Mid-Training of Large Language Models: A Survey
-
ArXiv URL: http://arxiv.org/abs/2510.06826v1
-
作者: Weiwei Weng; Yuxin Shi; Zhiqiang Zhou; Anxiang Zeng; Haibo Zhang
-
发布机构: Nanyang Technological University; Shopee
TL;DR
本文首次将大语言模型(LLMs)的中期训练(mid-training)概念化为一个统一的范式,并提出了一个涵盖数据分布、学习率调度和长上下文扩展的分类体系,旨在系统性地梳理这一介于大规模预训练和任务微调之间的关键阶段。
关键定义
本文的核心是系统性地定义和归纳“中期训练”这一阶段,并未引入全新的技术术语,而是对现有实践中的关键概念进行了整合与界定:
- 中期训练 (Mid-Training):一个介于通用大规模预训练(pre-training)和特定任务微调(fine-tuning)之间的中间训练阶段。其核心特征是采用退火式(annealing-style)策略,包括调整数据质量、优化学习率和扩展上下文长度,旨在从宽泛的知识记忆转向更深层次的抽象和推理能力。
- 数据退火 (Data Annealing):在中期训练阶段,逐步改变训练数据的分布,减少低质量、高噪声数据的比例,同时增加高质量、知识密集型或特定能力导向(如代码、数学、推理)数据的权重。这是中期训练中优化数据分布的核心策略。
- 学习率退火 (Learning Rate Annealing):在训练后期,当模型接近最优解区域时,平滑地降低学习率。此举旨在抑制梯度噪声,稳定收敛过程,并帮助模型更好地吸收高质量数据中的精细信息。
引言
近期的大语言模型(LLM)训练流程中,中期训练(mid-training)已成为一个连接通用预训练(pre-training)和特定任务有监督微调(Supervised Fine-Tuning, SFT)的关键延续阶段。顶尖模型不再仅仅依赖于提供广泛但充满噪声监督信号的网页级语料库,而是越来越多地采用一种退火式(annealing-style)的训练阶段来改善优化动态并提升数据质量。
这一阶段的动机源于实践和理论两方面:降低学习率可以减轻梯度方差,使模型在接近有利的最优解时稳定收敛;转向更精选或合成的语料库,则能提高每个额外Token的边际效用。若无此调整,模型的能力发展常会停滞,即便投入大量额外计算,在推理、编码和长上下文理解方面的提升也十分有限。
中期训练的有效性有其理论基础,它通过强调结构化推理、事实性和指令遵循,促使模型从记忆转向抽象。本文从三个理论视角总结了这一现象:
- 梯度噪声尺度 (gradient noise scale):高质量数据通过增强信号方差来改善优化,缓解过拟合平台期。
- 信息瓶颈 (information bottleneck):模型在压缩嘈杂特征的同时保留与预测相关的结构。
- 课程学习 (curriculum learning):逐步优化数据分布,以强化复杂的推理能力。
这些理论共同为中期训练作为一种提升泛化能力和训练效率的策略提供了坚实的理论依据。尽管中期训练的应用日益广泛且效果显著,但此前尚无研究将其作为一个连贯的范式进行全面综述。
本文旨在填补这一空白,对中期训练策略进行综合性回顾,并围绕数据分布、优化调度和上下文扩展这三个相互关联的领域构建了一个统一的框架。本文的主要贡献如下:
- 首次提出一个基于数据分布、学习率调度和长上下文扩展三大领域的LLM中期训练分类体系。
- 总结了每个领域的宝贵见解,为未来的研究和实践提供参考。
- 讨论了通用的评估基准,并收集了不同模型的性能增益报告,以便进行结构化比较。
- 勾勒了LLM中期训练未来有前景的研究方向和潜在的推进路径。
理论动机
中期训练的核心逻辑在于将模型的学习动态从记忆(memorization)转向抽象(abstraction)。当模型从大规模通用数据中泛化的能力接近极限时,高质量样本能够通过强化对结构化推理、事实性和指令遵循的关注,带来进一步的能力提升。以下是支撑这一方法的几个理论基础。
梯度噪声尺度
先前研究表明,梯度噪声尺度(Gradient Noise Scale, GNS)反映了每一步更新中的有效信号量。高质量数据通常能引发更大的梯度方差,从而产生更高的GNS;而冗余或噪声数据则会降低这种方差。较大的GNS有助于模型逃离尖锐的局部最小值,避免在低质量的平台区过拟合,这在信号稀疏可能导致收敛停滞的训练后期尤为重要。
信息瓶颈
在信息瓶颈(Information Bottleneck, IB)框架下,神经网络的表示学习可被视为一个在保留任务相关信息的同时压缩内部状态的过程。在学习率退火阶段,模型逐渐减少对噪声或冗余特征的依赖。高质量的监督信号提供了更清晰、低熵的指导,有助于识别有意义的语义结构并削弱虚假关联,从而促进模型从大规模记忆转向更抽象、可泛化的表示。
课程学习
学习率退火与课程学习(Curriculum Learning)的原则天然契合。早期预训练让模型接触多样化和嘈杂的语料以实现泛化,之后数据分布可以逐渐转向更具挑战性和信息量的样本——这正是课程学习式调度的作用。这种结构化的进阶过程有助于优化学习效率,并已被证明可以强化如多步推理和代码生成等复杂技能。
中期训练的数据分布
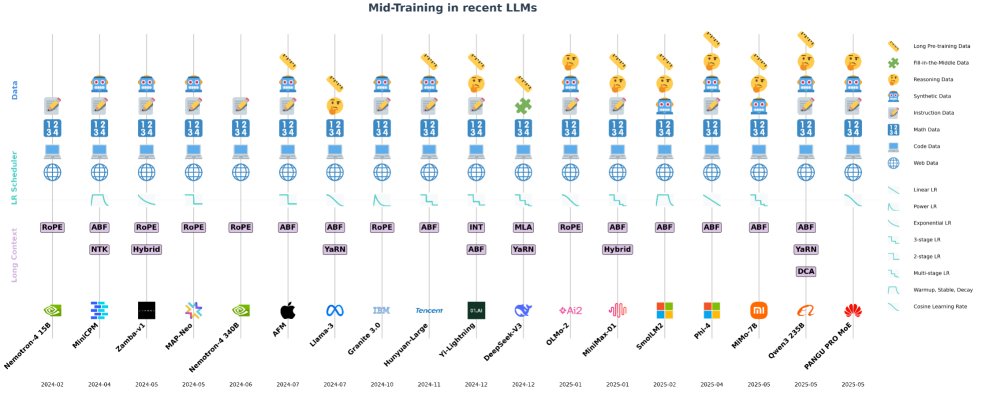
本节研究了当前顶尖LLM方法在中期训练阶段所使用的数据集分布与质量。
数据分布与质量
在中期训练阶段,数据质量的优先级被大大提高,以精炼模型能力、改善对齐并优化下游任务性能。根据当前顶尖LLMs的实践,中期训练数据可大致分为以下几类:
-
精选网络语料 (Curated Web Corpora) 模型广泛使用经过精心筛选的网页语料库子集。这些数据基于内容质量、主题多样性、低毒性、教育价值和最小冗余度等严格标准进行过滤。常用数据集包括 CommonCrawl、C4、Wikipedia、Dolma 等的精选版本,如 FineWeb-Edu、RefinedWeb、SlimPajama 等。
-
代码与数学数据 (Code and Math Data) 代码和数学数据能显著增强模型的符号推理和程序合成能力。这些数据来自开源代码库、编程基准测试以及数学问答对或推导过程。代表性数据集包括 The Stack v1/v2,以及更高质量的过滤版本如 OpenWebMath、FineMath 等。
-
指令遵循与问答数据 (Instruction-following and QA-style Data) 这类数据在中期训练中越来越普遍,通常包含合成或精选的问答对、指令-响应对。其目的是增强模型对人类意图的理解,提高响应的一致性并加强推理能力。数据集例子有 Ultrachat、EvolInstruct、OpenOrca 等。
-
合成教科书式与知识密集型数据 (Synthetic Textbook-style and Knowledge-dense Data) 这类数据通过提供高质量的教育内容来增强LLM,尤其是在数学、编码和多语言等低资源领域。它们通常由更强的LLM基于高质量种子生成,旨在丰富模型的事实知识、解释能力和教学性结构。代表性数据集包括 Cosmopedia、OpenHermes-2.5 等。
-
长上下文数据 (Long-context Data) 为支持长文档理解、多文件推理等任务,中期训练会引入长上下文文档或长问答数据。这些数据要么从现有语料库中筛选,要么通过数据合成获得,用以提升模型的记忆力、连贯性和跨文档推理能力。
-
推理数据 (Reasoning Data) 使用推理数据,如思维链(Chain-of-Thought, CoT)标注,已成为一种趋势。这类数据通过明确展示如何将复杂问题分解为小步骤,帮助模型学习结构化的、可解释的推理模式,而不是仅仅依赖表层线索。
-
填充-在-中间 (Fill-in-the-Middle, FIM) 数据 FIM 策略在不损害下一个Token预测能力的同时,使模型能根据上下文准确预测中间的文本。在中期训练阶段,FIM数据能强制模型进行双向上下文推理,加强长距离依赖建模,并提高数据效率,特别适用于高质量数据稀缺的训练后期。
数据混合策略比较
本节回顾并比较了主流模型在中期训练阶段采用的数据集。
- Qwen3:经过30T Tokens的初级预训练后,进行5T Tokens的高质量中期训练,增加了STEM、编码、推理和合成数据的比例;最后是数百B Tokens的长上下文训练。
- Phi4: 在约10T Tokens预训练后,中期训练阶段包含75B的精选长上下文Tokens和175B的早期优质数据。第二阶段混合了合成Tokens和少量超精选的推理导向网络数据。
- Llama3 405B:在15T Tokens预训练后,包含一个800B Tokens的长上下文阶段和一个40M Tokens的退火阶段,退火阶段上采样了最高质量的数据源。
- Apple Foundation Model (AFM):在6.3T Tokens预训练后,进行1T Tokens的退火阶段,该阶段降权低质量网页数据,增权代码和数学数据;随后是100B Tokens的长上下文阶段。
- Deepseek-V3:在14.8T Tokens预训练后,进行了两轮上下文扩展,分别在60B Tokens上将序列长度扩展到32K和128K。
- SmolLM2:在11T Tokens的多阶段预训练后,退火阶段加入了1T高质量Tokens(包含网络、代码、数学和合成教科书数据),最后用75B Tokens进行长上下文扩展。
- Nemotron-4:在8T Tokens的通用预训练后,进行1T Tokens的中期训练。该阶段主要重加权预训练见过的高质量数据,并引入少量QA对齐样本。
- OLMo 2:在约5T Tokens的预训练后,中期训练阶段使用更小但更高质量的Dolmino Mix数据集,并采用多次重复训练取平均的方式来最大化泛化能力。
- Yi-Lightning:采用三阶段训练:通用预训练、退火阶段(上采样高质量和推理数据)和快速衰减阶段(强化高质量数据并引入早期指令调优)。之后再进行20B Tokens的长上下文训练。
- Zamba-v1:在950B Tokens的预训练后,中期训练阶段混合了60%的预训练数据和40%的高质量数据集,覆盖数学、代码、指令等领域。
- Pangu Pro MoE: 采用三阶段过程:通用阶段(9.6T)、推理阶段(3T,强化STEM、代码和CoT数据)和退火阶段(0.4T,精炼行为)。
- Hunyuan-Large:在7T Tokens预训练后,退火阶段使用5%最高质量的预训练Tokens,之后再进行长上下文训练,语料包含25%的自然长文本数据。
- MiniCPM:在1T Tokens的粗略预训练后,中期训练阶段使用20B Tokens,混合了预训练数据和高质量的知识/能力导向SFT数据。
- MAP-Neo: 在4.5T Tokens通用预训练后,中期训练增加了778B高质量Tokens,更加强调指令和代码数据。
- MiMo-7B:三阶段策略,在通用阶段后,退火阶段将数学和代码数据比例提升至70%,长上下文阶段则加入约10%的合成数据并扩展上下文长度。
关键洞见
与注重规模和覆盖范围的早期预训练不同,中期训练阶段强调质量。
-
质量优于数量:消融研究证实,经过筛选的语料库始终优于未经过滤的语料库。同时,不同的高质量数据集具有互补优势(例如,FineWeb-Edu在学术基准上表现优异,而DCLM在常识推理上更佳),因此混合多种高质量来源至关重要。
-
高价值数据的上采样:增加高质量指令和教育内容通常能改善推理和连贯性。LLaMA3通过增强可靠的指令数据提升了长上下文推理能力。然而,何时引入这些数据最有效仍是一个开放问题。
-
长上下文优化的平衡:研究发现,仅在长数据上训练可能会损害模型性能,与高质量短上下文数据进行平衡混合至关重要。此外,自然形成的长篇内容(如书籍、代码)在长上下文推理任务上的效果优于人工拼接的数据。
-
领域数据的杠杆效应:OLMo 2发现,即使在中期训练混合数据中只加入一小部分领域特定数据(如数学和编码),也能带来不成比例的性能提升,这再次印证了此阶段“质量重于数量”的原则。
-
合成数据的价值:合成数据不仅能扩充数据量,还能针对性地弥补现有语料库在某些领域(如复杂推理)的不足,从而在不扩大原始语料库规模的情况下,放大中期训练的学习效率。
-
推理数据的有效性:包含逐步推理过程的高质量数学语料(如FineMath4+)能让模型内化结构化的推理模式,从而在数学问题解决上取得显著提升。
-
数据重复与重写:OLMo 2等研究发现,适度重复高价值数据(如数学题)可以提升性能。同时,将任务重写为更易于模型处理的格式(如内联注释)能显著改善表现。
-
避免灾难性遗忘:OpenCoder的研究强调,在中期训练中引入新数据分布时,需要保留大部分原始预训练数据以确保知识的连续性,避免因分布剧变导致的灾难性遗忘。