Memory Retrieval and Consolidation in Large Language Models through Function Tokens
-
ArXiv URL: http://arxiv.org/abs/2510.08203v1
-
作者: Shaohua Zhang; Hang Li; Yuan Lin
-
发布机构: ByteDance
TL;DR
本文提出了“功能性Token假说” (Function Token Hypothesis),揭示了语言模型中的一小部分高频Token(功能性Token)在记忆检索和巩固中扮演着核心角色:在推理时激活上下文中的预测性特征,在预训练时驱动模型学习和扩展新特征。
关键定义
本文为理解大型语言模型(LLM)的记忆机制,提出或沿用了以下几个核心概念:
- 功能性Token (Function Token) 与内容性Token (Content Token):本文并未严格遵循语言学定义,而是基于统计频率对Token进行分类。在预训练语料中,累计出现频率占前40%的少数高频Token被划分为功能性Token(如标点、冠词、介词等),其余大部分低频Token则为内容性Token。
- 记忆检索 (Memory Retrieval):指在模型推理(生成文本)过程中,激活其内部的特征和神经回路以提取和使用已存知识的机制。
- 记忆巩固 (Memory Consolidation):指在模型预训练过程中,通过学习数据来更新模型参数,从而形成并扩展其内部特征和神经回路的过程。
- 功能性Token假说 (Function Token Hypothesis):这是本文的核心理论。它包含两个方面:
- 推理时(记忆检索):功能性Token负责从上下文中激活最具预测性的特征,从而主导下一个Token的预测。
- 预训练时(记忆巩固):预测功能性Token之后的下一个Token(通常是内容性Token)这一任务,是驱动模型更新参数、学习并扩展其特征库的主要动力。
相关工作
当前,对大型语言模型(LLM)的研究通过稀疏自动编码器 (Sparse Autoencoders, SAEs) 等技术,在从神经元激活中分解和解释“特征” (features) 方面取得了显著进展。研究者们发现,模型通过特征的叠加 (superposition) 来存储知识,并且这些特征具有人类可解释的语义。
然而,尽管在理解“特征”是什么上有所突破,但LLM的记忆机制,即知识是如何被存入和取出的,仍然是一个“黑箱”。具体来说,领域内存在两个悬而未决的基本问题:
- 记忆如何被检索? 在推理(如回答问题)时,模型是如何从其庞大的参数中准确调动所需知识的?
- 记忆如何被巩固? 在预训练过程中,模型是如何有效地学习、组织并将海量知识压缩到其参数中的?
本文旨在通过引入功能性Token和内容性Token的视角,来回答上述两个问题,从而揭开LLM记忆机制的神秘面纱。
本文方法
本文的核心是一种新的理论假说——功能性Token假说,并通过一系列精心设计的分析实验来验证它。
功能性Token与内容性Token的划分
本文首先基于Token在语料库中的出现频率来近似地区分功能性与内容性Token。自然语言中的词频遵循齐夫定律 (Zipf’s law),即少数词语(功能性词语)被高频使用,而大量词语(内容性词语)则使用频率很低。
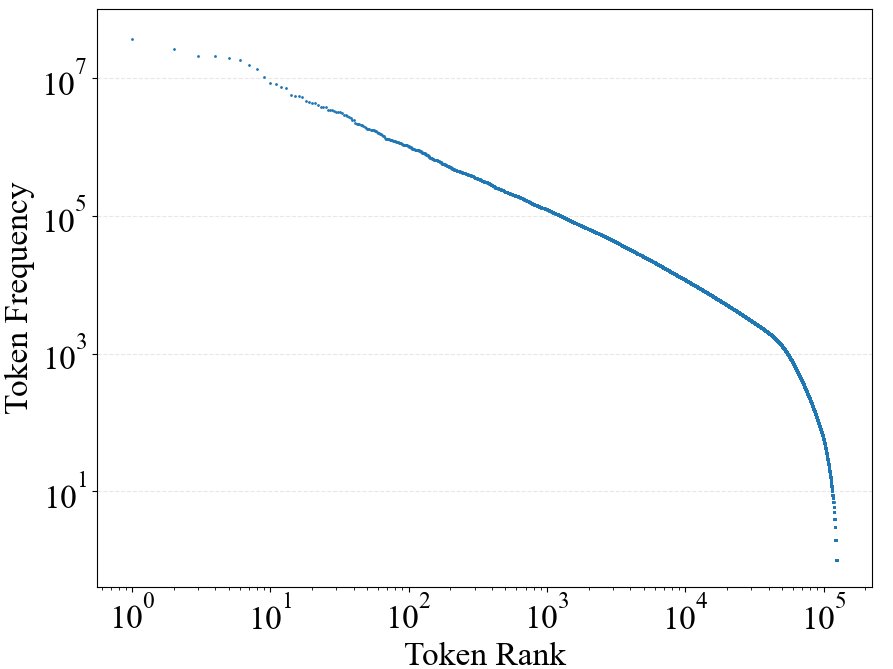
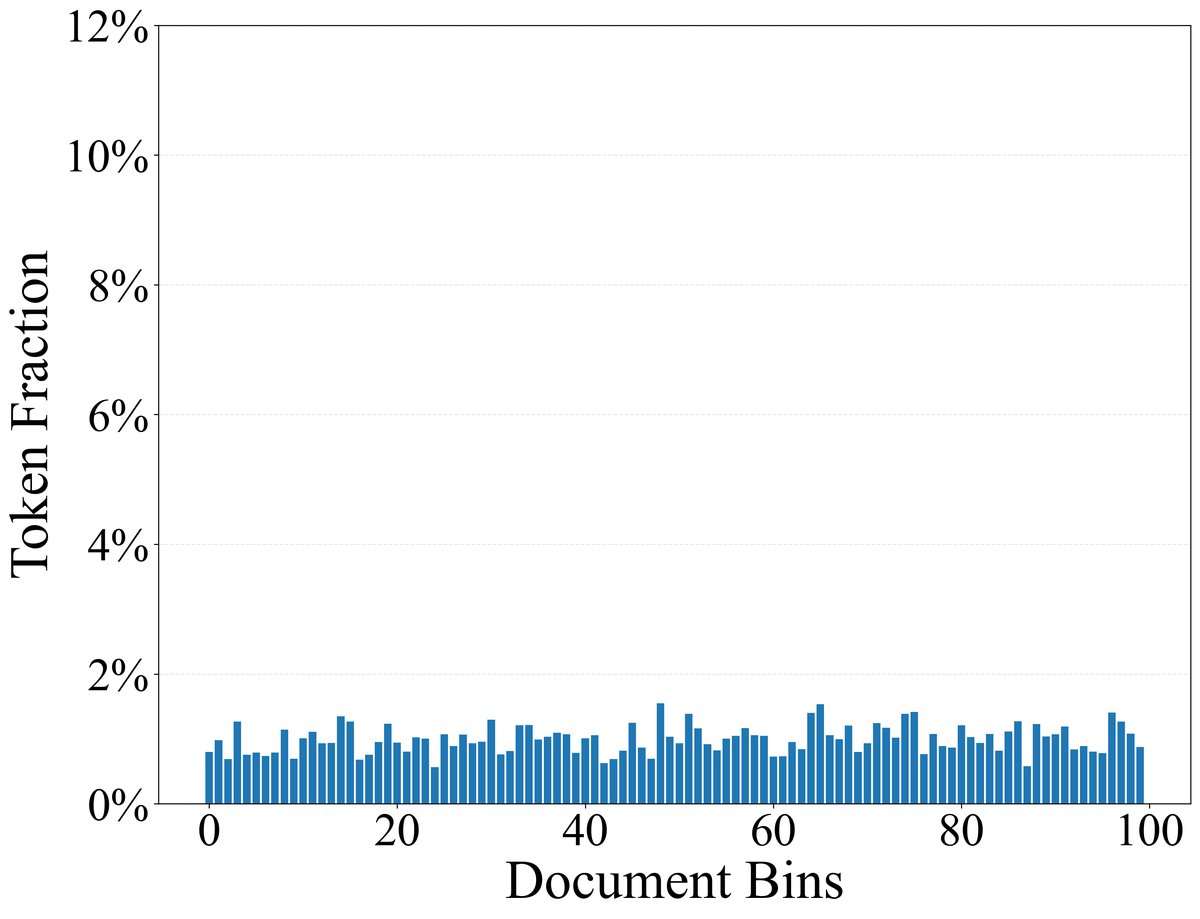
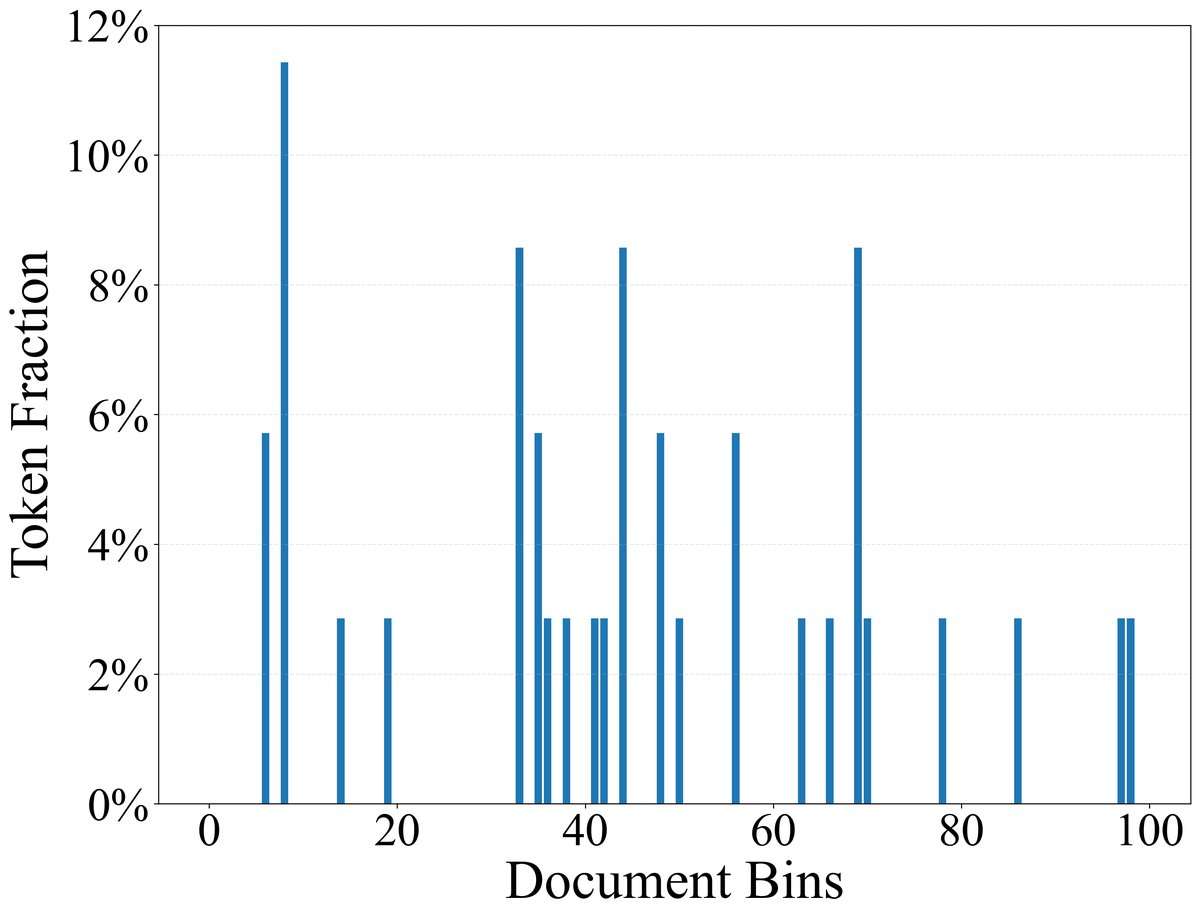
作者使用LLaMA-3.1分词器对SlimPajama-627B语料库进行处理,将累计出现次数占总数40%的最常见的122个Token定义为功能性Token,其余的为内容性Token。这些功能性Token主要包括标点符号、冠词、介词、连词等,它们在几乎所有文档中都均匀出现;而内容性Token则通常集中出现在少数相关主题的文档中。
记忆检索:功能性Token激活预测性特征
为了验证功能性Token在推理时的记忆检索作用,本文进行了两项分析。
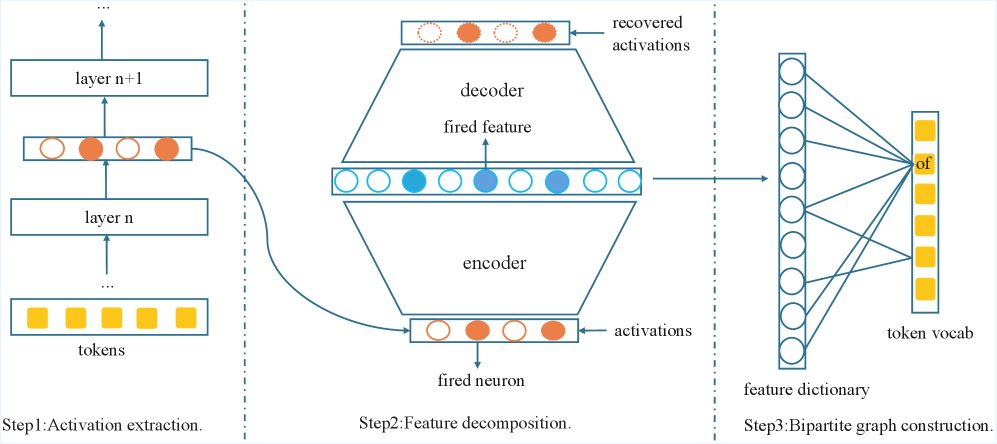
创新点1:Token-特征二部图分析
作者构建了一个连接Token与模型特征的二部图,以量化不同Token对特征的激活能力。
- 提取激活:将包含约500万Token的文本输入Gemma2-9B模型,并提取其浅、中、深三个代表性层(第9、20、31层)的激活值。
- 特征分解:使用预先训练好的SAE将每个Token的激活值分解为稀疏的、可解释的特征组合。
- 构建图:如果一个Token在任何上下文中激活了某个特征,就在该Token和特征之间连接一条边。
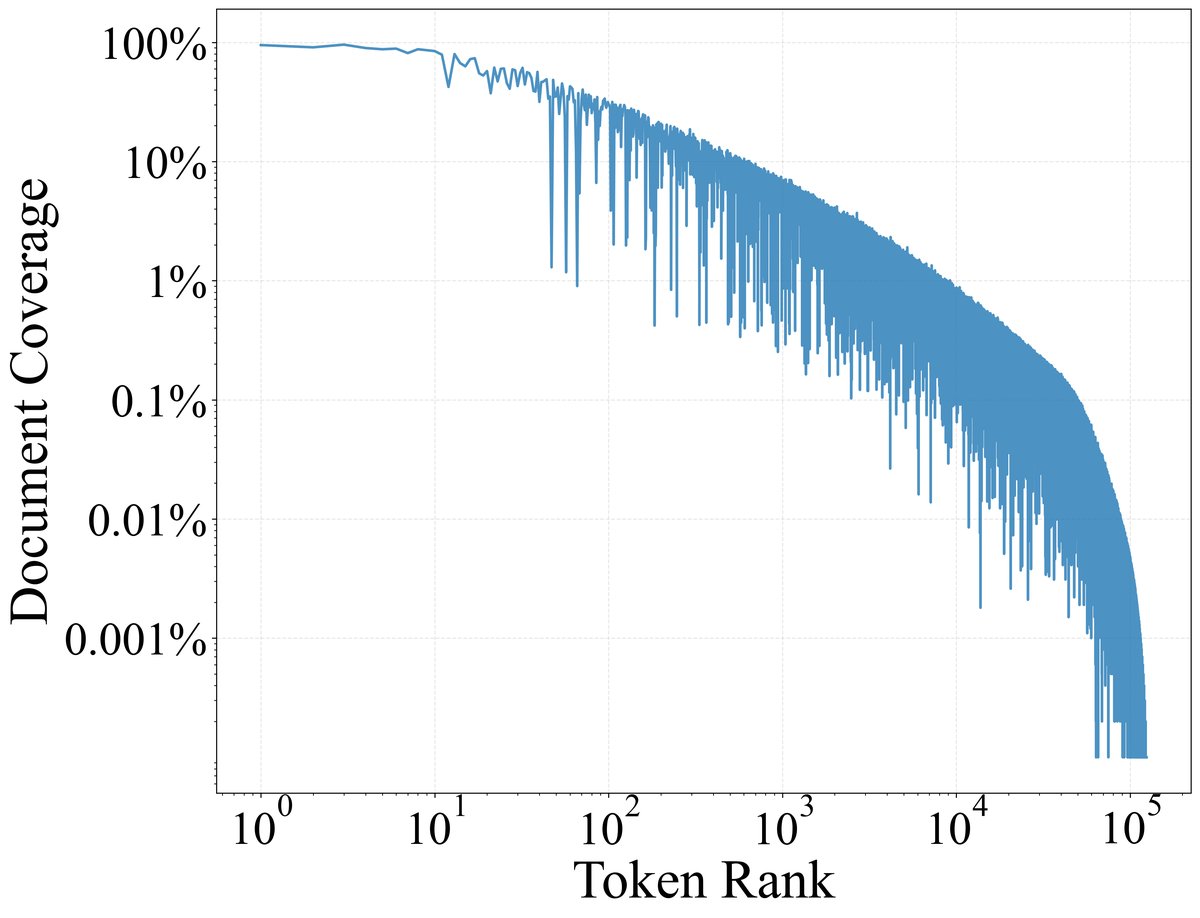
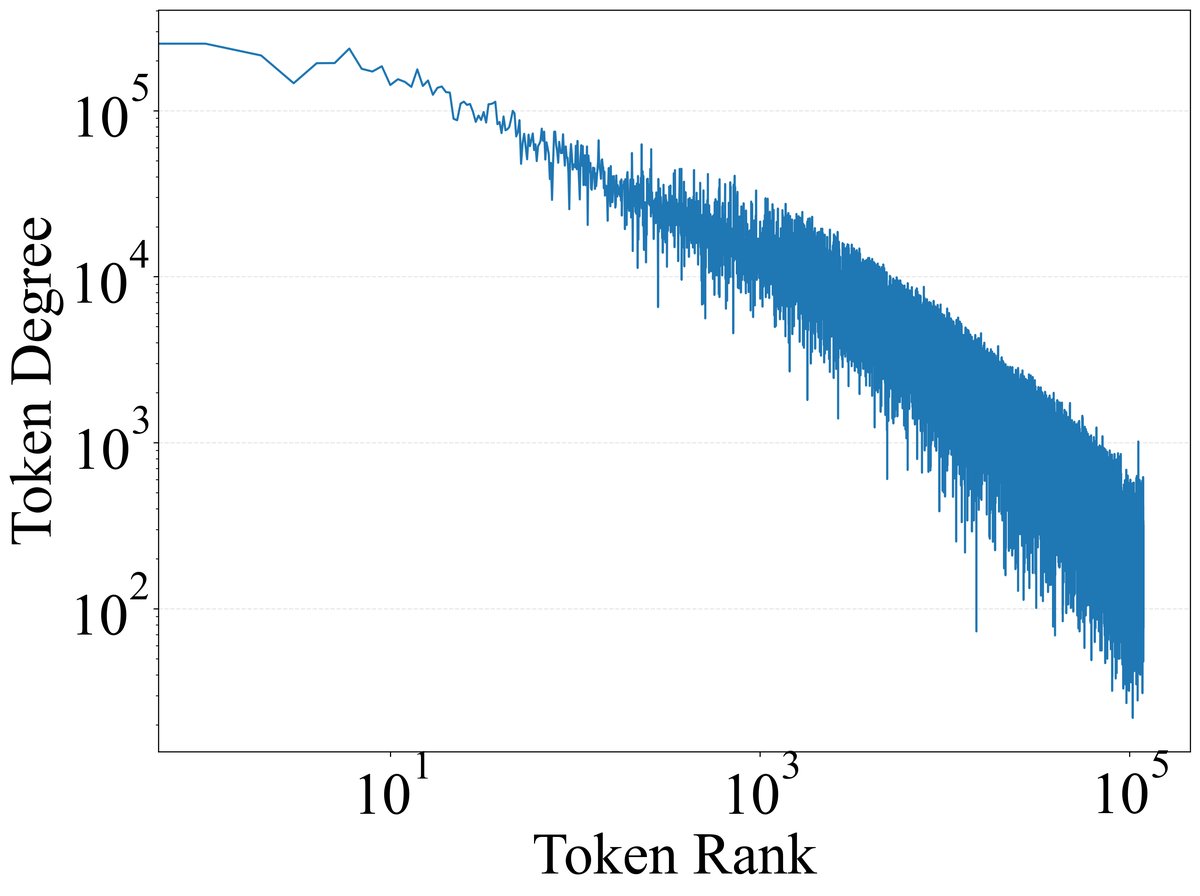
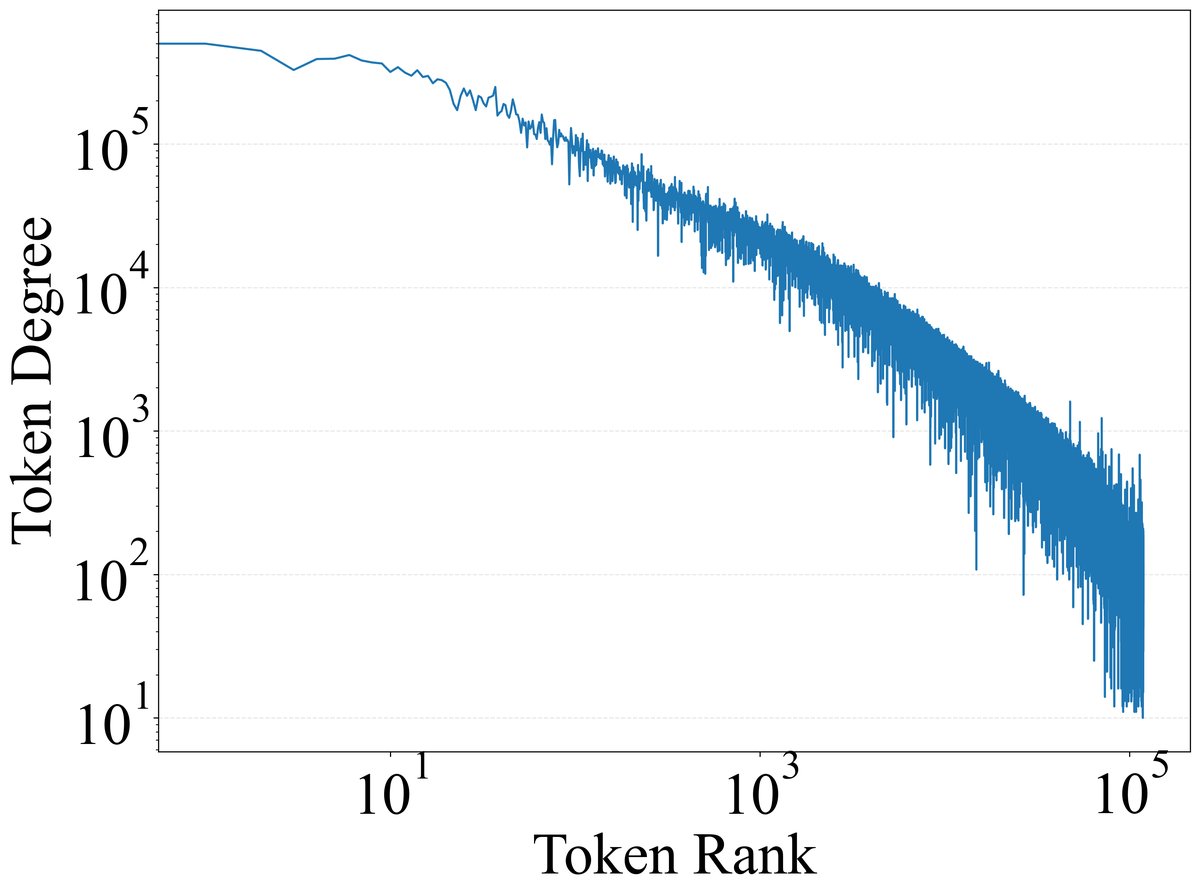
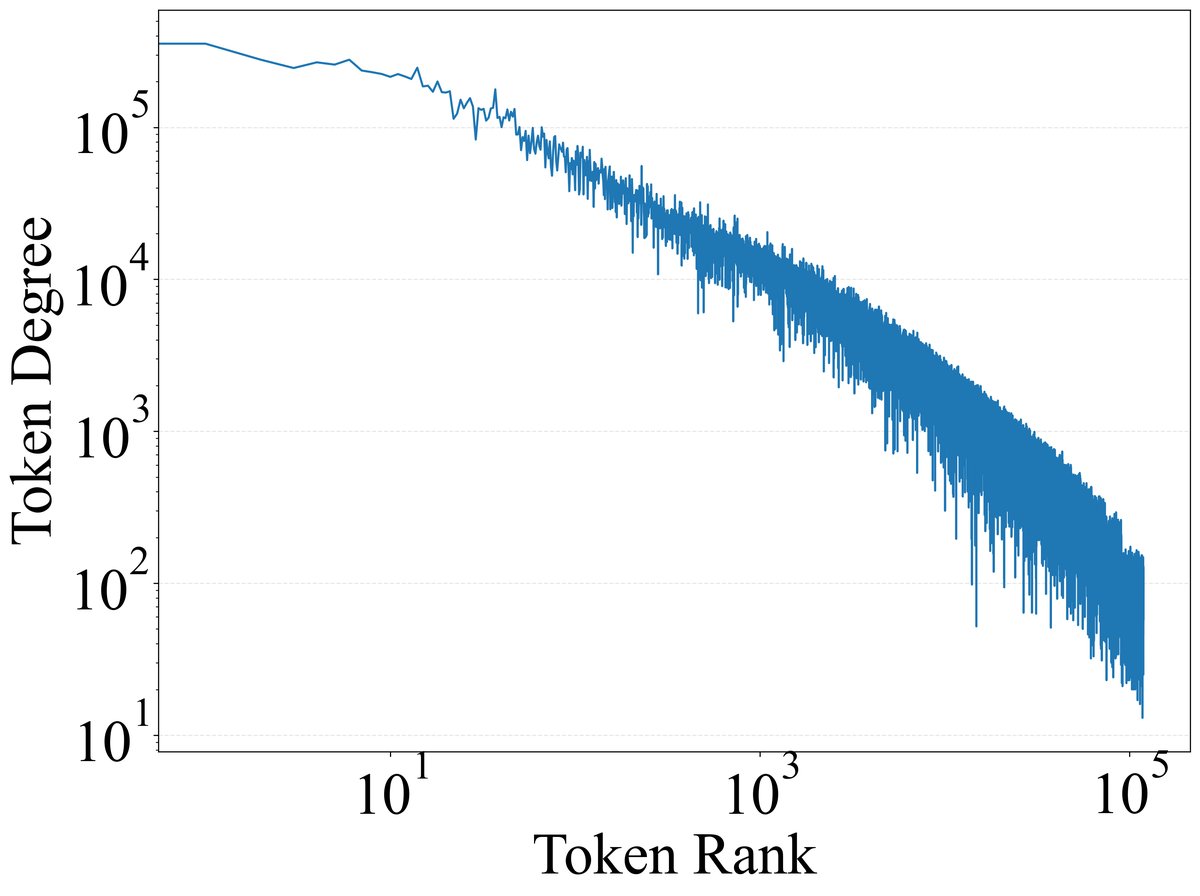
分析结果显示,极少数功能性Token激活了模型中绝大多数的特征。如下图所示,Token激活的特征数量(度)与其频率高度相关。
下表的数据进一步证实,仅仅排名前10的功能性Token,在中层(第20层,通常被认为语义信息最丰富)就激活了超过70%的特征,表明功能性Token对模型的特征空间具有普遍的访问权限。
| Token | 累积特征覆盖率 | |||
|---|---|---|---|---|
| 排名 | 文本 | 第 9 层 | 第 20 层 | 第 31 层 |
| 1 | . | 23.19% | 51.32% | 37.21% |
| 2 | , | 32.01% | 62.45% | 49.78% |
| 3 | the | 36.88% | 66.93% | 55.15% |
| 4 | \n | 39.68% | 71.30% | 59.86% |
| 5 | and | 41.21% | 71.97 % | 61.48% |
| 6 | to | 43.16% | 73.07 % | 63.30% |
| 7 | of | 46.00% | 74.43 % | 65.16% |
| 8 | 空格 | 47.44% | 75.70 % | 67.08% |
| 9 | a | 47.96% | 76.12% | 67.74% |
| 10 | in | 48.52% | 76.46% | 68.27% |
创新点2:特征再激活与干预实验
本文通过案例研究和特征干预实验,揭示了功能性Token如何动态地再激活 (reactivate) 上下文中的关键特征。
在一个案例中,对于两个仅有一个词不同的Prompt(\(...capital of Russia?\) vs \(...capital of UK?\)),模型中的内容性Token “Russia” 和 “UK” 分别激活了“俄罗斯”和“英国”相关特征。随后的同一个功能性Token(如\(:\)或\(\n\)),则会根据上文内容,选择性地再激活并传递这些不同的特征,最终引导模型生成不同的答案(莫斯科 vs 伦敦)。这表明功能性Token本身没有固定语义,而是扮演着一个动态的“路由器”角色。
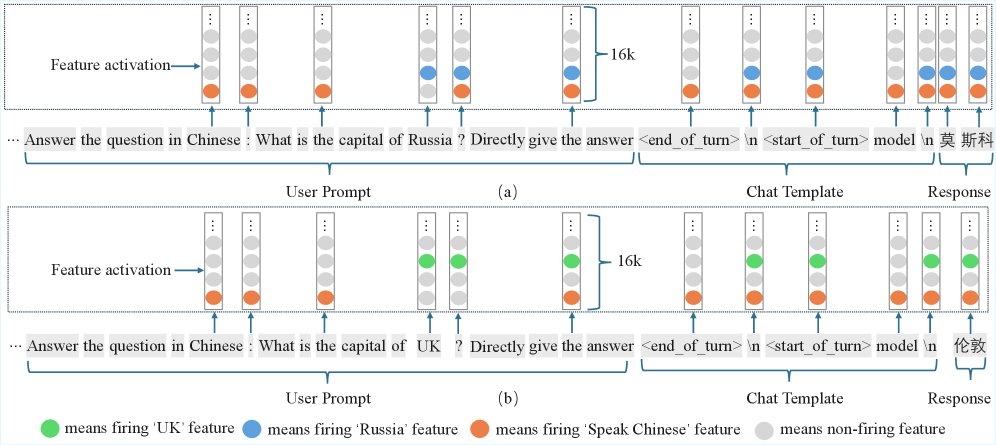
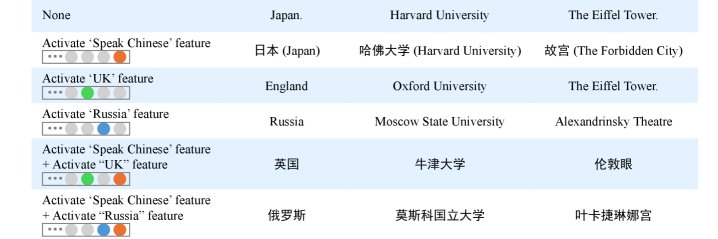
进一步地,作者通过特征干预 (steering) 实验证明了这种因果关系。在Prompt的最后一个功能性Token(如\(\n\))处,人为激活特定特征(如“说中文”或“俄罗斯”),可以直接改变模型的输出内容和语言。例如,对于问题“富士山在哪里?”,在\(\n\)处激活“说中文”特征,模型回答会从“Japan”变为中文“日本”。这证明了功能性Token是控制后续内容生成的关键节点。
记忆巩固:功能性Token驱动特征学习
为了探究记忆巩固的过程,本文从头开始训练了两个LLM(1.5B和8B),并分析了其训练动态。
创新点1:追踪特征扩张过程
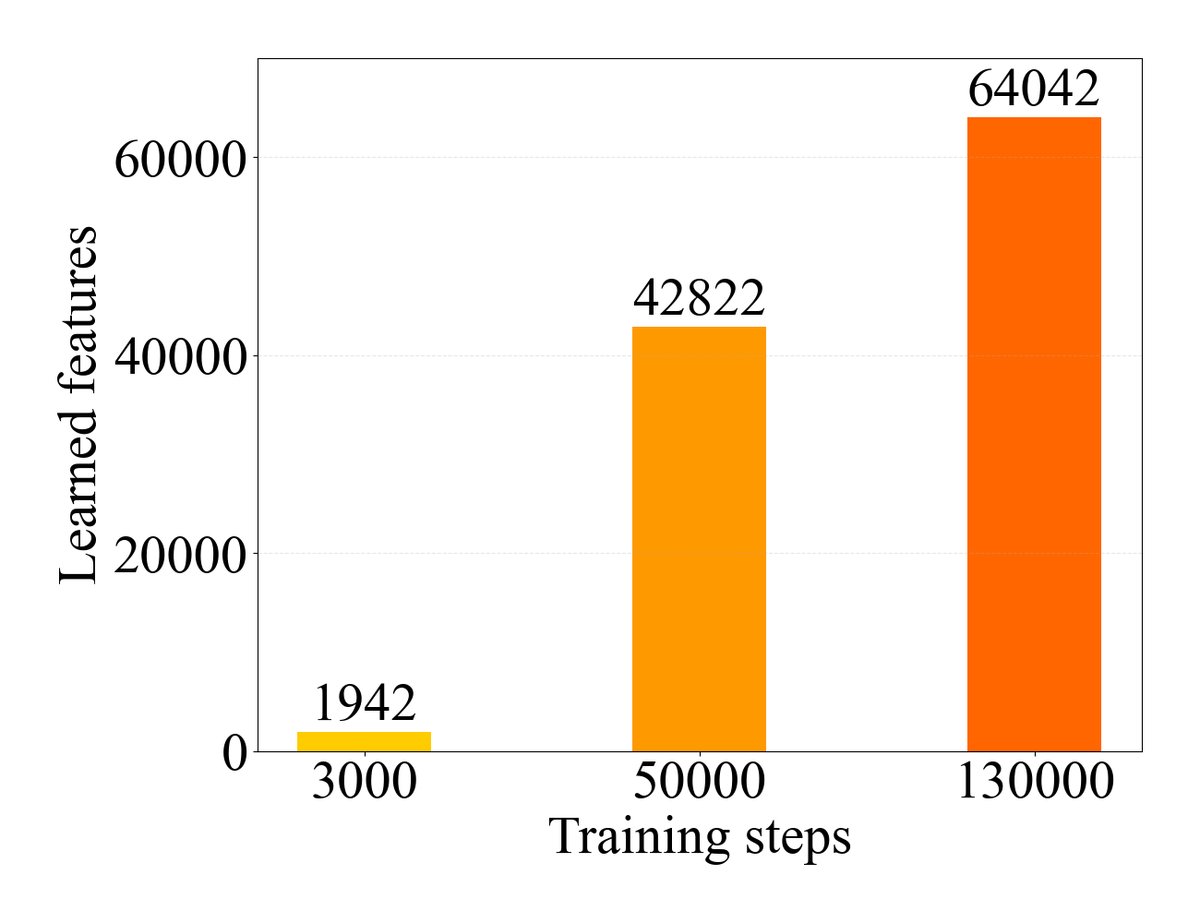
通过在训练过程中的不同检查点(早期、中期、晚期)上训练SAE,作者发现模型的特征数量随训练步数增加而显著增长。这直观地展示了“记忆巩固”是一个特征不断扩张的过程。
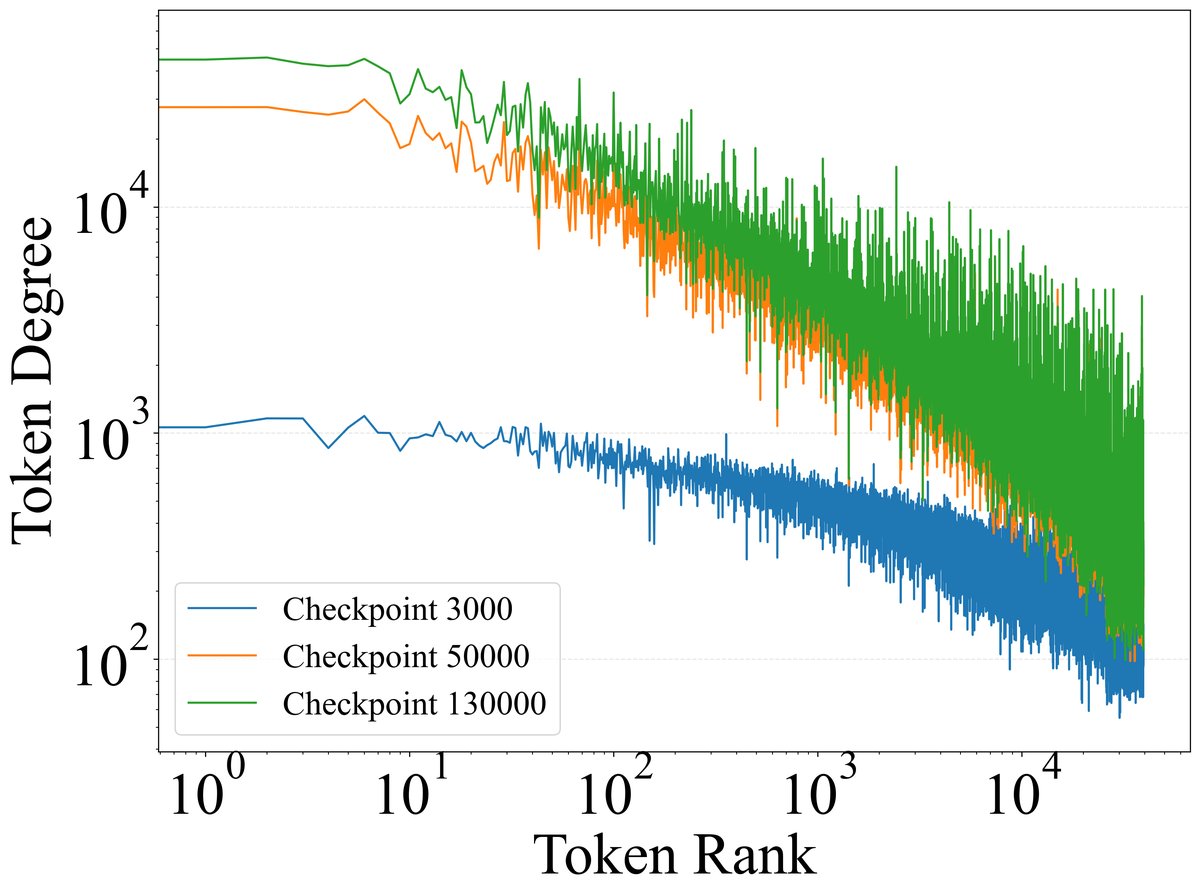
同时,对不同阶段的Token-特征图分析显示,虽然总特征数在增加,但功能性Token始终是激活绝大多数特征的主力,且这种主导地位随着训练的深入而愈发明显。
创新点2:损失函数动态分析
本文将下一个Token的预测任务根据“当前Token”和“下一个Token”的类型,划分为四类:
- \(function→function\) (功→功)
- \(function→content\) (功→内)
- \(content→function\) (内→功)
- \(content→content\) (内→内)
通过追踪这四类任务的损失 (loss) 变化,发现了几个关键现象: 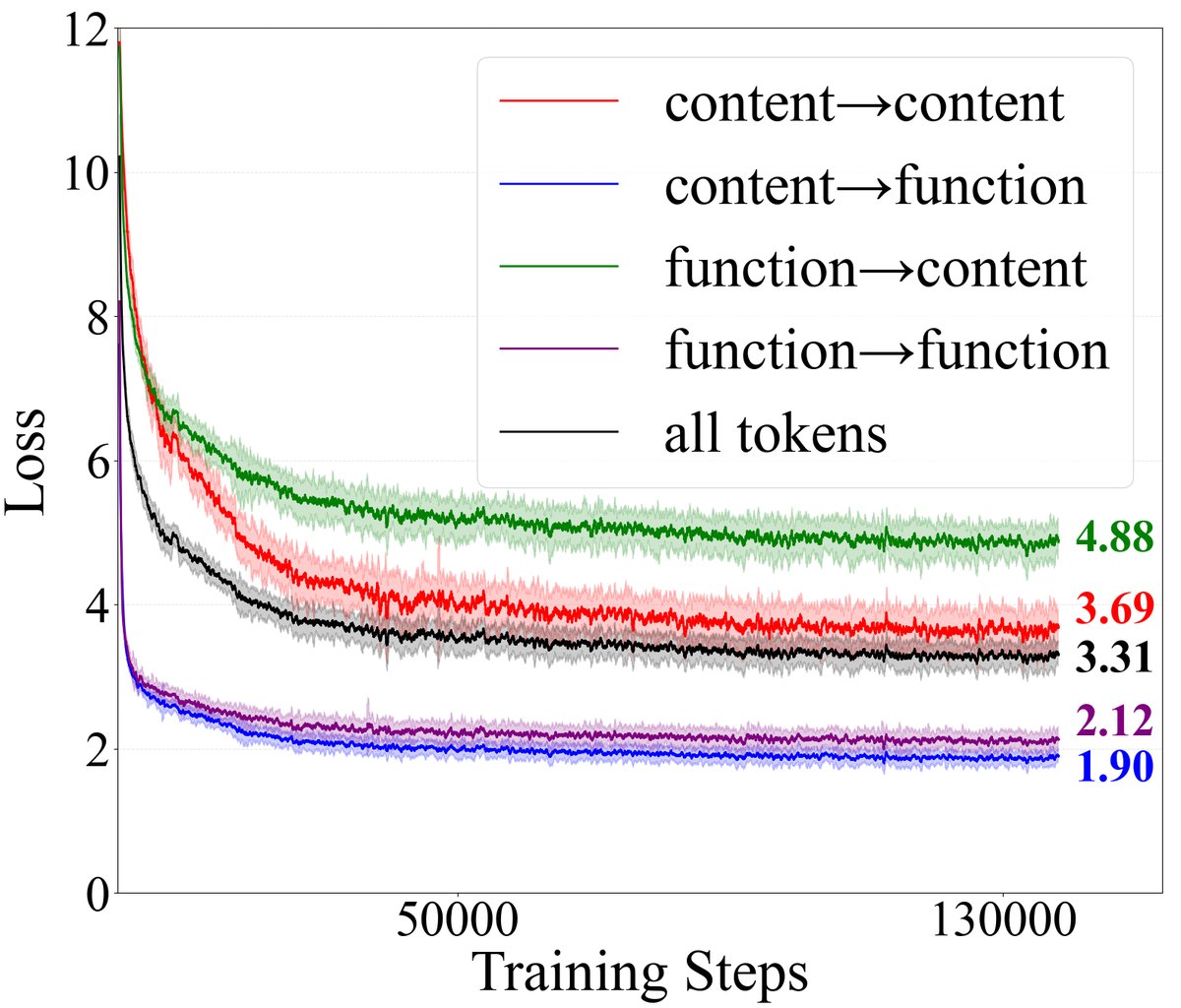
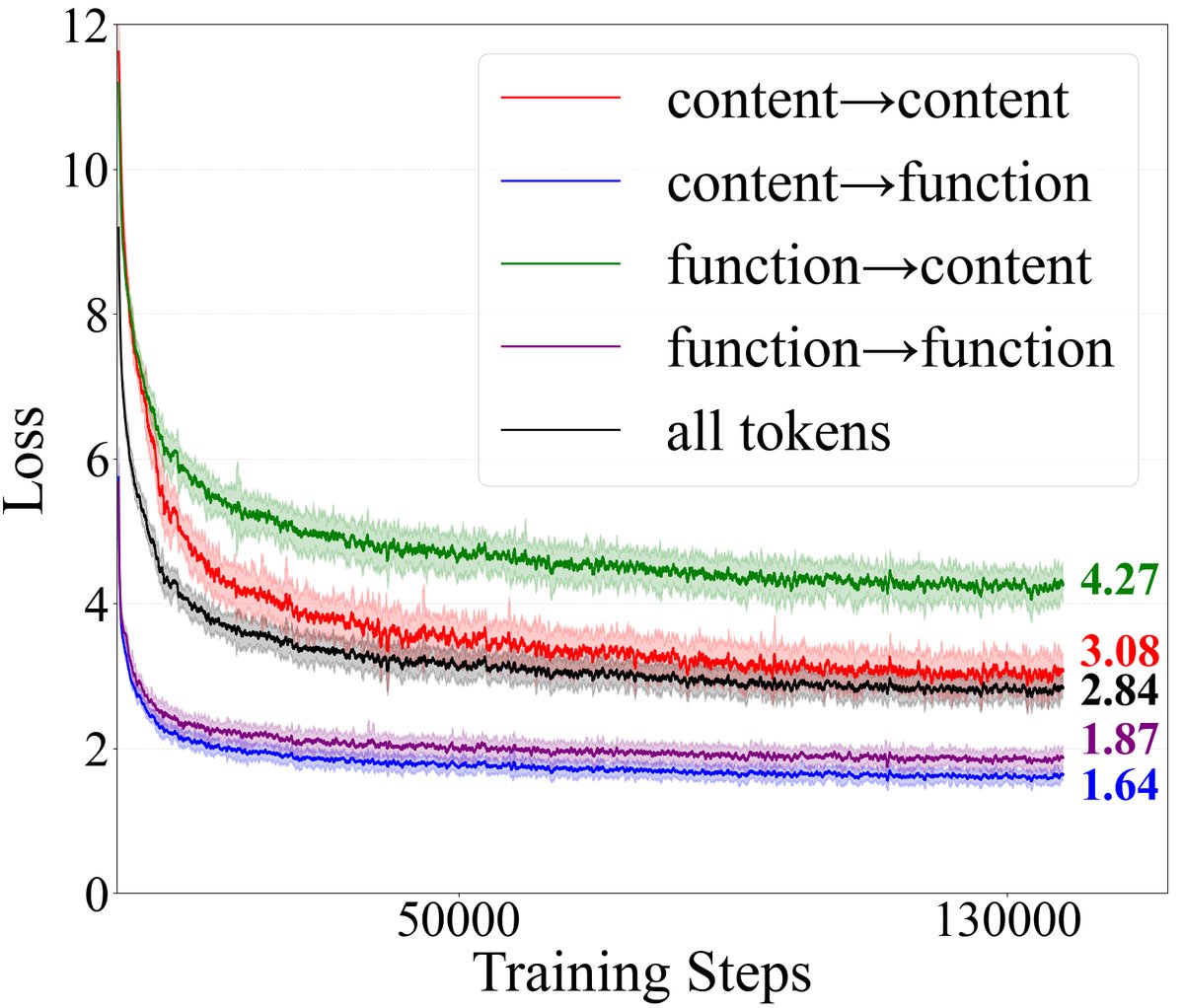
- \(function→content\)的损失最高:在整个训练过程中,预测功能性Token之后的\(内容性Token\)是最困难的任务,其损失值远高于其他三类。这意味着模型优化的主要压力来自于此。为了降低这个损失,模型被迫让功能性Token学会从上下文中提取和激活最有效的预测性特征。这正是功能性Token强大能力习得的根源。
- 模型先学会预测功能性Token:在训练早期,预测功能性Token(\(→function\))的损失下降最快并迅速收敛到很低的水平。这表明模型首先掌握了语言的语法结构和基本流。
- 模型规模主要提升内容预测能力:从1.5B扩展到8B模型,对预测功能性Token的提升有限,但对预测内容性Token(尤其是\(function→content\))的损失降低幅度最大。这说明增加模型参数主要用于增强其表达和预测复杂语义内容的能力。

上图展示了模型在不同训练阶段的生成演变,从早期只会生成功能性Token,到中期生成连贯短语,再到后期能够处理长距离依赖,这与损失分析的结论一致。
实验结论
本文通过一系列广泛的实验,为所提出的“功能性Token假说”提供了强有力的证据。
- 验证了功能性Token在记忆检索中的核心作用:
- 通过Token-特征二部图分析,实验证明了极少数功能性Token(如标点、冠词)激活了模型中大部分的特征。
- 案例研究和特征干预实验进一步揭示,功能性Token能够根据上下文动态地再激活(reactivate)最具预测性的特征,从而精确地引导后续内容的生成。
- 揭示了功能性Token在记忆巩固中的驱动机制:
- 预训练过程分析显示,模型的特征库会随着训练而扩张。
- 关键的发现是,\(function→content\)(预测功能性Token之后的下一个内容性Token)这一任务的训练损失最高,构成了模型优化的主要压力。正是这种压力,迫使功能性Token演化出强大的特征激活能力,从而驱动了整个模型的记忆巩固过程。
- 效果与场景:
- 本文的方法在解释LLM的内部工作机制方面表现出色,其结论在不同模型大小(1.5B, 8B, 9B)、不同分析层面(图分析、损失动态、案例研究)都得到了一致的验证。
- 文章并未提及该假说不适用的场景,其提供的证据链条相当完整和具有说服力。
- 最终结论: 本文成功提出了一个简洁而深刻的“功能性Token假说”,系统地解释了LLM中记忆检索和巩固两大核心机制。这一假说不仅加深了我们对LLM工作原理的理解,也为未来设计更高效的训练算法和对齐技术提供了新的理论视角。