Mistral 7B
-
ArXiv URL: http://arxiv.org/abs/2310.06825v1
-
作者: Alexandre Sablayrolles; Lucile Saulnier; Timothée Lacroix; Devendra Singh Chaplot; L’elio Renard Lavaud; Guillaume Lample; Albert Qiaochu Jiang; A. Mensch; Chris Bamford; Florian Bressand; 等8人
TL;DR
本文介绍了一个名为 Mistral 7B 的70亿参数语言模型,它通过利用分组查询注意力(GQA)和滑动窗口注意力(SWA)机制,在保持高效率的同时,实现了在各项基准测试中超越更大参数模型(如 Llama 2 13B)的卓越性能。
关键定义
本文主要沿用并组合了现有的关键技术,其核心在于这些技术的创新性结合应用,以实现性能与效率的平衡。关键概念包括:
-
分组查询注意力 (Grouped-Query Attention, GQA):一种注意力机制的变体。在标准的多头注意力(Multi-Head Attention)中,每个查询头(query head)都有一组独立的键(key)和值(value)头。而在 GQA 中,多个查询头被分在一组,共享同一组键和值头。这种方法是多头注意力和多查询注意力(Multi-Query Attention)之间的一种折中,旨在显著加快推理速度并减少解码过程中的内存需求,同时保持较高的模型质量。
-
滑动窗口注意力 (Sliding Window Attention, SWA):一种为处理长序列而设计的注意力机制。在这种机制下,每个 token 在计算注意力时,不再关注序列中所有的历史 token,而是只关注其前面一个固定大小为 \(W\) 的窗口内的 token。由于 Transformer 的层是堆叠的,信息可以在多层之间传递,使得模型在 \(k\) 层之后,实际的注意力感受野可以达到 \(k * W\),从而在有效处理长序列的同时,将计算成本从序列长度的二次方降低到线性级别。
-
滚动缓冲区缓存 (Rolling Buffer Cache):一种为配合滑动窗口注意力而设计的 KV 缓存管理策略。由于 SWA 的注意力窗口大小是固定的,因此 KV 缓存的大小也可以是固定的。该缓存像一个环形缓冲区,大小为 \(W\),新的键/值对会覆盖掉最旧的键/值对(具体来说,时间步 \(i\) 的 KV 存放在缓存的 \(i mod W\) 位置)。这极大地减少了处理长序列时的内存占用,例如,在32k长度的序列上可将缓存内存降低8倍。
相关工作
当前自然语言处理领域(NLP)的主流趋势是通过扩大模型规模来提升性能。然而,这种“越大越好”的策略导致了计算成本和推理延迟的急剧增加,为模型的实际部署带来了巨大障碍。领域内的关键瓶颈在于如何在不牺牲性能的前提下,提高模型的运行效率,使其更易于在真实世界场景中应用。
本文旨在解决的核心问题是:如何设计一个参数量相对较小(70亿)的语言模型,使其在性能上能够媲美甚至超越参数量远大于它的模型(如 Llama 2 13B),同时具备更高的推理效率和更低的部署成本。
本文方法
Mistral 7B 是一个基于 Transformer 架构的语言模型。其核心设计在于通过架构上的优化,实现性能与效率的极致平衡。
| 参数 | 值 |
|---|---|
| 维度 (dim) | 4096 |
| 层数 (n_layers) | 32 |
| 注意力头维度 (head_dim) | 128 |
| 隐藏层维度 (hidden_dim) | 14336 |
| 注意力头数量 (n_heads) | 32 |
| KV头数量 (n_kv_heads) | 8 |
| 窗口大小 (window_size) | 4096 |
| 上下文长度 (context_len) | 8192 |
| 词汇表大小 (vocab_size) | 32000 |
创新点
本文方法的本质创新在于巧妙地结合了两种注意力机制——GQA 和 SWA——并辅以高效的缓存策略,从而在小模型上实现了越级的性能表现。
1. 滑动窗口注意力 (Sliding Window Attention, SWA)
为了解决标准 Transformer 在处理长序列时注意力计算成本呈二次方增长的问题,Mistral 7B 采用了 SWA。每个 token 只关注其前 \(W\) 个 token(本文中 \(W=4096\))。这种机制有两大优势:
- 降低计算成本:将注意力计算的复杂度从 $O(N^2)$ 降低到 $O(N \times W)$,使其与序列长度成线性关系。
- 扩展有效注意力范围:虽然单层的窗口大小有限,但通过堆叠多层 Transformer,信息可以逐层向前传递。经过 \(k\) 层后,一个 token 的信息可以影响到 \(k \times W\) 距离外的 token。以本文32层的配置为例,理论上的注意力跨度可达 \(32 \times 4096\) ≈ 131K token,极大地增强了模型处理长文本的能力。
- 实际加速:结合 FlashAttention 和 xFormers 的优化,在16K序列长度下,SWA 比普通注意力的实现快2倍。
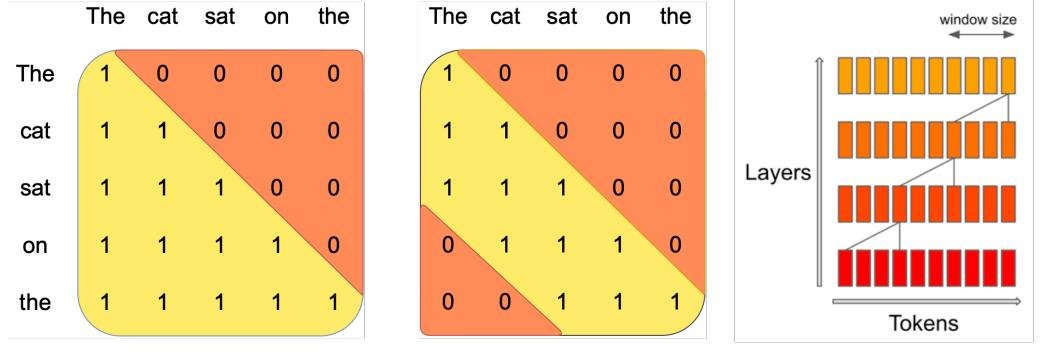 图1:滑动窗口注意力。每个 token 最多关注前 W 个 token(图中 W=3)。信息通过多层堆叠向前传播,在 k 层后,信息可向前传播 k×W 个 token。
图1:滑动窗口注意力。每个 token 最多关注前 W 个 token(图中 W=3)。信息通过多层堆叠向前传播,在 k 层后,信息可向前传播 k×W 个 token。
2. 滚动缓冲区缓存 (Rolling Buffer Cache)
SWA 的固定注意力窗口特性使得一种高效的缓存管理成为可能。模型无需为序列中所有的历史 token 存储键(Key)和值(Value)。取而代之的是,本文使用一个大小固定的滚动缓冲区,其大小等于窗口 \(W\)。当生成第 \(i\) 个 token 时,其对应的 KV 对被存储在缓存的 \(i \mod W\) 位置。当 \(i\) 大于 \(W\) 时,新的 KV 对会覆盖掉缓存中最旧的数据。
这一设计极大地减少了长序列推理时的内存占用,例如在处理 32k 长度的序列时,相比传统方法可节省8倍的缓存内存,且不影响模型质量。
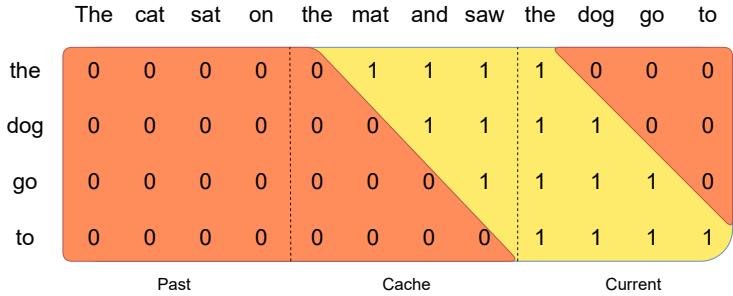
 图2:滚动缓冲区缓存。缓存大小固定为 W=4。位置 i 的键值对存储在缓存的 \(i mod W\) 位置。当 i > W 时,旧值被覆盖。
图2:滚动缓冲区缓存。缓存大小固定为 W=4。位置 i 的键值对存储在缓存的 \(i mod W\) 位置。当 i > W 时,旧值被覆盖。
3. 预填充与分块 (Pre-fill and Chunking)
在生成文本时,输入的提示(prompt)是已知的。模型可以预先计算并填充整个提示的 KV 缓存,这个过程称为“预填充”。如果提示非常长,可以将其分割成与窗口大小 \(W\) 相等的块,然后逐块计算并填充 KV 缓存。这种方法保证了即使在处理超长输入时,计算也能高效进行。
指令微调
除了基础模型外,本文还展示了一个在其之上微调的指令遵循模型 Mistral 7B – Instruct。该模型仅使用 Hugging Face 上的公开指令数据集进行微调,没有使用任何专有数据或特殊的训练技巧,证明了基础模型强大的可微调性和泛化能力。
实验结论
关键结果
Mistral 7B 在广泛的基准测试中表现出色,其性能不仅超越了同等规模的模型,甚至优于许多参数量更大的模型。
- 综合性能对比:在所有评估的基准测试中,Mistral 7B 的性能全面超越了 Llama 2 13B。在数学、代码生成和推理任务上,它也优于 Llama 1 34B。
- 代码能力:Mistral 7B 的代码生成能力接近专门为代码优化的 Code-Llama 7B,同时在非代码任务上没有性能损失。
- 指令遵循能力:经过微调的 Mistral 7B – Instruct 模型在 MT-Bench 上优于所有 7B 级别的聊天模型,并与 Llama 2 13B – Chat 等 13B 级别的聊天模型表现相当。在匿名的在线人类评估中,Mistral 7B – Instruct 的回答也比 Llama 2 13B – Chat 更受用户青睐。
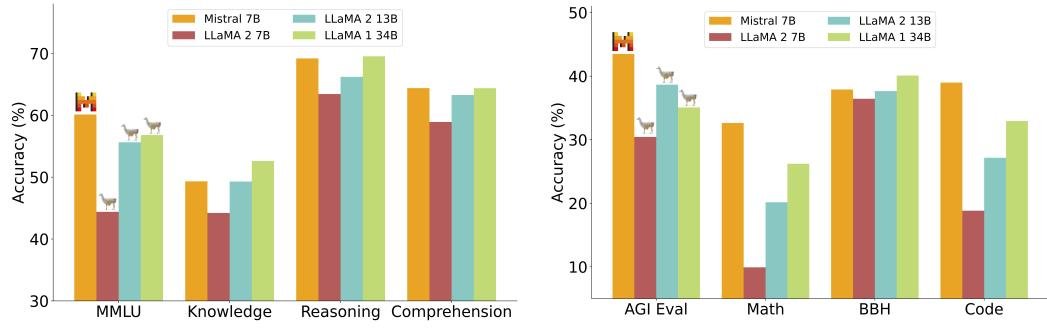 图4:Mistral 7B 与不同 Llama 模型在各类基准测试上的性能对比。Mistral 7B 在所有基准上显著优于 Llama 2 7B/13B,并在数学、代码和推理上超越 Llama 1 34B。
图4:Mistral 7B 与不同 Llama 模型在各类基准测试上的性能对比。Mistral 7B 在所有基准上显著优于 Llama 2 7B/13B,并在数学、代码和推理上超越 Llama 1 34B。
优势验证
- 尺寸和效率:通过“等效模型尺寸”分析,发现在推理、理解和STEM推理(MMLU)等任务上,Mistral 7B 的表现相当于一个尺寸是其 3倍以上 的 Llama 2 模型。这证明了其架构设计在性能与参数效率上的巨大成功。
- 安全性和可控性:通过系统提示(system prompt),可以有效地为模型行为增加“护栏”,使其在面对不安全问题时拒绝回答。同时,模型本身具备“自我反思”进行内容审核的能力,能够准确地对黄、赌、毒、暴等内容进行分类,准确率高达99.4%。
存在的局限
- 知识存储限制:尽管在推理和代码等任务上表现优异,但在需要大量世界知识的基准测试中,Mistral 7B 的性能“压缩率”较低(相当于1.9倍大小的 Llama 2 模型)。这可能是因为其 7B 的参数量限制了它能够存储的知识总量。
总结
本文成功证明,通过精巧的架构设计(特别是 SWA 和 GQA 的结合),较小的语言模型也能够实现极高的知识和能力压缩率。这表明,评估模型不再仅仅是“训练成本 vs. 模型能力”的二维问题,而应该被看作一个包含“模型能力、训练成本、推理成本”的三维问题。Mistral 7B 在这个三维空间中找到了一个极具竞争力的平衡点,为开发更经济、高效且强大的语言模型开辟了新的思路。