Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning
-
ArXiv URL: http://arxiv.org/abs/2508.19828v1
-
作者: Ercong Nie; Yunpu Ma; Zifeng Ding; Xiaowen Ma; Hinrich Schütze; Volker Tresp
-
发布机构: Ludwig Maximilian University of Munich; Technical University of Munich; University of Cambridge; University of Hong Kong
TL;DR
本文提出了Memory-R1框架,通过强化学习(RL)训练两个专门的智能体——一个用于结构化记忆操作的内存管理器和一个用于筛选并推理记忆的回答智能体,从而使大型语言模型(LLM)能够主动、自适应地管理和利用外部记忆,显著提升了其长时程推理能力。
关键定义
本文提出或沿用了以下几个关键概念:
- Memory-R1: 一个基于强化学习(Reinforcement Learning, RL)的框架,旨在增强LLM的记忆能力。它包含两个核心组件:内存管理器和回答智能体,二者都通过结果驱动的RL进行微调。
- 内存管理器 (Memory Manager): 一个专门的智能体,经由RL训练后,学习对外部记忆库执行结构化的操作,包括{增加(ADD)、更新(UPDATE)、删除(DELETE)、无操作(NOOP)},以动态维护和演化记忆内容。
- 回答智能体 (Answer Agent): 另一个专门的智能体,同样经RL训练。它的任务是接收通过RAG检索到的多条候选记忆,执行“内存蒸馏”策略来筛选出最相关的信息,并基于这些精炼后的记忆进行推理,最终生成答案。
- 内存蒸馏 (Memory Distillation): 回答智能体采用的一种策略。它不是直接使用所有检索到的记忆,而是先进行一次筛选,过滤掉无关的、嘈杂的记忆条目,仅将最核心、最相关的信息用于后续的推理和答案生成,以此减少干扰,提高准确性。
- 结果驱动的强化学习 (Outcome-driven RL): 本文采用的核心训练范式。奖励信号不依赖于对每一步操作(如记忆操作或筛选决策)的精细标注,而是直接与最终任务的产出(即答案的正确与否)挂钩。这使得模型能以极少的监督信息(如仅需问答对)学会复杂的、有益于最终目标的行为。
相关工作
当前,增强LLM能力的一个主流方向是为其配备外部记忆模块,以克服其固有的无状态性和有限上下文窗口的限制。这些方法大多采用检索增强生成(Retrieval-Augmented Generation, RAG)的范式,即检索相关记忆并附加到模型的输入中。
然而,现有工作存在两大关键瓶颈:
- 静态和启发式的记忆利用: RAG检索过程通常是启发式的,可能返回过多无关信息(造成干扰)或过少关键信息(导致上下文缺失)。模型被迫在混杂着噪声的记忆上进行推理,容易出错。人类则不同,我们会先广泛回忆,再有选择地筛选和整合。
- 缺乏学习性的记忆管理: 现有系统虽然提供了记忆操作(如增、删、改),但通常依赖未经训练的LLM根据上下文指令来选择操作,缺乏与最终任务效果挂钩的学习信号。这导致它们在处理复杂情况时频繁出错。例如,当用户先后两次提及领养了不同的狗时,一个未经训练的系统可能会错误地将其理解为信息矛盾,执行“删除旧信息+增加新信息”的操作,从而破坏了记忆的完整性。
本文旨在解决上述问题,即通过引入强化学习,为LLM的记忆管理和利用过程提供一个自适应的学习机制。目标是让智能体学会何时以及如何增、删、改记忆,以及怎样从检索到的信息中筛选出真正有用的部分进行推理,使其行为与提升最终答案的准确性这一高级目标对齐。
本文方法
本文提出了Memory-R1框架,一个通过RL微调、包含两个专门智能体的记忆增强LLM系统。其核心创新在于将记忆管理和利用问题形式化为RL任务,通过结果驱动的奖励来学习最优策略。
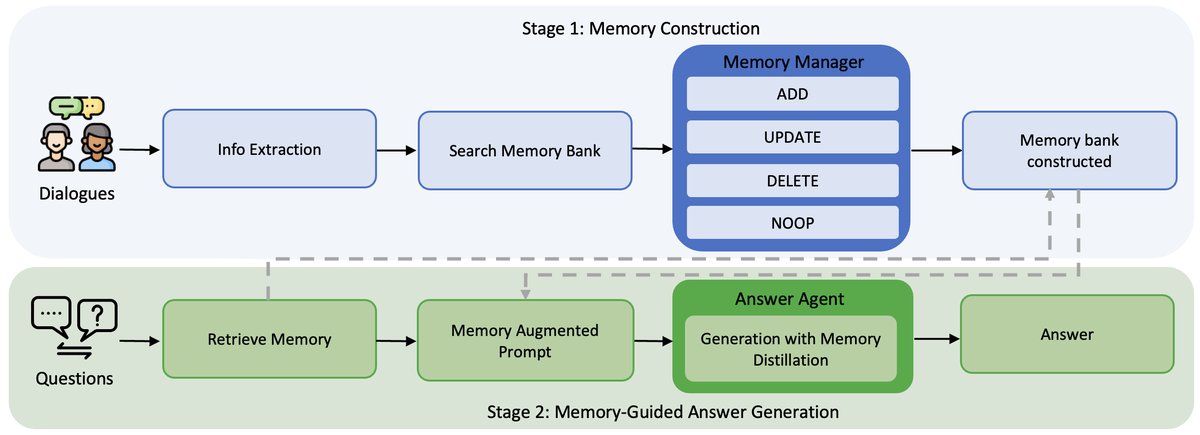 图注:Memory-R1框架概览。第一阶段(蓝色),通过RL微调的内存管理器构建和更新记忆库,其为每个新的对话回合选择{ADD, UPDATE, DELETE, NOOP}操作。第二阶段(绿色),回答智能体通过应用内存蒸馏策略对检索到的记忆进行推理来回答用户的问题。
图注:Memory-R1框架概览。第一阶段(蓝色),通过RL微调的内存管理器构建和更新记忆库,其为每个新的对话回合选择{ADD, UPDATE, DELETE, NOOP}操作。第二阶段(绿色),回答智能体通过应用内存蒸馏策略对检索到的记忆进行推理来回答用户的问题。
创新点
本文方法与以往工作的本质区别在于,它用学习取代了启发式规则。具体体现在以下两个方面:
- 可学习的记忆管理器:不再依赖LLM的零样本能力或固定的脚本来决定如何更新记忆,而是通过RL训练一个专门的内存管理器。该智能体根据最终问答任务的成败获得奖励,从而学会做出更智能的决策(例如,将相关信息“更新”合并,而不是错误地“删除”旧信息)。
- 可学习的回答智能体与内存蒸馏:回答智能体同样通过RL训练,学会执行“内存蒸馏”策略。它不再被动地接收所有RAG检索到的信息,而是主动筛选出最相关的记忆条目,过滤掉噪声,从而在更清晰、更集中的上下文上进行推理。
这种设计的核心优点是数据高效和自适应。由于采用结果驱动的奖励机制,系统仅需少量的最终问答对作为监督信号(本文实验中仅用152对),即可学习复杂的记忆操作和利用策略,无需对每一步决策进行昂贵的人工标注。
内存管理器智能体
内存管理器(Memory Manager)负责维护记忆库。对于从对话中提取的每一条新信息,它会从{ADD, UPDATE, DELETE, NOOP}中选择一个操作来更新记忆库。
-
任务形式化:管理器的策略 $\pi_{\theta}$ 将新信息 $x$ 和检索到的相关旧记忆 $\mathcal{M}_{\text{old}}$ 作为输入,输出一个操作 $o$ 及其内容 $m^{\prime}$:
\[(o,m^{\prime})\sim\pi_{\theta}(\cdot\mid x,\mathcal{M}_{\text{old}})\] -
训练与奖励:使用PPO或GRPO算法进行微调。奖励信号来自于一个冻结的回答智能体。在每次更新记忆库后,让回答智能体回答一个相关问题,其答案的准确性(Exact Match)即为奖励 $R_{answer}$。这种设计将奖励与最终目标(正确回答问题)直接挂钩。
\[R_{answer}=\mathrm{EM}(y_{\text{pred}},y_{\text{gold}})\]
回答智能体
回答智能体(Answer Agent)负责利用记忆库来回答问题。首先,通过RAG从记忆库中检索出60条候选记忆。然后,该智能体进行内存蒸馏,筛选出最相关的条目,并生成最终答案。
-
任务形式化:回答智能体的策略 $\pi_{\text{ans}}$ 将问题 $q$ 和检索到的记忆 $\mathcal{M}_{\text{ret}}$ 作为输入,输出答案 $y$:
\[y\sim\pi_{\text{ans}}(\cdot\mid q,\mathcal{M}_{\text{ret}})\] -
训练与奖励:同样使用PPO或GRPO进行微调。奖励函数非常直接,就是生成的答案 $y_{\text{pred}}$ 与标准答案 $y_{\text{gold}}$ 之间的精确匹配(EM)得分。
\[R_{answer}=\mathrm{EM}(y_{\text{pred}},y_{\text{gold}})\]
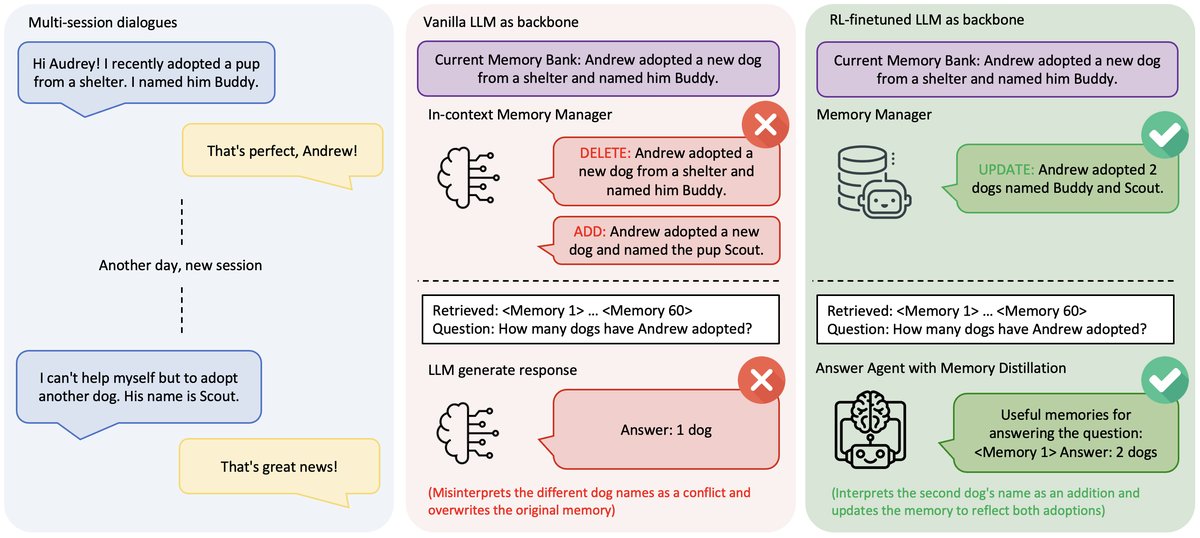 图注:Memory‑R1与原生LLM记忆系统的对比。(左)在一个多会话对话中,用户在不同会话中分别提到领养了两只狗。(中)原生内存管理器错误地将第二次领养解读为矛盾,并发出DELETE+ADD指令,导致记忆碎片化。(右)经RL训练的内存管理器发出一个UPDATE指令来整合记忆,而回答智能体则应用内存蒸馏:从RAG检索到的60条记忆中,首先筛选出真正有用的记忆(<Memory 1>),然后基于所选条目进行推理,得出正确答案(“2只狗”)。
图注:Memory‑R1与原生LLM记忆系统的对比。(左)在一个多会话对话中,用户在不同会话中分别提到领养了两只狗。(中)原生内存管理器错误地将第二次领养解读为矛盾,并发出DELETE+ADD指令,导致记忆碎片化。(右)经RL训练的内存管理器发出一个UPDATE指令来整合记忆,而回答智能体则应用内存蒸馏:从RAG检索到的60条记忆中,首先筛选出真正有用的记忆(<Memory 1>),然后基于所选条目进行推理,得出正确答案(“2只狗”)。
实验结论
主要结果
本文在LOCOMO基准上进行了广泛实验,证明了Memory-R1框架的有效性。
| 模型 | 方法 | 单跳推理 | 多跳推理 | 开放域 | 时序推理 | 总体 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1$\uparrow$ | B1$\uparrow$ | J$\uparrow$ | F1$\uparrow$ | B1$\uparrow$ | J$\uparrow$ | F1$\uparrow$ | B1$\uparrow$ | J$\uparrow$ | F1$\uparrow$ | B1$\uparrow$ | J$\uparrow$ | F1$\uparrow$ | B1$\uparrow$ | J$\uparrow$ | ||
| LLaMA-3.1-8B Instruct | LOCOMO | 12.25 | 9.77 | 13.81 | 13.69 | 10.96 | 20.48 | 11.59 | 8.30 | 15.96 | 9.38 | 8.15 | 4.65 | 11.41 | 8.71 | 13.62 |
| Zep | 30.15 | 17.15 | 52.38 | 15.04 | 11.56 | 33.33 | 26.67 | 18.44 | 45.36 | 3.49 | 2.68 | 27.58 | 22.60 | 15.05 | 42.80 | |
| A-Mem | 21.62 | 16.93 | 44.76 | 13.82 | 11.45 | 34.93 | 34.67 | 29.13 | 49.38 | 25.77 | 22.14 | 36.43 | 29.20 | 24.40 | 44.76 | |
| LangMem | 22.40 | 15.21 | 47.26 | 18.65 | 16.03 | 39.81 | 31.62 | 23.85 | 48.38 | 27.75 | 21.53 | 30.94 | 28.34 | 21.31 | 44.18 | |
| Mem0 | 27.29 | 18.63 | 43.93 | 18.59 | 13.86 | 37.35 | 34.03 | 24.77 | 52.27 | 26.90 | 21.06 | 31.40 | 30.41 | 22.22 | 45.68 | |
| Memory-R1-PPO | 32.52 | 24.47 | 53.56 | 26.86 | 23.47 | 42.17 | 45.30 | 39.18 | 64.10 | 41.57 | 26.11 | 47.67 | 41.05 | 32.91 | 57.54 | |
| Memory-R1-GRPO | 35.73 | 27.70 | 59.83 | 35.65 | 30.77 | 53.01 | 47.42 | 41.24 | 68.78 | 49.86 | 38.27 | 51.55 | 45.02 | 37.51 | 62.74 | |
| Qwen-2.5-7B Instruct | LOCOMO | 9.57 | 7.00 | 15.06 | 11.84 | 10.02 | 19.28 | 8.67 | 6.52 | 12.79 | 8.35 | 8.74 | 5.43 | 8.97 | 7.27 | 12.17 |
| Zep | 31.02 | 21.39 | 42.85 | 20.42 | 15.76 | 23.81 | 25.25 | 21.34 | 42.26 | 8.94 | 8.42 | 29.31 | 23.22 | 18.78 | 38.99 | |
| A-Mem | 18.96 | 12.86 | 40.78 | 14.73 | 12.66 | 31.32 | 30.58 | 26.14 | 46.90 | 23.67 | 20.67 | 28.68 | 26.08 | 21.78 | 40.78 | |
| LangMem | 22.84 | 16.98 | 43.64 | 18.98 | 16.89 | 44.38 | 32.47 | 25.98 | 50.45 | 26.62 | 20.93 | 23.08 | 28.69 | 22.76 | 43.42 | |
| Mem0 | 24.96 | 18.05 | 61.92 | 20.31 | 15.82 | 48.19 | 32.74 | 25.27 | 65.20 | 33.16 | 26.28 | 38.76 | 30.61 | 23.55 | 53.30 | |
| Memory-R1-PPO | 34.22 | 23.61 | 57.74 | 32.87 | 29.48 | 53.01 | 44.78 | 38.72 | 66.99 | 42.88 | 30.30 | 42.25 | 41.72 | 33.70 | 59.53 | |
| Memory-R1-GRPO | 33.64 | 26.06 | 62.34 | 23.55 | 20.71 | 40.96 | 46.86 | 40.92 | 67.81 | 47.75 | 38.49 | 49.61 | 43.14 | 36.44 | 61.51 |
- 显著优于基线: 无论使用 LLaMA-3.1-8B 还是 Qwen-2.5-7B 作为基础模型,Memory-R1(特别是GRPO变体)在所有指标(F1、BLEU-1、LLM-as-a-Judge)和所有问题类型上都大幅超越了包括Mem0在内的最强基线。例如,在LLaMA-3.1-8B上,Memory-R1-GRPO相比Mem0在总体F1分数上提升了48%,在LLM-as-a-Judge上提升了37%。
- 跨模型泛化性强: Memory-R1在两种不同的LLM架构上均取得一致的、显著的性能提升,证明了该框架的通用性和有效性,不依赖于特定的模型架构。
消融研究
- 内存管理器的效果: 仅对内存管理器进行RL微调,就能带来显著的性能提升,证明通过RL学习记忆操作优于依赖LLM的上下文学习。
| 方法 | F1$\uparrow$ | B1$\uparrow$ | J$\uparrow$ |
|---|---|---|---|
| LLaMA3.1-8B | 26.73 | 20.54 | 47.82 |
| LLaMA3.1-8B + PPO | 32.55 | 24.60 | 59.37 |
| LLaMA3.1-8B + GRPO | 33.05 | 24.91 | 59.91 |
- 回答智能体的效果: 同样,仅对回答智能体进行RL微调,也能大幅提高答案质量,证明学习如何筛选和利用记忆至关重要。
| 方法 | F1$\uparrow$ | B1$\uparrow$ | J$\uparrow$ |
|---|---|---|---|
| LLaMA3.1-8B | 26.73 | 20.54 | 47.82 |
| LLaMA3.1-8B + PPO | 34.48 | 28.13 | 49.04 |
| LLaMA3.1-8B + GRPO | 37.54 | 30.64 | 52.87 |
- 内存蒸馏的效果: 带有内存蒸馏策略的回答智能体比没有该策略的智能体表现更好,说明过滤掉无关记忆能够减少噪声干扰,让模型更专注于有效信息。
| 方法 | F1$\uparrow$ | B1$\uparrow$ | J$\uparrow$ |
|---|---|---|---|
| GRPO 无内存蒸馏 | 40.95 | 34.37 | 60.14 |
| GRPO 有内存蒸馏 | 45.02 | 37.51 | 62.74 |
- 协同效应: 经过RL微调的回答智能体,在与更强的内存管理器(如GPT-4o-mini)配合时,性能提升幅度更大。这表明Memory-R1的组件之间存在正向的协同效应,系统整体性能会随着单个组件的增强而加倍提升。
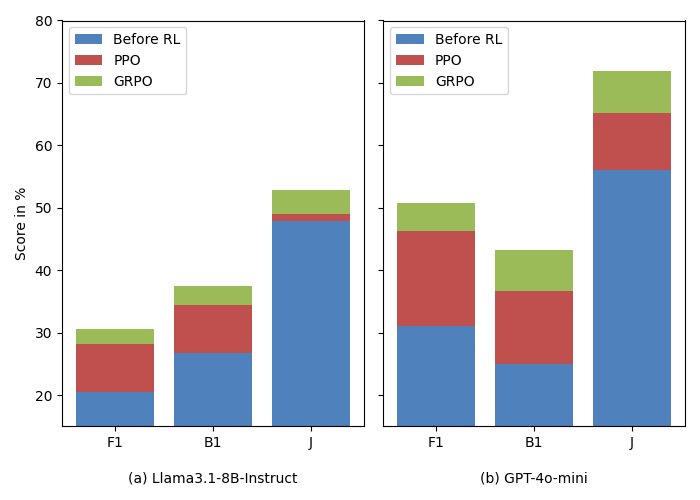 图注:当与不同的内存管理器配对时,回答智能体变体(基础/PPO微调/GRPO微调)的性能增益:(a)LLaMA 3.1-8B-Instruct 和(b)更强的 GPT-4o-mini。
图注:当与不同的内存管理器配对时,回答智能体变体(基础/PPO微调/GRPO微调)的性能增益:(a)LLaMA 3.1-8B-Instruct 和(b)更强的 GPT-4o-mini。
总结
实验结果有力地证明了本文方法的优势。通过结果驱动的强化学习,Memory-R1能以极高的数据效率(仅用152个问答对训练)教会LLM如何智能地管理和利用记忆,解决了传统启发式方法中的诸多痛点。该方法不仅在多个指标和模型上创造了新的SOTA,其组件的有效性和协同效应也通过消融实验得到了验证。最终结论是,RL是解锁LLM更高级、更具适应性的记忆能力的关键路径。