MARS: Optimizing Dual-System Deep Research via Multi-Agent Reinforcement Learning
-
ArXiv URL: http://arxiv.org/abs/2510.04935v1
-
作者: Yong Jiang; Xuanzhong Chen; Hao Sun; Wayne Xin Zhao; Minpeng Liao; Donglei Yu; Wenqing Wang; Fei Huang; Kai Fan; Zile Qiao; 等12人
-
发布机构: Alibaba Group; Renmin University of China
TL;DR
本文提出了一种名为 MARS 的双系统多智能体强化学习框架,该框架通过模拟人类认知的双系统(系统1的快速直觉与系统2的审慎推理),让两个智能体协同解决需要外部知识的复杂推理任务,显著提升了模型在动态信息环境下的深度研究和推理能力。
关键定义
本文的核心是构建一个模拟人类认知双系统的框架,主要沿用并扩展了以下概念:
- 双系统框架 (Dual-System Framework):受人类认知双重过程理论的启发,本文将大型语言模型(LLM)的功能拆分为两个协同工作的系统。
- 系统1 (System 1):负责快速、直觉式的思考。在 MARS 框架中,它被专门用于高效处理和总结外部工具(如搜索引擎)返回的大量、可能嘈杂的信息,将其提炼为简洁的要点。
- 系统2 (System 2):负责缓慢、审慎的推理。在 MARS 框架中,它主导整个推理过程,进行规划、生成复杂的推理步骤,并决定何时、如何调用外部工具来获取信息或执行计算。
- 多智能体强化学习 (Multi-Agent Reinforcement Learning, MARL):本文将系统1和系统2视为两个独立的智能体,它们在同一个基础LLM上通过不同提示(Prompt)激活。本文采用一种多智能体强化学习方法,对这两个智能体进行协同优化,以最大化它们共同完成任务的最终奖励。
相关工作
当前,大型推理模型(Large Reasoning Models, LRMs)在处理复杂问题时表现出色,但解决简单问题时常出现“过度分析”倾向,导致不必要的Token消耗。同时,所有大型语言模型都受限于其预训练数据的截止日期,难以适应快速变化的环境和获取最新知识。
虽然检索增强生成(Retrieval-Augmented Generation, RAG)技术通过引入外部知识源缓解了知识过时的问题,但现有RAG系统面临两大瓶颈:1)在处理多个长篇文档(如完整网页或研究论文)时,容易出现“信息过载”;2)为了避免过载而对信息进行压缩时,又可能丢失关键细节。
本文旨在解决上述问题,即如何在不牺牲推理深度和不造成信息过载的前提下,高效地利用海量、动态的外部信息来增强复杂推理能力。
本文方法
本文提出了一个名为MARS(Multi-Agent System for Deep Research)的深度研究多智能体系统。其核心是一个创新的双系统协作框架,并通过专门的多智能体强化学习策略进行端到端优化。
双系统协作框架
MARS框架将系统1的直觉处理能力与系统2的审慎推理能力整合在同一个LLM中,并通过不同的提示来激活。两者通过一个清晰定义的协作流程解决复杂问题。
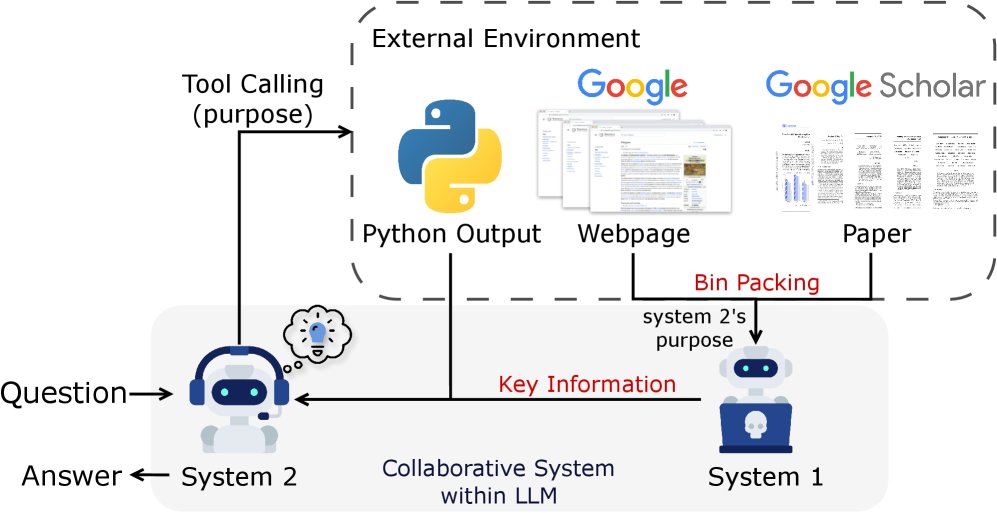
该协作流程可以形式化为多轮交互:
-
系统2进行推理与规划:在第 $i$ 轮,系统2($\pi_{\text{sys}_2}$)根据当前上下文 $c_i$(包含初始问题和之前轮次信息),生成推理步骤 $s_i$,并可能生成一个工具调用请求(包含工具参数 $t_i$ 和调用目的 $p_i$)。
\[s_i, (t_i, p_i) = \pi_{\text{sys}_2}(c_i)\] - 外部工具执行:如果 $t_i$ 存在,外部环境(如Google搜索)执行该调用,返回原始输出 $o_{t_i}$。
-
系统1处理信息:系统1($\pi_{\text{sys}_1}$)根据系统2提供的“目的” $p_i$,处理海量的原始输出 $o_{t_i}$,将其提炼为简洁有效的信息 $\tilde{o}_{t_i}$。
\[\tilde{o}_{t_i} = \pi_{\text{sys}_1}(\text{Bin-Packing}(o_{t_i}^{(1)}, \dots, o_{t_i}^{(n_{t_i})}), p_i)\] -
上下文更新:将本轮的推理、工具调用和提炼后的信息整合,更新上下文,为下一轮做准备。
\[c_{i+1} = c_i \oplus \{s_i, t_i, p_i, \tilde{o}_{t_i}\}\]
这个过程迭代进行,直到系统2认为可以生成最终答案。
创新点
本文方法的主要创新之处在于明确的劳动分工和协同优化:
- 专业化分工:系统2专注于高级的、全局性的推理和策略规划,而将繁琐、耗时的大规模信息处理任务卸载给系统1。这使得系统2的上下文窗口不会被原始信息淹没,从而能够处理更全面、更深入的信息,提升了推理的广度和深度。
- 协同增效:通过“目的” $(p_i)$ 这一桥梁,系统1可以精确地理解系统2的需求,进行有针对性的信息提炼。这种设计使得两个系统各司其职,形成了一个高效且稳健的解决问题的闭环。
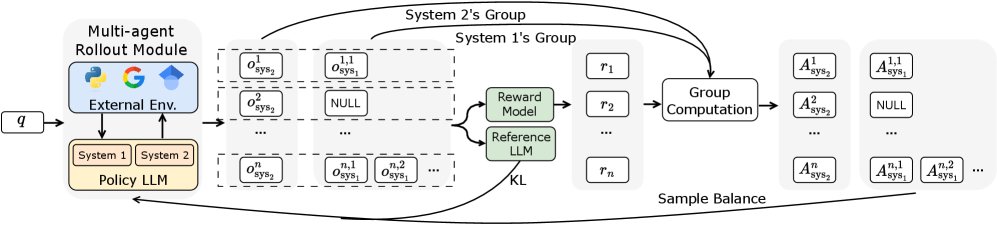
双系统优化策略
为了实现端到端的训练,本文提出了一套基于多智能体强化学习的优化策略,扩展了GRPO(Group Relative Policy Optimization)算法。
用装箱算法高效处理内容
系统1在处理工具返回的大量可变长度文本时,为提升并行处理效率,本文采用了基于首次适应递减(First Fit Decreasing, FFD)算法的装箱(Bin-Packing)策略。该策略将不定长的文本块高效地组织成大小最优的批次,减少了系统1生成摘要所需的总次数。
优势预计算与平衡采样机制
在训练中,一次推理轨迹(trajectory)会产生1个系统2样本和多个(取决于工具调用次数)系统1样本,导致样本数量严重不平衡。为解决此问题,本文提出:
-
优势预计算:首先,对一次批次中产生的所有系统1和系统2的样本,分别在各自的组内进行奖励归一化,并计算优势函数(Advantage)。
\[A_{\text{sys}_2}^{k} = \frac{r_{\text{sys}_2}^{k}-\text{mean}(\mathbf{r}_{\text{sys}_2})}{\text{std}(\mathbf{r}_{\text{sys}_2})}, \quad A_{\text{sys}_1}^{k,j} = \frac{r_{\text{sys}_1}^{k,j}-\text{mean}(\mathbf{r}_{\text{sys}_1})}{\text{std}(\mathbf{r}_{\text{sys}_1})}\] -
平衡采样:计算完所有样本的优势后,再对数量过多的系统1样本进行随机降采样(或对数量不足的进行上采样),使其数量与系统2的样本数对齐。这种“先计算后采样”的方式确保了优势分布的统计完整性。
多智能体训练目标
通过平衡采样后,系统1和系统2使用扩展的GRPO框架进行联合优化。总损失函数为两个系统损失之和:
\[\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{sys}_2} + \mathcal{L}_{\text{sys}_1}\]每个系统的损失均遵循GRPO目标函数,该函数包含一个策略损失项和一个KL散度正则化项,以确保在学习新策略的同时不过于偏离原始模型。
实验结论
本文在极具挑战性的HLE(Humanity’s Last Exam)基准和7个知识密集型问答任务上进行了广泛实验。
主要结果
- HLE基准表现:在HLE上,MARS的性能超越了所有其他开源模型,包括基于更大参数模型的WebThinker和C-3PO,取得了3.86%的显著提升。这证明了双系统范式在仅使用7B/8B级别模型的情况下,能有效提升复杂推理能力,显著缩小了与顶级闭源模型的差距。
| 模型 | 总体(%) | 数学 | 物理 | 化学 | 生物/医学 | CS/AI | 人文社科 | 其他 |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-7B-Instruct | 2.51 | 3.51 | 1.97 | 1.83 | 2.89 | 3.12 | 1.70 | 2.65 |
| Qwen3-8B | 3.15 | 4.60 | 3.61 | 2.33 | 3.32 | 3.84 | 1.98 | 2.66 |
| MARS (Qwen2.5-7B) | 6.51 | 10.22 | 4.94 | 5.00 | 6.40 | 6.25 | 3.97 | 5.92 |
| MARS (Qwen3-8B) | 7.38 | 9.92 | 6.25 | 5.50 | 5.94 | 6.25 | 3.72 | 7.51 |
- 知识密集型任务表现:在7个知识密集型任务上,MARS相较于之前的SOTA方法C-3PO,平均取得了8.9%的性能提升。在需要多步推理的multi-hop任务上优势尤为明显,平均提升达12.2%。这表明MARS的框架极大地增强了模型整合多源信息进行复杂推理链的能力。
| 模型 | NQ | TriviaQA | PopQA | HotpotQA | 2Wiki | Musique | Bamboogle | 平均 |
|---|---|---|---|---|---|---|---|---|
| C-3PO | 78.4 | 82.5 | 60.1 | 63.8 | 66.8 | 49.3 | 59.4 | 65.76 |
| MARS | 84.5 | 89.8 | 65.3 | 74.1 | 78.2 | 62.7 | 68.8 | 74.77 |
| 增益 | +6.1 | +7.3 | +5.2 | +10.3 | +11.4 | +13.4 | +9.4 | +8.9 |
过程分析与消融研究
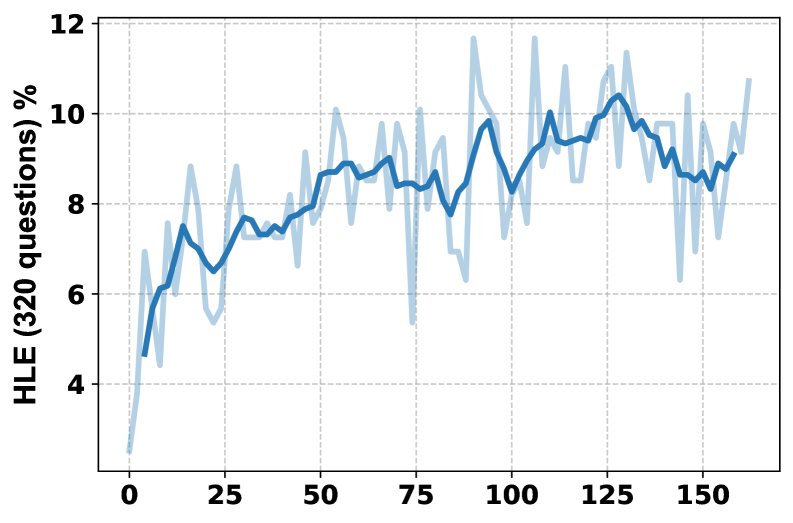
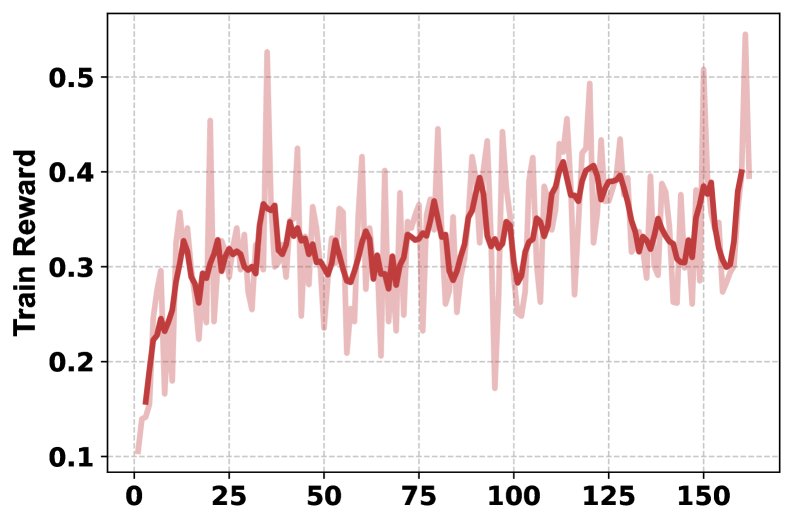
- 训练过程分析:训练曲线显示,随着训练进行,HLE分数稳定提升,模型学会了更频繁地使用多种工具(从每问1次增加到2次以上),且系统1和系统2生成的回复长度也随之增加,表明两个系统都在学习产生更详尽的输出。
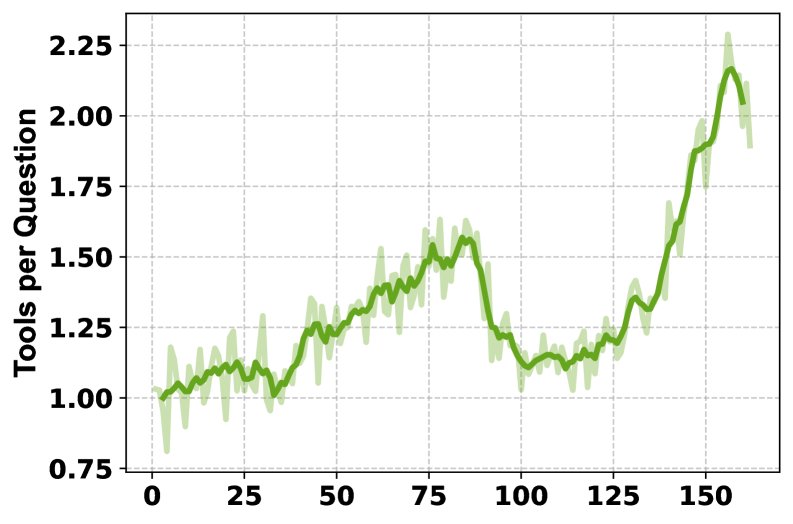

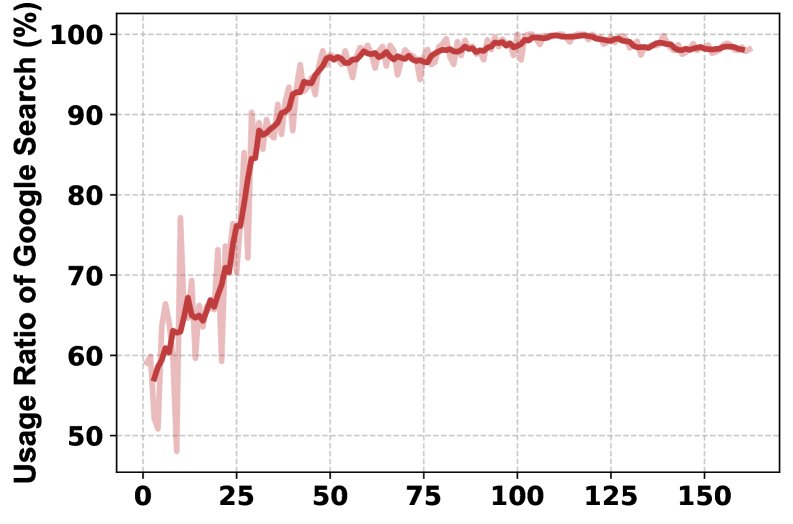

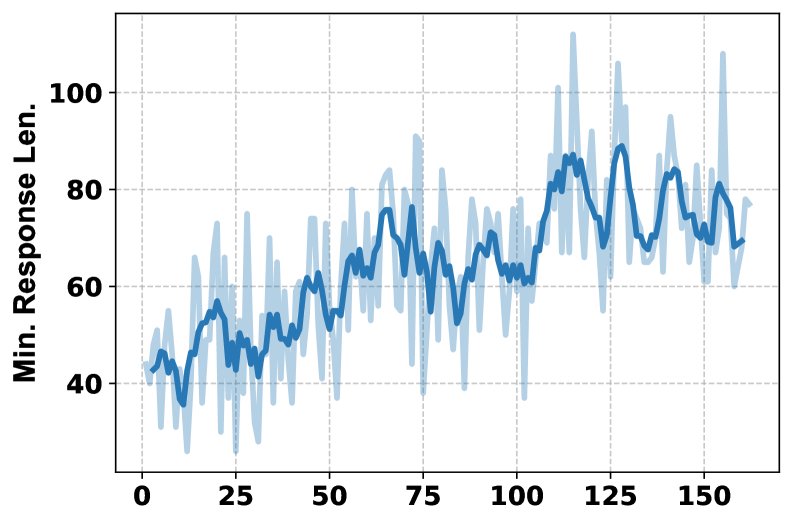
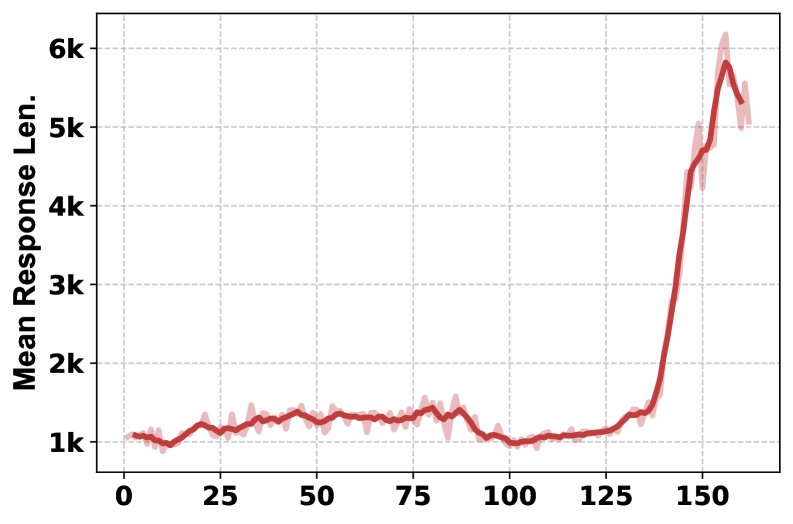
- 消融研究:对工具的消融研究表明,不同工具对不同学科领域的贡献是独特的。移除Python解释器对数学和物理影响最大,而移除Google Scholar对计算机科学影响最大。全功能的MARS(包含所有工具)取得了最佳的综合性能,证明了多工具组合的互补性和必要性。
| 工具 | 总体(%) | 数学 | 物理 | 化学 | 生物/医学 | CS/AI | 人文社科 | 其他 |
|---|---|---|---|---|---|---|---|---|
| All | 7.38 | 9.92 | 6.25 | 5.50 | 5.94 | 6.25 | 3.72 | 7.51 |
| w/o Python | 6.47 | 8.38 | 5.27 | 7.50 | 6.40 | 6.25 | 3.21 | 5.81 |
| w/o Google | 6.00 | 9.07 | 3.30 | 5.50 | 5.48 | 6.25 | 4.22 | 5.81 |
| w/o Scholar | 7.15 | 10.22 | 5.92 | 5.50 | 5.48 | 3.12 | 3.97 | 9.09 |
最终结论
实验结果有力地证明,本文提出的MARS框架通过模拟双系统认知,并结合多智能体强化学习进行优化,能够高效利用海量外部信息,在不牺牲计算效率的前提下,显著提升模型在各类复杂推理任务上的表现。该方法为构建更强大、更高效的AI研究与推理系统提供了有效范式。