Mixtral of Experts
-
ArXiv URL: http://arxiv.org/abs/2401.04088v1
-
作者: Alexandre Sablayrolles; Lucile Saulnier; Timothée Lacroix; Devendra Singh Chaplot; Blanche Savary; L’elio Renard Lavaud; Guillaume Lample; A. Mensch; Guillaume Bour; Chris Bamford; 等16人
TL;DR
本文提出了一种名为 Mixtral 8x7B 的稀疏专家混合 (Sparse Mixture of Experts, SMoE) 模型,该模型在推理时仅激活一小部分参数(13B),却在性能上超越了参数量大得多的密集模型(如 Llama 2 70B),显著提升了模型的计算效率和性能。
关键定义
- 稀疏专家混合 (Sparse Mixture of Experts, SMoE): 一种神经网络架构。在传统的 Transformer 模型中,每个 token 都会经过同一个前馈网络 (FFN);而在 SMoE 架构中,存在多个并行的 FFN(称为“专家”),一个“路由器”网络会为每个 token 动态选择一小部分(例如2个)专家进行计算。这使得模型总参数量可以很大,但单次推理的计算量(即“激活参数量”)却很小。
- 专家 (Expert): 在 Mixtral 的架构中,每个专家就是一个标准的前馈网络 (Feed-Forward Network, FFN),具体采用了 SwiGLU 架构。模型在每一层都设置了8个这样的专家。
- 路由器网络 (Router Network): 一个小型的前馈网络,其任务是根据输入 token 的表征,决定将该 token 发送给哪些专家进行处理。它会输出一个权重向量,选择得分最高的K个专家。
- 激活参数量 (Active Parameter Count): 在 SMoE 模型中,处理单个 token 时实际参与计算的参数数量。对于 Mixtral,尽管其总参数量为 47B,但每个 token 只由2个专家处理,因此其激活参数量仅为 13B。这与模型的推理成本和速度直接相关。
相关工作
当前的大语言模型领域,SOTA(State-of-the-Art)模型如 Llama 2 70B 和 GPT-3.5,通过不断增大模型参数量来提升性能。然而,这导致了巨大的计算成本和高昂的推理延迟,限制了它们在实际应用中的部署和可及性。
本文旨在解决这一核心问题:如何在不显著增加推理计算成本的前提下,继续扩大模型的参数规模以提升其性能。具体来说,本文试图通过稀疏激活的方式,构建一个既拥有大模型知识容量、又具备小模型推理效率的语言模型。
本文方法
Mixtral 8x7B 是一个基于 Transformer 架构的仅解码器 (decoder-only) 模型。其核心创新在于将 Transformer 层中的标准前馈网络 (FFN) 替换为了稀疏专家混合 (SMoE) 层。
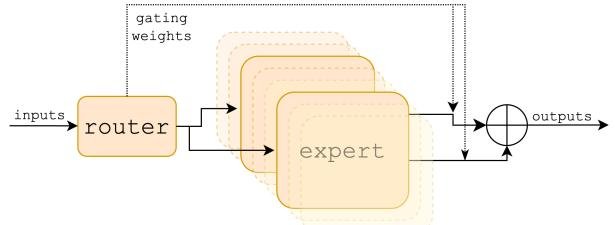
架构细节
Mixtral 的整体架构与 Mistral 7B 相似,但关键区别在于 FFN 层的替换。其主要参数如下表所示。模型支持 32k tokens 的上下文长度。
| 参数 | 值 |
|---|---|
| 维度 (dim) | 4096 |
| 层数 (n_layers) | 32 |
| 头数 (n_heads) | 32 |
| FFN 隐藏层大小 (hidden_dim) | 14336 |
| kv 头数 (n_kv_heads) | 8 |
| 窗口大小 (window_size) | 32768 |
| 词表大小 (vocab_size) | 32000 |
| 专家数量 (n_experts) | 8 |
| 每 token 激活专家数 (num_experts_per_tok) | 2 |
创新点:稀疏专家混合层
该方法的核心是 SMoE 层的设计。对于每一层的每一个输入 token \(x\),其输出 \(y\) 的计算过程如下:
-
路由选择 (Routing):一个路由器网络(可学习的线性层 \(W_g\))计算每个 token 与8个专家的相关性分数。然后,通过 \(TopK\) 函数选择分数最高的 K=2 个专家。
\[G(x) := \text{Softmax}(\text{TopK}(x \cdot W_g))\]其中 \(TopK\) 函数会将未被选中的专家的 logits 设为 \(−∞\)。
-
专家计算 (Expert Computation):被选中的两个专家(每个都是一个 SwiGLU 网络)分别对输入 token \(x\) 进行计算,得到各自的输出 \(E_i(x)\)。
-
加权组合 (Weighted Combination):最终的层输出是这两个专家输出的加权和,权重由路由器的 Softmax 输出决定。
\[y = \sum_{i=0}^{n-1} G(x)_i \cdot E_i(x) = \sum_{i \in \text{Top2}} \text{Softmax}(\text{logits})_i \cdot \text{SwiGLU}_i(x)\]由于路由器是稀疏的(只选择2个),因此在每一层,每个 token 只需调用8个专家中的2个,极大地减少了计算量。
优点
- 高效率: Mixtral 的总参数量达到 47B(每个专家约6B,加上其他参数),但每个 token 推理时仅激活 13B 参数。这使得它在拥有接近 70B 级别模型性能的同时,推理速度和成本与 13B 级别的模型相当。
- 高性能: 通过增加总参数量(更多的专家),模型能够学习和存储更丰富的知识,从而在多个基准测试中,尤其是在数学、代码生成和多语言任务上,展现出超越 Llama 2 70B 的卓越性能。
- 开放性: 模型以 Apache 2.0 许可证发布,促进了社区的研究和商业应用。
实验结论
性能对比
Mixtral 在广泛的基准测试中表现出色,其性能通常优于或持平于 Llama 2 70B 和 GPT-3.5。
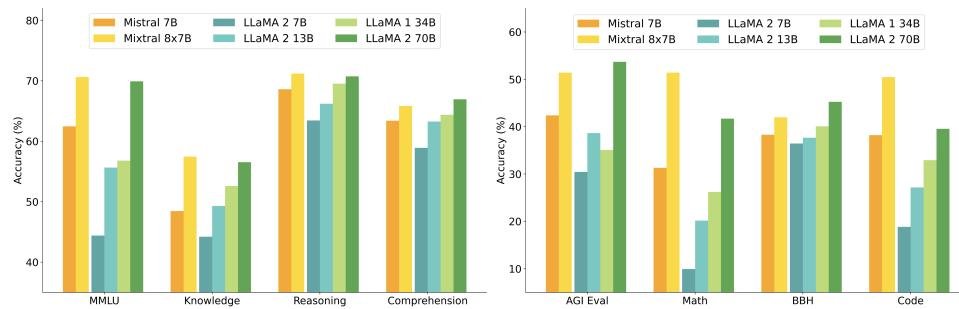
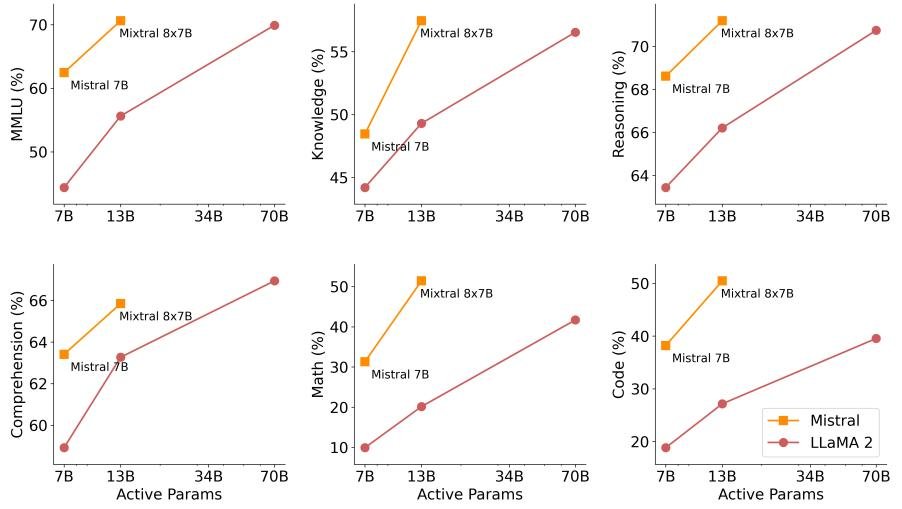
- 综合性能: 如下图和表所示,Mixtral 在 MMLU、常识推理、世界知识等多个基准上全面超越 Llama 2 70B。特别是在数学(GSM8K)和代码生成(HumanEval, MBPP)任务上,优势尤为巨大。
| 模型 | 激活参数 | MMLU | GSM8K | HumanEval | MBPP |
|---|---|---|---|---|---|
| LLaMA 2 70B | 70B | 69.9% | 13.8% | 29.3% | 49.8% |
| GPT-3.5 | - | 70.0% | 57.1% | - | 52.2% |
| Mixtral 8x7B | 13B | 70.6% | 28.4% | 40.2% | 60.7% |
- 尺寸与效率: Mixtral 以仅 Llama 2 70B 约五分之一的激活参数量(13B vs 70B),在大多数基准上实现了更优的性能,展现了 SMoE 架构在成本-性能谱系中的巨大优势。
多语言能力
通过在预训练数据中有意增加多语言数据的比例,Mixtral 在多语言基准测试中显著优于 Llama 2 70B。
| 模型 | Arc-c (French) | HellaS (German) | MMLU (Spanish) |
|---|---|---|---|
| LLaMA 2 70B | 49.9% | 68.7% | 66.0% |
| Mixtral 8x7B | 58.2% | 73.0% | 72.5% |
长上下文能力
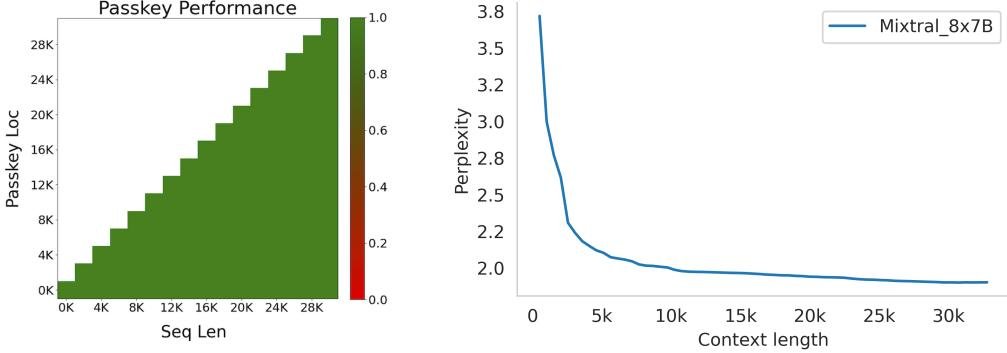
在 Passkey 检索任务中,Mixtral 能够在长达 32k tokens 的上下文中实现 100% 的信息检索准确率,证明了其强大的长程依赖建模能力。
指令微调
经过指令微调和直接偏好优化(DPO)后得到的模型 Mixtral 8x7B – Instruct,在 MT-Bench 上得分 8.30,并在 LMSys 平台上的人类评估中超越了 GPT-3.5 Turbo、Claude-2.1 和 Gemini Pro,成为当时最强的开源指令模型。
| Model | Arena Elo rating | License |
|---|---|---|
| Claude-2.1 | 1117 | Proprietary |
| GPT-3.5-Turbo-0613 | 1117 | Proprietary |
| Gemini Pro | 1111 | Proprietary |
| Llama-2-70b-chat | 1077 | Llama 2 |
| Mixtral-8x7b-Instruct-v0.1 | 1121 | Apache 2.0 |
路由器分析
对路由器行为的分析显示,专家们并没有像预想中那样形成基于主题(如数学、生物学)的明确分工。不同主题的文本在各层的专家分配分布非常相似。然而,模型展现出了一定的句法结构和位置局部性:例如,代码中的缩进、特定关键词(如 \(self\))以及连续的 token 倾向于被分配给相同的专家。这表明专家的特化可能发生在更底层的模式上,而非高级语义概念。

最终结论
本文成功地证明,Mixtral 8x7B 作为首个性能达到 SOTA 水平的开源 SMoE 模型,能够在性能上超越规模远大于自身的密集模型,同时保持了极高的推理效率。这一成果为开发兼具强大能力和高效部署的大语言模型提供了新的范式。