Mixture of Contexts for Long Video Generation
-
ArXiv URL: http://arxiv.org/abs/2508.21058v1
-
作者: Junfei Xiao; Alan Yuille; Maneesh Agrawala; Zhenheng Yang; Yinghao Xu; Lu Jiang; Yuwei Guo; Gordon Wetzstein; Ziyan Yang; Lvmin Zhang; 等3人
-
发布机构: ByteDance; Johns Hopkins University; Stanford University; The Chinese University of Hong Kong
TL;DR
本文提出了一种名为上下文混合(MoC)的可学习稀疏注意力路由模块,将长视频生成问题重构为一个内部信息检索任务,从而在大幅降低计算成本的同时,实现了分钟级视频的长期记忆和一致性。
关键定义
本文提出或沿用了以下对理解论文至关重要的核心概念:
- 上下文混合 (Mixture of Contexts, MoC):本文提出的核心模块。它是一个自适应的稀疏注意力路由机制,取代了传统 Transformer 中的密集自注意力。对于每个查询(query),MoC 动态地从一系列上下文“块”中选择少数最相关的块进行注意力计算,从而将计算量从与序列总长度的二次方关系,转变为与所选块数量的近线性关系。
- 内容对齐分块 (Content-aligned Chunking):一种智能的序列分割策略。不同于将 token 序列切分为固定长度的块,该方法沿着视频内容的自然边界(如帧、镜头、文本片段)进行分割。这使得每个块在语义上更加同质,从而提升了路由选择的准确性和有效性。
- 强制锚点 (Mandatory Anchors):在动态路由之外,强制建立的固定注意力连接,以保证基础的生成质量和稳定性。本文设置了两种锚点:1) 跨模态链接,即所有视觉 token 必须关注所有文本 token,以确保生成内容紧扣文本提示;2) 镜头内链接,即每个 token 必须关注其所属镜头内的所有其他 token,以维持局部的连贯性。
- 因果路由 (Causal Routing):在路由选择阶段施加的一种约束,禁止任何 token 块关注时间序列上位于其后或与自身相同的块。这确保了信息流的单向性(从前到后),将注意力图结构化为有向无环图(DAG),从而从根本上防止了导致生成内容停滞或重复的“反馈循环”问题。
相关工作
目前,基于 Transformer 的扩散模型在视频生成领域取得了显著进展,但将其扩展到分钟甚至小时级别的长视频时,面临两大核心瓶OD颈:
- 计算成本:标准的自注意力机制具有 $O(L^2)$ 的计算复杂度,其中 $L$ 是序列长度。对于长视频(token 数量可达数十万),这种二次方增长的成本在计算和内存上都变得不可行。
- 长期记忆:模型必须在极长的时间跨度上保持内容的一致性(如角色身份、场景布局),避免出现内容漂移、崩溃或信息丢失。
现有方法试图通过两种主要途径解决这些问题:一是将历史信息压缩成紧凑的表示(如关键帧、潜状态),但这会导致细节损失;二是通过固定的稀疏注意力模式来减少计算,但这种静态模式无法自适应地关注真正重要的历史事件。 本文旨在解决的核心问题是:如何在不牺牲生成质量和长期连贯性的前提下,突破自注意力机制的二次方计算瓶颈,实现高效且高质量的长视频生成。
本文方法
本文提出了一种名为上下文混合(Mixture of Contexts, MoC)的自适应稀疏注意力层,用以替代传统扩散 Transformer (DiT) 中的密集自注意力模块,从而将长视频生成任务重构为一个高效的内部信息检索问题。
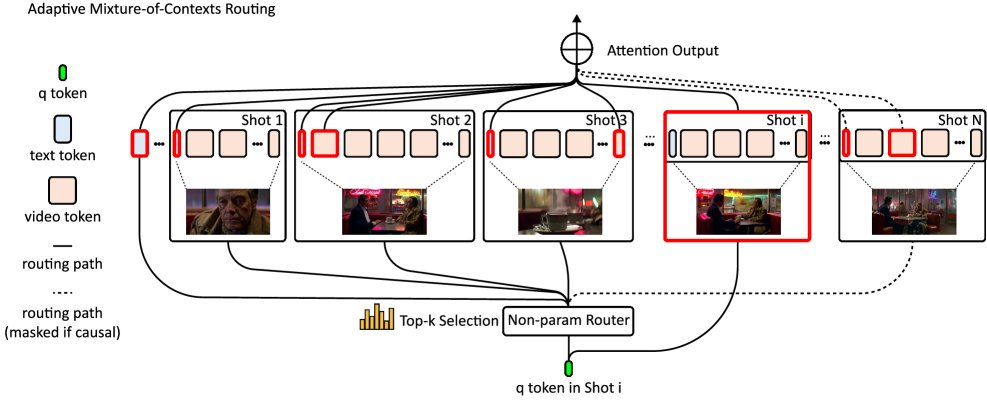 图1:本文提出的自适应上下文混合(MoC)概览。给定一个长的多模态 token 流,首先根据自然边界(帧、镜头、文本段)将其切分为内容对齐的块。然后,对每个块的键(key)进行均值池化,得到一个代表性向量。对于每个查询 token $q$,计算它与每个池化后键的点积,通过 top-k 操作选出最相关的少数块,并加入强制链接(全局文本和镜头内连接)。最终,只有被选中的块会被送入 Flash-Attention 进行计算,而其他所有 token 都被跳过,从而实现了计算和内存在所选块数量上的近线性扩展,而非在总序列长度上的二次方扩展。
图1:本文提出的自适应上下文混合(MoC)概览。给定一个长的多模态 token 流,首先根据自然边界(帧、镜头、文本段)将其切分为内容对齐的块。然后,对每个块的键(key)进行均值池化,得到一个代表性向量。对于每个查询 token $q$,计算它与每个池化后键的点积,通过 top-k 操作选出最相关的少数块,并加入强制链接(全局文本和镜头内连接)。最终,只有被选中的块会被送入 Flash-Attention 进行计算,而其他所有 token 都被跳过,从而实现了计算和内存在所选块数量上的近线性扩展,而非在总序列长度上的二次方扩展。
创新点:动态路由与 Top-k 选择
与以往依赖固定稀疏模式或压缩历史的方法不同,MoC 的核心是一种动态路由机制。其基本思想是,对于序列中的每一个查询 token $q_i$,不再让它与序列中所有的键(key)进行计算,而是只与少数最相关的上下文块进行交互。
标准的注意力计算公式为:
\[\mathrm{Attn}\!\left({\mathbf{Q},\mathbf{K},\mathbf{V}}\right)=\mathrm{Softmax}\!\left(\frac{\mathbf{Q}\mathbf{K}^{\top}}{\sqrt{d}}\right)\cdot{\mathbf{V}},\]而 MoC 将其修改为:
\[\mathrm{Attn}\!\left({\mathbf{q}_{i},\mathbf{K},\mathbf{V}}\right)=\mathrm{Softmax}\!\left(\frac{\mathbf{q}_{i}\mathbf{K}_{\Omega(\mathbf{q}_{i})}^{\top}}{\sqrt{d}}\right)\cdot{\mathbf{V}_{\Omega(\mathbf{q}_{i})}},\]其中,$\Omega(\mathbf{q}_i)$ 是为查询 $q_i$ 动态选择的上下文索引集合。这个集合是通过以下 top-k 选择过程确定的:
- 分块与池化:首先,将整个 token 序列(包括文本和视频 token)按照内容(帧、镜头)切分成多个块。对每个块内的所有键 $\mathbf{K}_\omega$ 进行均值池化,得到一个能代表该块语义的单一描述符向量 $\phi(\mathbf{K}_\omega)$。
- 相似度计算与选择:对于每个查询 $q_i$,计算它与所有块描述符的点积相似度,并选出得分最高的 $k$ 个块。
通过这种方式,注意力计算被限制在一个很小但高度相关的子集上。尽管 top-k 选择本身不可微,但整个框架是端到端可训练的。模型会通过反向传播,调整生成查询和键的投影矩阵,从而学习如何产生更具区分度的表示,以优化路由决策。为增强鲁棒性,训练中还引入了上下文丢弃 (Context Drop-off) 和上下文引入 (Context Drop-in) 两种正则化技巧,模拟不完美的路由决策。
创新点:结构感知的路由策略
MoC 的高效性不仅来自稀疏化,更来自于其结构感知的设计。
-
内容对齐分块:不同于简单的固定长度分块,本文的分块策略遵循视频的自然结构(帧、镜头、模态)。这保证了每个块内部在语义和时空上是连贯的,使得均值池化后的描述符更具代表性,从而路由决策更精准。
- 固定连接(强制锚点):为了保证生成的基本质量,MoC 强制建立了两种连接:
- 跨模态连接:每个视觉 token 都必须关注所有文本 token。这确保了视频内容始终与文本提示保持一致,防止“指令漂移”。
- 镜头内连接:每个 token 都必须关注其所在镜头内的所有其他 token。这保留了局部的时空连贯性,让动态路由可以专注于建立真正的远距离依赖关系。
- 因果路由:为了防止模型陷入“反馈循环”(如镜头A关注镜头B,同时镜头B又关注镜头A),MoC 在路由选择前应用了因果掩码。该掩码禁止任何块关注时间上在其之后或与自身相同的块,确保信息流总是向前传播,形成了有向无环图(DAG),从而提高了长序列生成时的稳定性。
 图2:无因果性约束导致的循环闭合问题。左侧:一个没有因果掩码的消融实验模型生成的连续帧。故事本应从咖啡馆场景(上排)切换到同一位女性在河岸看手机的镜头(下排)。然而,由于镜头9强烈地路由到镜头11,而镜头11又同时路由回镜头9,模型陷入了一个双节点反馈循环,导致镜头9和11与早期镜头的交流受限,如右侧的路由计数图所示。
图2:无因果性约束导致的循环闭合问题。左侧:一个没有因果掩码的消融实验模型生成的连续帧。故事本应从咖啡馆场景(上排)切换到同一位女性在河岸看手机的镜头(下排)。然而,由于镜头9强烈地路由到镜头11,而镜头11又同时路由回镜头9,模型陷入了一个双节点反馈循环,导致镜头9和11与早期镜头的交流受限,如右侧的路由计数图所示。
优点:计算效率高
MoC 通过将二次方复杂度的密集注意力替换为近线性的稀疏注意力,显著降低了计算量。其理论 FLOPs 开销约为:
\[\text{FLOPs}_{\mathrm{MoC}}\;\approx\;Ld+2LCd+4Lk\bar{m}d.\]与密集注意力的 FLOPs ($4L^2d$) 相比,其加速比约为:
\[\frac{\text{FLOPs}_{\text{dense}}}{\text{FLOPs}_{\text{MoC}}}\;\approx\;\frac{2L}{Cd+2k\bar{m}},\]其中 $L$ 是序列长, $C$ 是块数,$k$ 是选择的块数,$\bar{m}$ 是块平均长度,$d$ 是头维度。该比率随序列长度 $L$ 线性增长。例如,对于一个1分钟480p的视频(约18万 token),MoC 能将注意力计算的FLOPs减少超过7倍。同时,该方法通过与 Flash-Attention 内核巧妙结合,实现了对可变长度块的高效处理,将端到端生成速度提升了2.2倍。
实验结论
本文在单镜头和多镜头(场景级)文本到视频生成任务上对 MoC 进行了验证,并与使用密集注意力的基线模型进行了比较。
定量结果
实验评估使用了 VBench 基准,并辅以计算效率指标。
单镜头视频(短序列,约6.3k token): 如下表1所示,尽管 MoC 实现了高达83%的稀疏度,但在所有 VBench 质量指标上,其表现与密集注意力基线相当甚至更好。这证明了将计算资源集中于关键信息是有效的。然而,对于短序列,路由和索引操作的额外开销超过了计算节省,导致端到端速度稍慢。
| 方法 | 主体一致性 $\uparrow$ | 背景一致性 $\uparrow$ | 运动平滑度 $\uparrow$ | 动态程度 $\uparrow$ | 美学质量 $\uparrow$ | 图像质量 $\uparrow$ | 稀疏度 $\uparrow$ | FLOPs $\downarrow$ |
|---|---|---|---|---|---|---|---|---|
| 基线模型 | 0.9380 | 0.9623 | 0.9816 | 0.6875 | 0.5200 | 0.6345 | 0% | $1.9\times 10^{10}$ |
| 本文方法 | 0.9398 | 0.9670 | 0.9851 | 0.7500 | 0.5547 | 0.6396 | 83% | $\mathbf{4.1\times 10^{9}}$ |
表1:单镜头视频生成定量比较。
多镜头视频(长序列,约180k token): 在长序列场景下,MoC 的优势变得极其显著。如表2所示,在85%的稀疏度下,MoC 将FLOPs降低了超过7倍,并带来了2.2倍的实际推理加速。更重要的是,它显著提升了模型的性能,特别是在运动多样性(动态程度从0.46提升至0.56)方面,同时保持了高水平的运动平滑度和一致性。
| 方法 | 主体一致性 $\uparrow$ | 背景一致性 $\uparrow$ | 运动平滑度 $\uparrow$ | 动态程度 $\uparrow$ | 美学质量 $\uparrow$ | 图像质量 $\uparrow$ | 稀疏度 $\uparrow$ | FLOPs $\downarrow$ |
|---|---|---|---|---|---|---|---|---|
| LCT [14] | 0.9378 | 0.9526 | 0.9859 | 0.4583 | 0.5436 | 0.5140 | 0% | $1.7\times 10^{13}$ |
| 本文方法 | 0.9421 | 0.9535 | 0.9920 | 0.5625 | 0.5454 | 0.5003 | $\mathbf{85\%}$ | $\mathbf{2.3\times 10^{12}}$ |
表2:多镜头视频生成定量比较。
定性结果与效率基准
定性结果(如下图)表明,无论是单镜头还是多镜头任务,MoC 生成的视频在视觉质量上与密集注意力模型不相上下,甚至更好,尽管其计算量被削减了超过四分之三。
 图3:单镜头视频生成定性比较。尽管进行了激进的稀疏化,本文方法的结果与基线模型相当,甚至更好。
图3:单镜头视频生成定性比较。尽管进行了激进的稀疏化,本文方法的结果与基线模型相当,甚至更好。
 图4:多镜头视频生成定性比较。尽管剪枝了超过四分之三的注意力计算,本文方法的结果在视觉上与LCT [14]几乎无法区分。
图4:多镜头视频生成定性比较。尽管剪枝了超过四分之三的注意力计算,本文方法的结果在视觉上与LCT [14]几乎无法区分。
效率基准测试(如下图)进一步证实,MoC 的计算延迟随序列长度(即镜头数量)呈近线性增长,而密集注意力则呈二次方增长,展示了其在处理更长视频上的巨大潜力。
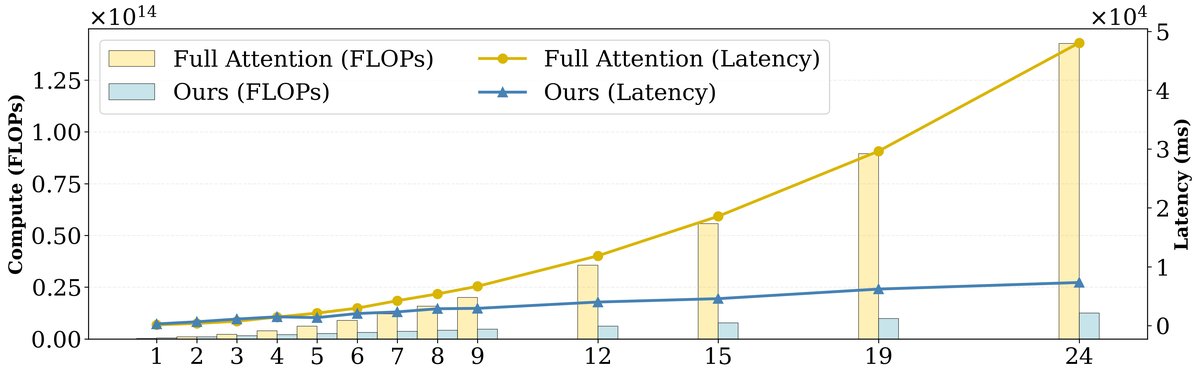 图5:本文内容对齐 MoC 实现与全注意力(使用 Flash Attention 2)的性能基准比较。本文方法的延迟随镜头数(即序列长度L)呈近线性增长。
图5:本文内容对齐 MoC 实现与全注意力(使用 Flash Attention 2)的性能基准比较。本文方法的延迟随镜头数(即序列长度L)呈近线性增长。
总结
本文提出的自适应上下文混合(MoC)方法成功验证了一个核心论点:通过可学习的、结构感知的稀疏注意力,模型能够将计算资源从冗余信息重新分配到关键的视觉事件上。这不仅带来了显著的效率提升(减少超过7倍的FLOPs,实现2.2倍的加速),而且在长视频生成中提升了模型的长期记忆能力和内容多样性,而没有牺牲感知质量。MoC 为构建可扩展、可控的下一代长视频生成模型提供了一个有效蓝图,证明了解决二次方注意力瓶颈是解锁模型涌现长期记忆能力的关键路径。
局限性:当前模型仅在分钟级视频上进行了测试,其在更长序列上的潜力有待探索。此外,目前的实现仍有优化空间,例如通过定制化的CUDA/Triton内核进行软硬件协同设计,可以进一步提升运行速度。