MAPEX: A Multi-Agent Pipeline for Keyphrase Extraction
-
ArXiv URL: http://arxiv.org/abs/2509.18813v2
-
作者: Qicheng Li; Shiwan Zhao; Aobo Kong
-
发布机构: Nankai University
TL;DR
本文提出了MAPEX,一个用于关键词提取的多智能体协作框架,它通过为不同长度的文档设计动态的双路径策略(知识驱动与主题引导),显著提升了大型语言模型(LLM)在零样本场景下的关键词提取性能。
关键定义
本文提出或沿用了以下关键概念:
- 多智能体协作 (Multi-Agent Collaboration):一种系统设计范式,其中多个独立的智能体(Agents)通过协作完成复杂任务。在本文中,框架由专家招募官、候选词提取器和领域专家三个智能体协同工作。
- 双路径策略 (Dual-Path Pipeline Strategy):针对不同长度的文档采用不同处理流程的核心机制。
- 知识驱动提取 (Knowledge-driven extraction):为短文本设计的路径。通过从外部知识库(如维基百科)检索信息,来增强对候选关键词的语义理解。
- 主题引导提取 (Topic-guided extraction):为长文本设计的路径。通过首先识别文档的核心主题,来指导后续的关键词重排序和筛选过程,以应对长文本中的语义稀释问题。
- 专家招募 (Expert Recruitment):框架中的一个特定模块,由“专家招募官”智能体负责。该智能体分析文档内容,并为“领域专家”智能体动态分配合适的专家角色(如“计算机图形学专家”),从而使提取过程更具领域针对性。
相关工作
当前的无监督关键词提取技术主要分为传统方法(统计、图、嵌入)和基于语言模型的提示(prompt-based)方法。随着大型语言模型(LLM)的兴起,基于提示的方法成为主流。然而,现有方法普遍存在一个关键瓶颈:它们大多采用单一、固定的推理流程和提示策略,不区分文档长度或底层LLM模型。这种“一刀切”的设计无法充分发挥LLM在处理多样化场景时的推理和生成潜力,限制了其在关键词提取任务上的泛化能力。
本文旨在解决上述问题,即如何设计一个更灵活、更强大的框架,以充分利用LLM的能力,特别是应对不同长度文档带来的挑战,从而提升零样本关键词提取的准确性和鲁棒性。
本文方法
本文提出了一个名为MAPEX(Multi-Agent Pipeline for Keyphrase Extraction)的多智能体流水线框架。该框架通过三个智能体和一个根据文档长度动态选择的双路径策略来协同工作。
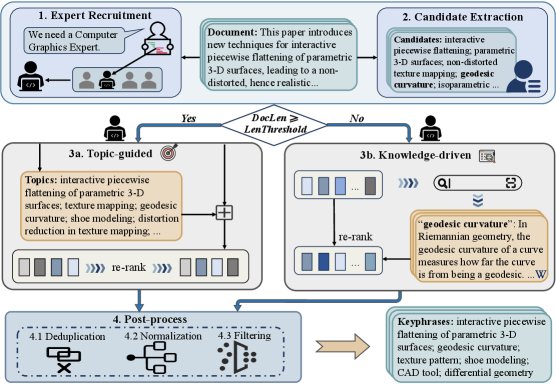
智能体角色与分工
MAPEX框架包含三个协同工作的智能体,其行为通过精心设计的提示(prompt)进行引导。
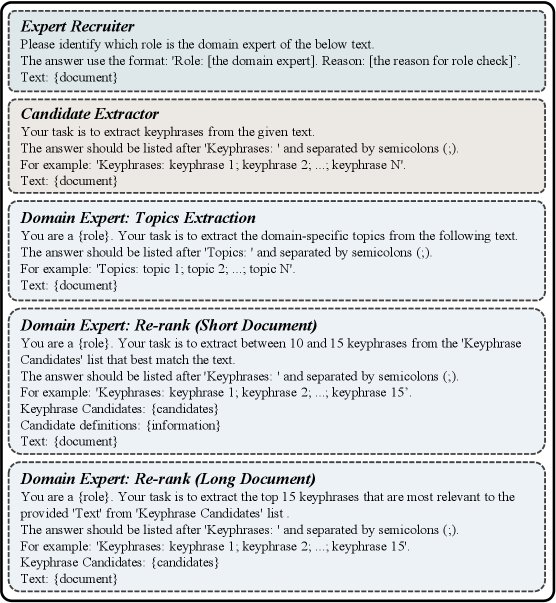
- 专家招募官 (Expert Recruiter):此智能体首先分析文档内容,以确定其所属的专业领域。随后,它为“领域专家”智能体分配合适的专家角色(例如,“软件工程师”),并提供分配理由。这使得后续的提取过程更具专业视角。
- 候选词提取器 (Candidate Extractor):此智能体负责从原始文档中生成一个广泛的候选关键词池。它不被赋予任何特定角色,目的是为了确保初始候选集的多样性,避免因专家角色的局限性而遗漏重要的词汇变体。
核心创新:双路径策略
为了有效处理不同长度的文档,MAPEX引入了一个长度阈值 \(ℓ\),并根据该阈值将文档分派到两条不同的处理路径。这一设计的核心动机是:外部知识对于短文本的语义补充效果显著,但对于长文本,由于上下文窗口限制和语义稀释,其优势会减弱。
-
长文本路径(主题引导): 当文档长度 $$ d_i ≥ ℓ$$ 时,激活此路径。 - 领域专家 (Domain Expert) 首先识别并生成一系列代表文档核心思想的显著主题(topic)。
- 这些主题与“候选词提取器”生成的候选词合并。
- 最后,领域专家对这个增强后的候选列表进行重新排序和筛选,生成初步的关键词列表。
-
短文本路径(知识驱动): 当文档长度 $$ d_i < ℓ$$ 时,激活此路径。 - 为了弥补短文本上下文信息的不足,“领域专家”会为每个候选关键词 $c_{ij}$ 调用外部知识检索工具(如\(WikiQuery\))来获取其定义和背景信息。
-
所有候选词的外部知识被聚合成一个知识字典:
\[W_i = \bigcup_{c \in C_i} \mathrm{WikiQuery}(c)\] - 基于这些增强的知识,“领域专家”对候选词进行重排序,输出初步的关键词列表。
后处理
在“领域专家”生成初步结果后,框架会执行一个后处理步骤以提升最终输出的质量。该步骤包含三个子任务:
- 移除冗余:删除重复的短语。
- 标准化:统一处理缩写词及其全称。
- 过滤幻觉:移除未在原文中出现的短语,确保所有关键词均源于文本。
优点
- 自适应性:双路径策略使模型能够根据文档长度自动选择最优处理方式,解决了“一刀切”方法的局限性。
- 专业性:专家招募机制引入了领域视角,使关键词提取更贴合文本的专业背景。
- 鲁棒性:通过通用候选词提取与专家筛选相结合,扩大了候选范围并保证了最终质量。
- 高保真度:后处理步骤有效抑制了LLM的“幻觉”现象,确保了关键词的准确性和来源可靠性。
实验结论
整体性能
实验在Inspec、SemEval-2010等六个基准数据集上进行,并使用了Mistral-7B、Qwen2-7B等三种不同的LLM作为底层模型。
| 方法 | 模型 | Inspec | SemEval-10 | SemEval-17 | DUC-2001 | NUS | Krapivin | 平均 |
|---|---|---|---|---|---|---|---|---|
| 传统无监督 | ||||||||
| SIFRank | - | 35.15 | 29.56 | 38.38 | 26.68 | 27.69 | 22.09 | 30.03 |
| MDERank | - | 36.31 | 30.13 | 42.17 | 27.35 | 29.80 | 25.12 | 31.81 |
| PromptRank | BART | 39.56 | 32.55 | 45.34 | 31.33 | 30.65 | 27.48 | 34.49 |
| LLM 基线 | ||||||||
| Base | Mistral-7B | 37.98 | 29.59 | 42.16 | 28.52 | 27.91 | 25.26 | 31.90 |
| Hybrid | Mistral-7B | 38.45 | 30.11 | 42.94 | 29.07 | 28.98 | 26.17 | 32.62 |
| MAPEX (本文) | Mistral-7B | 40.31 | 32.88 | 45.92 | 30.64 | 33.34 | 28.75 | 35.31 |
| (其他LLM结果) | … | … | … | … | … | … | … | … |
- 超越SOTA:结果显示,MAPEX在所有LLM和数据集上都显著优于基线方法。以Qwen2.5-7B为骨干时,其平均F1@5得分达到24.30%,比之前最先进的无监督方法PromptRank(22.81%)高出2.44%。
- 提升LLM性能:与标准的LLM基线(Base)相比,MAPEX为所有底层LLM带来了显著增益。例如,它将Mistral-7B模型的平均F1@5得分从18.23%提升至22.24%,增幅达4.01%。
- 长文本优势:MAPEX在长文档数据集(如NUS)上表现尤为出色,绝对F1@5提升高达5.22%,证明了主题引导策略的有效性。
消融研究
为了验证各模块的贡献,本文在Mistral-7B模型上进行了消融研究。
- 各模块均有效:从最基础的“候选词提取”,逐步加入“专家角色”、“主题/知识分支”和“后处理”,每一步都带来了性能提升。这证明了MAPEX框架中每个组件都起到了积极作用。
- 专家角色对长文本数据集的提升更明显;主题和知识分支无论在哪种情况下都贡献了显著的性能增益;后处理进一步优化了结果的准确性。
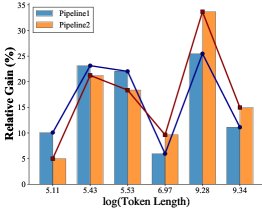 (a) 相对基线的性能增益
(a) 相对基线的性能增益
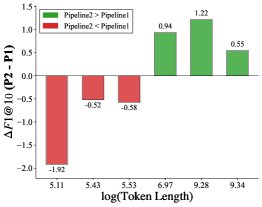 (b) 知识驱动与主题引导路径的性能差异
(b) 知识驱动与主题引导路径的性能差异
- 路径选择阈值的合理性:通过分析不同长度文本上两条路径的性能表现,实验发现了一个明显的性能交叉区域(上图b)。知识驱动路径在短文本上相对优势更大(上图a中的蓝线),而主题引导路径在长文本上表现更优。本文选择的长度阈值 \(ℓ = 512\) tokens(约等于\(ln(length) ≈ 6.24\))正位于该交叉区域的中心,经验证是一个合理的选择。
最终结论
本文提出的MAPEX框架通过引入多智能体协作和动态双路径策略,成功地解决了传统LLM方法在关键词提取任务中的“一刀切”问题。实验证明,该框架具有强大的泛化能力和通用性,在多个LLM上均取得了超越现有SOTA方法的性能,尤其在处理复杂和长篇文档时表现稳健。