Mitigating Hallucination in Large Language Models (LLMs): An Application-Oriented Survey on RAG, Reasoning, and Agentic Systems
-
ArXiv URL: http://arxiv.org/abs/2510.24476v1
-
作者: Ghanshyam Verma; Paul Buitelaar; Mingming Liu; Yihan Li
-
发布机构: Dublin City University; University of Galway; Wuhan University
TL;DR
本文是一篇以应用为导向的综述,系统性地分析了检索增强生成(RAG)、推理增强以及智能体(Agentic Systems)系统如何通过提升模型能力来缓解大型语言模型(LLM)中的知识型和逻辑型幻觉。
分类体系
本文提出了一个面向幻觉缓解策略的分类体系,将幻觉分为两大类:
- 知识型幻觉 (Knowledge-based Hallucination):指模型生成的内容与事实不符。这通常源于模型内部知识的缺失、过时或错误。
- 逻辑型幻觉 (Logic-based Hallucination):指模型生成的内容在逻辑上不一致或推理过程存在缺陷。这通常发生在需要多步推导或复杂问题分解的任务中。
该分类体系的构建旨在将不同类型的幻觉与最有效的缓解策略(RAG 对应知识型,推理增强对应逻辑型)进行匹配,从而为实际应用提供清晰的指导。

相关综述回顾
本文首先回顾了以往的相关研究,并将其分为两大类:面向幻觉的综述和面向技术的综述。
- 面向幻觉的综述:先前的工作(如 Zhang et al. [2], Huang et al. [1])系统地总结了幻觉的成因、缓解策略和评估方法,但很少从增强系统能力的角度进行审视,特别是忽略了推理能力对缓解幻觉的影响。这些研究大多将幻觉视为需要被抑制的错误,有时会以牺牲模型的通用性和创造力为代价。
- 面向技术的综述:虽然已有关于 RAG、推理和智能体的综述,但它们大多停留在理论层面,缺乏对这些技术缓解幻觉有效性的实证或概念评估。
本文的独特之处在于,它采用了一种以能力增强为导向的分析框架。它不再将幻觉仅仅看作是需要消除的错误,而是探讨如何通过整合外部知识(RAG)和强化逻辑一致性(推理)来提升模型的可靠性。这种视角旨在弥合现有研究的碎片化,建立一个连接方法、系统与应用的统一框架,为现实世界中开发更可靠的 LLM 提供指导。

背景与关键概念
大型语言模型 (LLMs)
大型语言模型(Large Language Models, LLMs)是基于 Transformer 解码器架构构建的深度学习模型,通过在海量文本语料上进行自回归的下一个词元(token)预测来生成文本。这种基于统计相关性的生成机制赋予了模型强大的生成和泛化能力,但其固有的随机性和不确定性也是幻觉产生的主要根源之一。
幻觉 (Hallucination)
幻觉指模型生成看似合理但实际上与事实不符、逻辑不通或不符合用户指令的内容。这一问题严重影响了 LLM 在医疗、法律、金融等高风险领域的可靠性和可信度。研究普遍认为,完全消除幻觉几乎不可能,因为它与驱动模型创造力的机制同源。因此,缓解(mitigation)而非消除幻愈已成为现实目标。
检索增强生成 (RAG)
检索增强生成(Retrieval-Augmented Generation, RAG)是在模型推理阶段从外部知识源检索信息以辅助内容生成的技术。它不仅能弥补模型预训练阶段的知识短板,还能纠正内部错误、实现知识的快速更新、提高答案的可追溯性,是缓解知识密集型任务中幻觉的强大方案。
推理 (Reasoning)
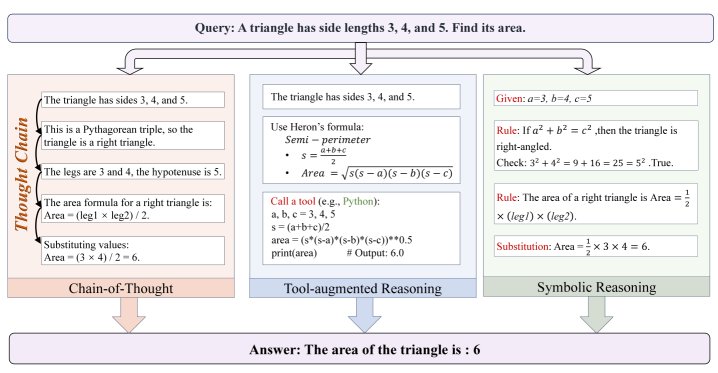
推理是指 LLM 动态解释复杂指令、分解子目标、构建连贯严谨的逻辑链,并遵循结构化步骤完成任务的能力。本文重点关注三种代表性的推理形式:
- 思维链 (Chain-of-Thought, CoT):通过提示引导模型生成中间推理步骤,以增强逻辑连贯性。
- 工具增强推理 (Tool-augmented Reasoning):利用计算器、搜索引擎等外部工具来提高解决问题的准确性。
- 符号推理 (Symbolic Reasoning):将自然语言转化为符号表示,以进行可验证的、基于逻辑的计算。
RAG缓解知识型幻觉
知识型幻觉源于模型内部知识的不准确或外部信息的不足。RAG 通过引入外部知识,成为增强事实一致性和可靠性的核心框架。本节围绕 RAG 流程,分析其如何缓解知识型幻觉。
RAG 流程与关键技术
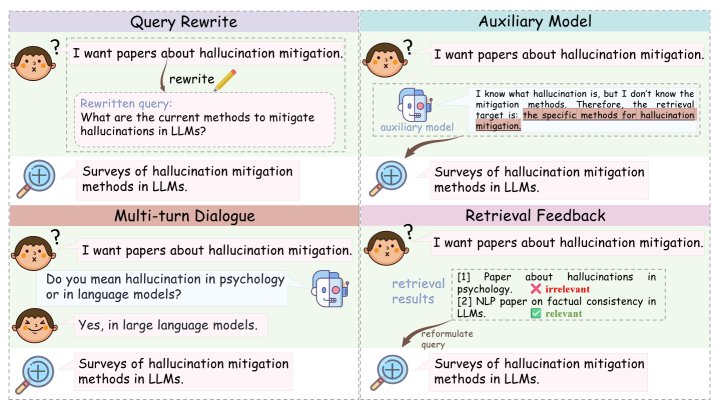
前检索 (Pre-retrieval)
此阶段的核心任务是理解用户查询的真实意图,以制定更具针对性的检索策略。关键技术包括:
- 查询重写 (Query rewrite):将原始查询改写为更适合检索的形式,弥合输入文本与所需知识之间的差距。
- 辅助模型 (Auxiliary models):利用轻量级辅助模型预先生成初步答案,从而识别出需要检索的缺失知识。
- 多轮对话 (Multi-Turn dialogue):在多轮对话中,利用历史上下文来重建更有效的查询,以准确理解用户意图。
- 检索反馈 (Retrieval feedback):系统根据已检索到的结果或生成的内容,迭代地修正和重构初始意图,从而提升后续检索的准确性。
检索 (Retrieval)
此阶段的核心是检索器(retriever)根据查询精确高效地定位相关知识。其性能受以下因素影响:
- 检索器类型:
- 稀疏检索器 (如 BM25):基于关键词匹配,速度快、可解释性强,但难以处理语义变化。
- 密集检索器 (如 DPR, Contriever):通过编码器捕捉语义关系,但计算成本高。
- 混合检索器 (如 ColBERTv2):结合稀疏和密集方法的优点,通过融合词汇和语义信号,在复杂任务中表现更优,是未来的重要发展方向。
| 检索器类别 | 工作机制 | 代表性模型 | 优点 | 缺点 |
|---|---|---|---|---|
| 稀疏检索器 | 基于词汇匹配(如关键词频率)。 | BM25 [95], TF-IDF [96], SPLADE [97] | 计算效率高,可解释性强,对特定关键词查询效果好。 | 无法理解语义相似性,对措辞变化敏感。 |
| 密集检索器 | 将查询和文档映射到共享的向量空间,通过向量相似度进行检索。 | DPR [99], Contriever [100], BGE [101] | 能捕捉语义和上下文关系,泛化能力强。 | 计算密集,需要大量标注数据进行训练,可解释性较弱。 |
| 混合检索器 | 结合稀疏和密集检索器的分数或表示。 | ColBERT [103], ColBERTv2 [104], Blended RAG [61] | 兼具词汇精确性和语义鲁棒性,性能通常最优。 | 系统复杂性增加,需要平衡不同组件的权重。 |
- 检索粒度 (Retrieval granularity):
- 指知识库被切分的最小内容单元,包括文档、区块(chunk)、段落、句子、词元和实体等。
- 粗粒度(如文档级)检索速度快,但可能引入噪声;细粒度(如句子级)精度高,但计算成本高且可能丢失上下文。
- 区块(chunk) 是最常用的粒度,在语义完整性和检索效率间取得了平衡。
- 多粒度检索 成为新趋势,允许模型根据任务动态选择最合适的粒度,如 KET-RAG [108] 结合了图谱与多粒度文本,以捕捉精细的实体级关系。
- 重排 (Reranking):
- 重排技术旨在从初步检索到的文档中,筛选出信息量最大、最相关的子集,并优化其在上下文窗口中的位置(例如,置于开头或结尾),以克服 LLM 的“中间忽略”问题。
- 传统方法包括基于启发式(如 BM25)、学习排序(LTR)和基于预训练语言模型的方法。
- 新兴方法利用 LLM(如 LLM4Ranking [115])或强化学习(如 Rank-R1 [117])赋能重排器,使其具备更强的上下文理解和推理能力,能根据复杂查询动态调整排序策略。
- 文档预处理 (Document Preprocessing):
- 在将文档送入生成模型之前,对其进行修改或压缩,以去除无关信息,保留核心内容。
- 例如,TrustRAG [119] 等方法通过压缩不相关信息,减少由无关内容引起的上下文污染,从而降低幻觉风险。