MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
-
ArXiv URL: http://arxiv.org/abs/2310.02255v3
-
作者: Michel Galley; Hritik Bansal; Kai-Wei Chang; Jiacheng Liu; Hao Cheng; Tony Xia; Chun-yue Li; Hannaneh Hajishirzi; Jianfeng Gao; Pan Lu
-
发布机构: Microsoft Research; UCLA; University of Washington
TL;DR
本文提出了 MathVista,一个全面的基准测试,旨在系统性地评估基础模型在视觉情境下的数学推理能力,并揭示了即便是最先进的 GPT-4V 模型,其性能也与人类水平存在显著差距。
关键定义
本文为构建 MathVista 基准,建立了一个任务分类体系,其中包含以下关键定义:
- 数学推理类型 (Mathematical Reasoning Types):确定了评估模型所需的七种核心数学推理能力。
- 代数推理 (Algebraic Reasoning):涉及变量、表达式、方程和函数的符号操作。
- 算术推理 (Arithmetic Reasoning):基本的加减乘除计算。
- 几何推理 (Geometry Reasoning):关于形状、大小、位置和空间属性的推理。
- 逻辑推理 (Logical Reasoning):基于给定前提进行演绎或归纳推理。
- 数值常识 (Numeric Common Sense):对数字和数量的直觉性理解。
- 科学推理 (Scientific Reasoning):应用科学知识和原理解决问题。
- 统计推理 (Statistical Reasoning):解释和分析数据、图表和概率。
- 核心任务类型 (Primary Task Types):将问题归纳为五种主要任务形式。
- 图表问答 (Figure Question Answering, FQA):围绕统计图表进行推理。
- 几何问题求解 (Geometry Problem Solving, GPS):处理几何学领域的题目。
- 数学应用题 (Math Word Problem, MWP):在日常场景下进行算术推理。
- 教科书问答 (Textbook Question Answering, TQA):涉及科学主题和图表的知识密集型推理。
- 视觉问答 (Visual Question Answering, VQA):在通用视觉场景下回答需要数学计算的问题。
相关工作
当前的AI研究现状是,大量基准测试(如GSM-8K)主要评估纯文本环境下的数学推理能力,而通用的视觉问答(VQA)数据集中仅有少量问题涉及数学推理。这导致领域内缺乏一个能够系统性、全面性地评估模型在视觉与数学交叉领域能力的工具。
本文旨在解决这一具体问题:创建一个综合性的基准(即 MathVista),用于评估基础模型(Foundation Models)在多样化的视觉情境下进行复杂数学推理的能力,从而推动能够处理现实世界中富含数学信息和视觉内容的通用人工智能智能体的发展。
本文方法
本文的核心贡献是构建了一个名为 MathVista 的新型基准测试。其构建过程和创新点如下:
数据集构建
MathVista 的构建遵循了严格的指导原则,旨在确保任务的多样性、视觉背景的丰富性、挑战的层次性以及评估的确定性。其数据来源分为三个部分:
- 整合现有数学问答数据集:从9个现有的多模态数学问答(MathQA)数据集中收集了2,666个样本,涵盖几何问题、数学应用题和大学课程中的教科书问答。
- 筛选现有视觉问答数据集:审查了超过70个VQA数据集,通过启发式规则(如答案为数字、问题含数量词)初步筛选,再由三位专家人工标注,最终从19个VQA数据集中精选出2,739个需要数学推理的样本。
- 创建三个全新数据集:为了弥补现有数据集在特定推理类型上的空白,本文创建了三个共计736个样本的新数据集:
- IQTest:包含228个样本,源自在线学习平台的智力测验图,专注于评估对拼图、图形规律的归纳和抽象推理能力。
- FunctionQA:包含400个样本,要求对函数图像进行精细的视觉感知,并围绕变量、表达式和函数进行代数推理。
- PaperQA:包含107个样本,要求模型理解学术论文中的图表、图形,并回答相关问题,侧重于科学推理。
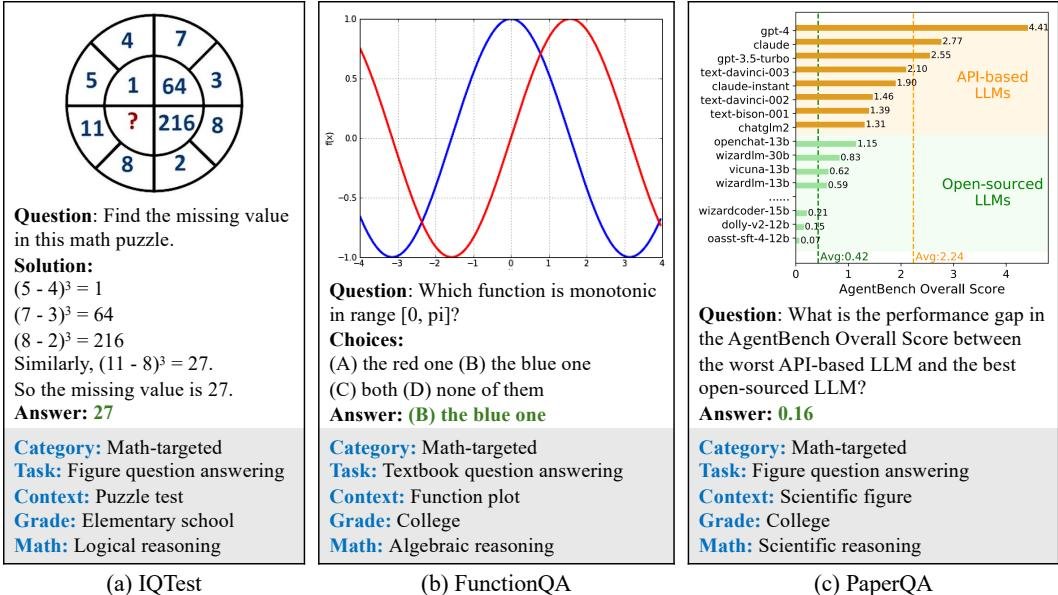
创新点
MathVista 的本质创新在于其 系统性和全面性。与以往专注于特定任务(如图表问答)或特定视觉背景(如几何图)的基准不同,MathVista:
- 由分类体系驱动:首次在一个统一的框架下,系统性地整合了7种数学推理技能、5种核心任务类型和19种不同的视觉背景(如自然图像、几何图、函数图、论文插图等)。
- 填补了关键空白:通过创建IQTest、FunctionQA和PaperQA,专门解决了评估高级逻辑、代数和科学推理能力的难题,这些都是以往基准所忽视的。
- 提供精细化分析:为每个样本标注了丰富的元数据,如问题类型、答案类型、任务类别、年级水平、视觉背景和所需推理技能,使得对模型能力进行细致入微的诊断和分析成为可能。
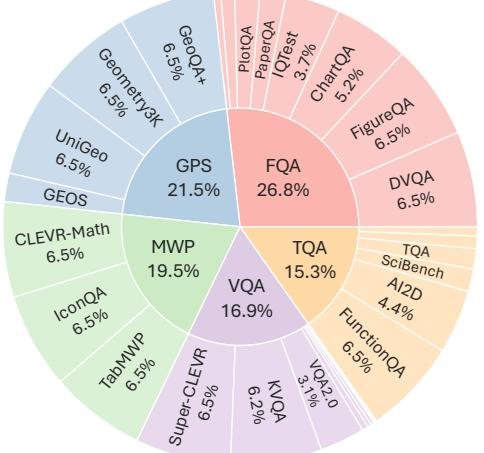
数据集概况
MathVista 共包含6,141个问题,其关键统计数据和来源分布如下:
| 统计项 | 数量 |
|---|---|
| 总问题数 | 6,141 |
| - 多选题 | 3,392 (55.2%) |
| - 自由形式题 | 2,749 (44.8%) |
| - 有注解的问题 | 5,261 (85.6%) |
| - 新标注的问题 | 736 (12.0%) |
| 独立图像数 | 5,487 |
| 独立问题数 | 4,746 |
| 独立答案数 | 1,464 |
| 来源数据集 | 31 |
| - 现有 VQA 数据集 | 19 |
| - 现有 MathQA 数据集 | 9 |
| - 本文新标注的数据集 | 3 |
| 视觉情景(图像)类别 | 19 |
| 最大问题长度 | 213 |
| 最大答案长度 | 27 |
| 最大选项数 | 8 |
| 平均问题长度 | 15.6 |
| 平均答案长度 | 1.2 |
| 平均选项数 | 3.4 |
Table 1: MathVista 的关键统计数据。
实验结论
本文对12个主流基础模型(包括LLMs、LMMs)在MathVista上进行了全面评估,得出了以下关键结论:
核心发现
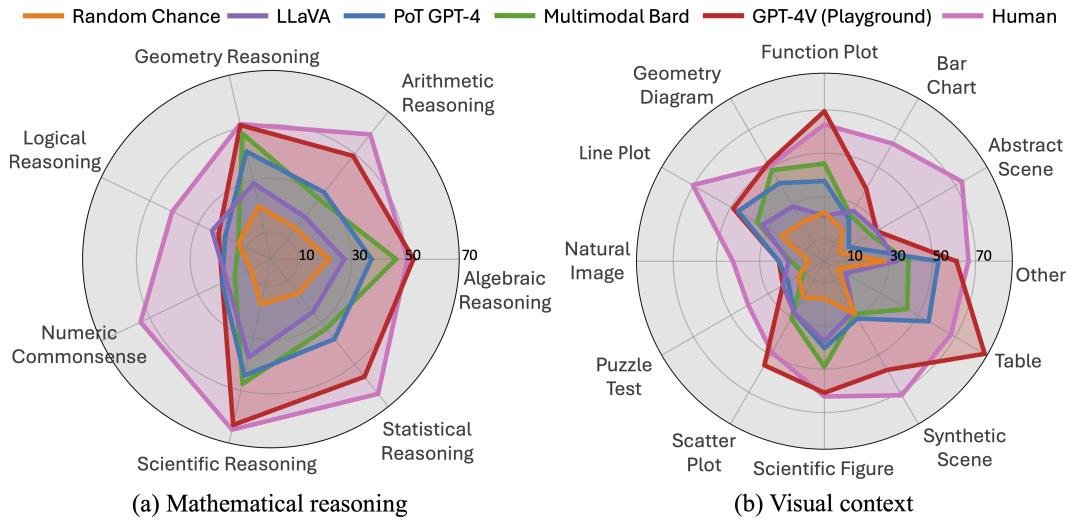
- MathVista 极具挑战性:人类在该基准上的准确率也仅为 \(60.3%\),证明了其问题的复杂性。最先进的 GPT-4V 模型取得了 \(49.9%\) 的准确率,尽管大幅领先第二名Bard(\(34.8%\)),但与人类表现仍有 \(10.4%\) 的显著差距。这表明,在视觉环境中进行复杂的数学推理对当前所有模型都是一个巨大的挑战。
- GPT-4V 性能卓越:GPT-4V 的优异表现主要归功于其强大的视觉感知和数学推理能力。它在某些任务上(如代数推理、表格和函数图理解)甚至超越了人类平均水平。
- 多模态能力至关重要:纯文本LLM(如仅使用问题的GPT-4)表现不佳(最高29.2%),即使为其提供图像描述和OCR文本(增强型LLM,最高33.9%),性能提升也有限。这证明了端到端的多模态理解能力是解决此类问题的关键。
- 开源模型与顶尖模型差距巨大:开源LMMs(如LLaVA)的准确率普遍在20%-26%之间,远低于Bard和GPT-4V,说明在模型架构、预训练数据或对齐策略上还有巨大的提升空间。
模型表现总结
下表总结了各模型在 \(testmini\) 子集上的表现:
| Model | Input | ALL | FQA | GPS | MWP | TQA | VQA | ALG | ARI | GEO | LOG | NUM | SCI | STA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Heuristics baselines | 18.2 | 21.6 | 21.7 | 14.7 | 20.1 | 17.2 | 16.3 | |||||||
| Random chance | - | 17.9 | 18.2 | 3.8 | 19.6 | 26.3 | 22.7 | 13.5 | 8.3 | 33.1 | 18.7 | 31.4 | 24.3 | 19.4 |
| Frequent guess | - | 26.3 | 34.1 | 20.4 | 31.0 | 24.6 | 29.1 | 32.8 | 20.4 | 33.3 | 13.5 | 12.1 | 32.0 | 20.9 |
| Large Language Models (LLMs) | ||||||||||||||
| 2-shot CoT GPT-4 | Q only | 29.2 | 20.1 | 44.7 | 8.6 | 46.2 | 31.3 | 41.6 | 19.3 | 41.0 | 18.9 | 13.9 | 47.5 | 18.9 |
| Augmented Large Language Models (Augmented-LLMs) | ||||||||||||||
| 2-shot PoT GPT-4 | Q, Ic, It | 33.9 | 30.1 | 39.4 | 30.6 | 39.9 | 31.3 | 37.4 | 31.7 | 41.0 | 18.9 | 20.1 | 44.3 | 37.9 |
| Large Multimodal Models (LMMs) | ||||||||||||||
| LLaVA-LLaMA-2-13B | Q, I | 26.1 | 26.8 | 29.3 | 16.1 | 32.3 | 26.3 | 27.3 | 20.1 | 28.8 | 24.3 | 18.3 | 37.3 | 25.1 |
| Multimodal Bard | Q, I | 34.8 | 26.0 | 47.1 | 29.6 | 48.7 | 26.8 | 46.5 | 28.6 | 47.8 | 13.5 | 14.9 | 47.5 | 33.0 |
| GPT-4V (Playground) | Q, I | 49.9 | 43.1 | 50.5 | 57.5 | 65.2 | 38.0 | 53.0 | 49.0 | 51.0 | 21.6 | 20.1 | 63.1 | 55.8 |
| Human performance | Q, I | 60.3 | 59.7 | 48.4 | 73.0 | 63.2 | 55.9 | 50.9 | 59.2 | 51.4 | 40.7 | 53.8 | 64.9 | 63.9 |
Table 2: 在 MATHVISTA 的 testmini 子集上的准确率得分。
失败案例分析
对模型失败案例的定性分析表明:
- 幻觉是主要问题:对Bard的分析发现,近50%的错误解释包含幻觉(Hallucination),即模型会编造不存于图像或问题中的事实。
- 推理过程不可靠:即使在给出正确答案的情况下,模型也可能依赖于错误的推理过程或计算。例如,Bard在一个几何问题中使用了错误的余弦定理,但碰巧得到了正确答案。
- 对外部工具的依赖:增强型LLM的性能高度依赖于图像描述和OCR工具的质量。错误的视觉信息输入会导致后续推理的失败。

总结
本文通过推出 MathVista,成功地量化了当前基础模型在视觉化数学推理方面的能力瓶颈。实验明确指出,尽管以GPT-4V为代表的模型取得了巨大进步,但距离实现与人类相当的、能够无缝整合视觉理解和严谨数学推理的通用智能仍有很长的路要走。MathVista为该领域的未来研究设定了一个清晰的目标和重要的评估工具。