单策略可靠性高,但复杂策略(Evol-Instruct)虽然失败率高,却能生成更具挑战性的任务,对训练更鲁棒的模型有重要价值。
多样性

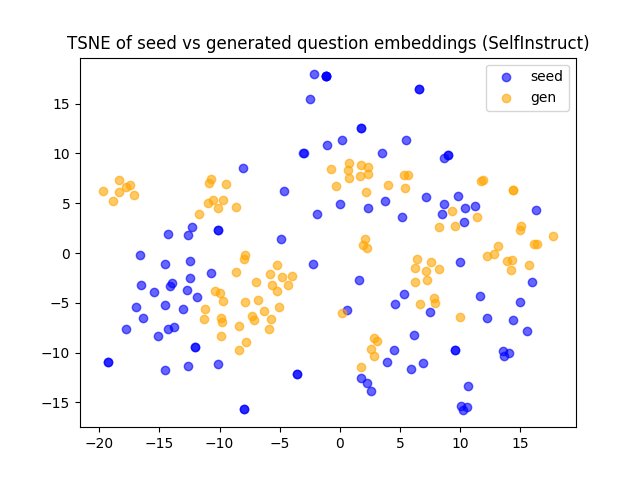
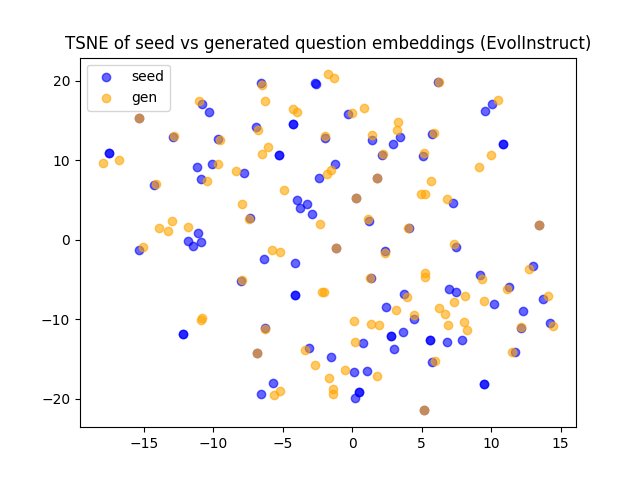
- Few-shot 生成的问题在词汇上与种子问题差异较大,但语义和结构上仍很接近。
- Self-Instruct 生成的问题在语义上漂移较大,更具新颖性。
- Evol-Instruct 生成的问题在语义上与种子问题高度相似(高余弦相似度),但在结构和复杂性上有所提升。这表明它倾向于在保留核心语义的同时增加推理难度。
难度
| 模型 | Few-shot | Self-Instruct | Evol-Instruct | 种子数据集 |
|---|---|---|---|---|
| GPT4.1-mini | 92.0 $\uparrow$ | 83.0 $\uparrow$ | 62.0 $\downarrow$ | 71.8 |
| DeepSeek-r1 | 93.2 $\uparrow$ | 87.4 $\uparrow$ | 70.3 $\downarrow$ | 77.4 |
- 在合成的高等物理问题上,所有模型在Evol-Instruct生成的数据上准确率最低,显著低于在种子数据集上的表现。
- 结论:Evol-Instruct 确实能够生成比原始种子数据更难、推理更复杂的问题,这验证了其作为一种有效的数据增强策略的潜力,能够帮助模型学习更深层次的推理模式。
最终结论: 本文提出的Loong框架成功地构建了一个可扩展的、用于生成高质量可验证合成数据的系统。实验证明,该框架生成的LoongBench数据集能有效评估模型的跨领域推理能力,而LoongEnv环境则能生成多样且具有挑战性的新数据,为未来应用RLVR来提升LLM的通用推理能力铺平了道路。