Mixture-of-Minds: Multi-Agent Reinforcement Learning for Table Understanding
-
ArXiv URL: http://arxiv.org/abs/2510.20176v1
-
作者: Jiayi Liu; Lizhu Zhang; Yuhang Zhou; Fei Liu; Ke Li; Mingyi Wang; Abhishek Kumar; Serena Li; Mingrui Zhang; Zhuokai Zhao; 等13人
-
发布机构: Meta AI
TL;DR
本文提出了一种名为 Mixture-of-Minds (MoM) 的多智能体框架,它将表格理解任务分解为规划、编码和回答三个专门的角色,并引入一个基于蒙特卡洛树搜索(MCTS)和强化学习(RL)的自提升训练框架,从而显著提升了模型的表格推理能力。
关键定义
- Mixture-of-Minds (MoM):本文提出的核心多智能体框架。它不依赖单个智能体完成端到端任务,而是将表格理解与推理过程分解为三个专门的角色,分别是规划智能体、编码智能体和回答智能体,三者协同工作。
- 规划智能体 (Planning agent):MoM框架中的第一个角色,负责根据用户问题和表格内容,生成一个结构化的推理步骤计划。这个计划指导后续的编码和回答阶段,防止漫无目的的探索。
- 编码智能体 (Coding agent):MoM框架中的第二个角色,接收规划智能体生成的计划,编写并执行Python代码来操作和转换表格,从而生成结构化的中间证据(例如,过滤后的表格)。
- 回答智能体 (Answering agent):MoM框架中的第三个角色,负责整合原始问题、推理计划以及编码智能体生成的中间证据,最终生成自然语言答案。
- 自提升训练框架 (Self-improvement training framework):为解决多智能体系统中中间步骤缺乏监督数据的问题,本文提出的训练范式。它利用蒙特卡洛树搜索(MCTS)式的数据生成方法,通过大量探索性“推演”(rollouts)来自动收集高质量的中间轨迹(成功的计划和代码),作为“伪黄金”监督信号,再结合强化学习算法(GRPO)对各个智能体进行优化。
相关工作
当前,基于大型语言模型(LLM)的表格理解方法主要分为两大流派:
- 纯模型方法 (Model-only):通过监督微调(SFT)或强化学习(RL)等方式增强LLM自身的内在推理能力。这类方法的优点是语言推理灵活,但缺点是容易出现算术错误、结构混淆和内容幻觉。
- 工具增强方法 (Tool-based):利用Python或SQL等外部工具对表格进行精确操作(如转换、过滤),然后将处理后的信息送回LLM生成答案。这类方法的优点是操作精确可靠,但缺点是依赖僵化的模式(schema),缺乏对语义和意图的深入理解。
本文旨在解决上述两种方法的互补性缺陷,通过一个集成的框架,既利用工具的精确性,又发挥LLM的强大语言推理能力。
本文方法
本文的核心是提出了 Mixture-of-Minds (MoM),一个由智能体工作流和自提升训练框架组成的完整系统。
智能体工作流
MoM 工作流将复杂的表格问答任务分解为三个协调的阶段,每个阶段由一个专门的智能体负责,并利用代码作为外部工具来确保处理的精确性。
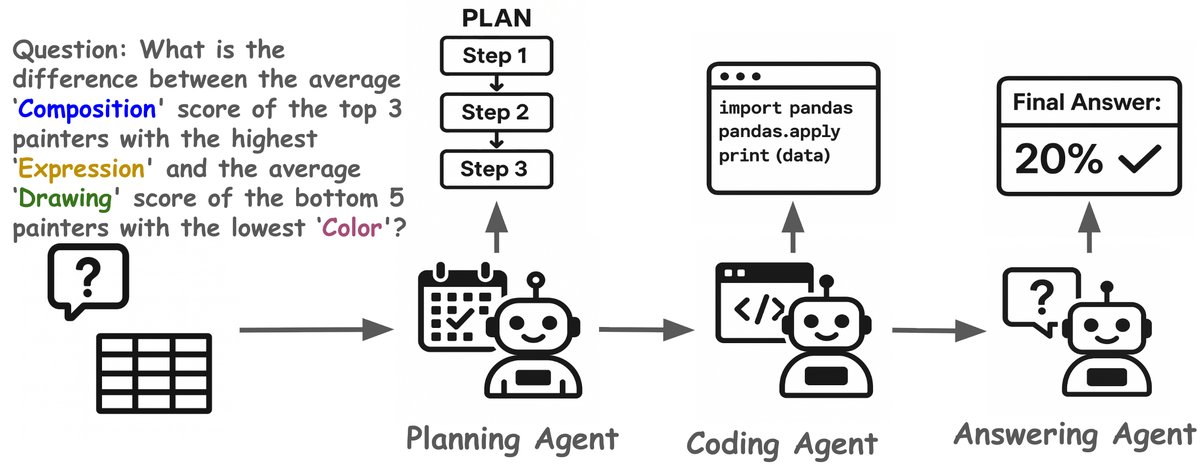
给定一个问题 \(q\) 和一个表格 \(T\),工作流如下:
- 规划智能体 ($\pi^{\text{plan}}_{\theta}$): 生成一个结构化的推理计划 \(p\),它为后续步骤提供了明确的指引。
- 编码智能体 ($\pi^{\text{code}}_{\theta}$): 基于问题 \(q\)、表格 \(T\) 和计划 \(p\),生成可执行的Python代码 \(c\)。执行代码后,会得到一系列中间表格结果 $\textsc{T}^{\prime}$,作为可靠的结构化证据。
- 回答智能体 ($\pi^{\text{ans}}_{\theta}$): 综合问题 \(q\)、计划 \(p\) 和中间证据 $\textsc{T}^{\prime}$,生成最终答案 $\hat{y}$。
创新点
- 任务分解:将端到端推理分解为规划、编码、回答三个更小、更明确的子任务,降低了单一模型的认知负荷,使得每个智能体可以专注于自身擅长的领域。
- 可解释性与可诊断性:该流程的每一步都是透明的。如果出现错误,可以轻松定位到是计划、代码还是最终回答环节出了问题。
- 鲁棒性:通过将推理与代码执行分离,有效减少了纯LLM推理中常见的幻觉和计算错误,提高了结果的可靠性。
- 对测试时扩展的良好支持 (Test-time scaling, TTS):模块化设计允许在测试时对不同阶段采用不同的解码策略(如在规划和编码阶段增加采样多样性,在回答阶段减少采样以求稳定),这在单一模型中难以实现。
智能体训练
为了训练 MoM 工作流中的各个智能体,本文设计了一个自提升训练框架,以解决中间步骤(计划和代码)缺乏标注数据的核心难题。

MCTS 式数据生成
该方法通过 MCTS 风格的推演(rollouts)自动构建高质量的中间数据。
- 计划生成:规划智能体生成 \(α\) 个候选计划。
- 代码生成:对每个计划,编码智能体生成 \(β\) 个候选代码。
- 答案生成:对每个代码,执行后得到的中间结果与计划一起,由回答智能体生成 \(γ\) 个候选答案。
只有当某个轨迹(由计划 \(p_i\) 和代码 \(c_{i,j}\) 组成)最终能导向正确的答案时,该轨迹中的计划和代码才被视为高质量的“伪黄金”监督数据,用于后续的训练。
使用 GRPO 进行智能体训练
本文采用 群体相对策略优化 (Group Relative Policy Optimization, GRPO) 这种强化学习算法来优化各个智能体。GRPO通过比较一组候选输出的相对好坏来更新模型策略。其目标函数为:
\[\mathcal{J}_{\text{GRPO}}(\theta)=\mathbb{E}_{q,\{o_{i}\}}\Biggl[\frac{1}{G}\sum_{i=1}^{G}\min\Biggl(\frac{\pi_{\phi}(y_{i} \mid x)}{\pi_{\phi_{\text{old}}}(y_{i} \mid x)}A_{i},\text{clip}\left(\frac{\pi_{\phi}(y_{i} \mid x)}{\pi_{\phi_{\text{old}}}(y_{i} \mid x)},1-\epsilon,1+\epsilon\right)A_{i}\Biggr)\Biggr]-\beta\,\mathbb{D}_{\text{KL}}[\pi_{\theta}\ \mid \pi_{\text{ref}}]\]训练过程是序贯的,确保每个智能体都能在前一个优化过的智能体的基础上进行训练:
- 训练规划智能体:使用 MCTS 生成的伪黄金计划作为监督信号。奖励函数 \(r^plan\) 结合了格式正确性和与黄金计划的BLEU分数。
- 训练编码智能体:使用优化后的规划智能体生成计划。奖励函数 \(r^code\) 是一个混合奖励,包括格式、执行成功率、代码操作相似度以及代码输出与黄金输出的对齐度。
- 训练回答智能体:使用优化后的规划和编码智能体生成输入。奖励函数 \(r^ans\) 基于格式正确性和与标准答案的精确匹配(Exact Match, EM)度。
这种逐步优化的策略确保了整个工作流的性能得到协同提升。
实验结论
实验结果有力地验证了 MoM 工作流和训练框架的有效性。
- 工作流本身效果显著:仅使用 MoM 的三阶段工作流(不经过专门训练),相较于直接让模型进行端到端推理,性能就有显著提升。例如,在 LLaMA-3.3-70B 上,平均准确率提升了 16.6%。这证明了任务分解的内在优势,尤其是在需要精确计算的数值推理任务上。
| 模型 (Model) | 方法 (Method) | 事实核查 (FC) | 数值推理 (NR) | 数据分析 (DA) | 平均 (Avg.) |
|---|---|---|---|---|---|
| LLaMA-3.1-8B | Direct | 70.8 | 42.6 | 13.5 | 42.3 |
| MoM Workflow | 66.7 | 46.5 | 16.1 | 43.1 | |
| LLaMA-3.3-70B | Direct | 72.9 | 57.4 | 19.3 | 49.9 |
| MoM Workflow | 88.5 | 78.9 | 32.8 | 66.5 | |
| Qwen3-8B | Direct | 71.9 | 49.3 | 19.3 | 46.8 |
| MoM Workflow | 77.1 | 57.4 | 21.2 | 52.2 | |
| Gemma3-27B | Direct | 78.1 | 63.8 | 19.3 | 53.7 |
| MoM Workflow | 82.3 | 69.0 | 25.2 | 58.9 | |
| Nemotron-49B | Direct | 83.3 | 66.7 | 30.0 | 60.0 |
| MoM Workflow | 89.6 | 77.5 | 30.7 | 65.9 |
- 训练框架带来巨大性能飞跃:结合自提升训练框架后,MoM 的性能得到进一步提升,甚至超越了规模大几个数量级的顶尖模型。值得注意的是,经过 MoM 框架训练的 Qwen3-32B 模型,在测试时扩展(TTS)的加持下,在 TableBench 上的准确率达到 62.13%,超过了强大的基线模型 OpenAI o4-mini-high(61.69%)。
| 模型家族 | 模型 | 方法 | 事实核查 (FC) | 数值推理 (NR) | 数据分析 (DA) | 加权平均 |
|---|---|---|---|---|---|---|
| Grok | Grok-4 | Single Pass | 68.8 | 80.3 | 52.3 | 67.1 |
| Claude | Claude-4-Sonnet | Single Pass | 85.4 | 56.0 | 45.8 | 62.4 |
| Gemini | Gemini-2.5-Pro | Single Pass | 78.1 | 69.0 | 38.3 | 61.8 |
| OpenAI | GPT-5 | Single Pass | 92.7 | 81.7 | 49.8 | 74.7 |
| o4-mini-high | Single Pass | 87.5 | 69.0 | 28.4 | 61.7 | |
| o4-mini | Single Pass | 83.3 | 66.7 | 25.2 | 58.4 | |
| o3-mini | Single Pass | 85.4 | 69.0 | 25.2 | 60.0 | |
| DeepSeek | DeepSeek-R1 | Single Pass | 68.8 | 77.5 | 53.8 | 66.7 |
| LLaMA | LLaMA-3.1-8B | MoM (本文) | 70.8 | 59.7 | 24.5 | 46.7 |
| MoM + TTS | 71.9 | 58.3 | 26.0 | 47.1 | ||
| Qwen | Qwen3-8B | MoM (本文) | 84.4 | 64.8 | 38.3 | 57.4 |
| MoM + TTS | 86.5 | 66.2 | 42.1 | 59.6 | ||
| Qwen3-32B | MoM (本文) | 87.5 | 73.2 | 42.1 | 59.9 | |
| MoM + TTS | 92.7 | 77.5 | 42.9 | 62.1 |
-
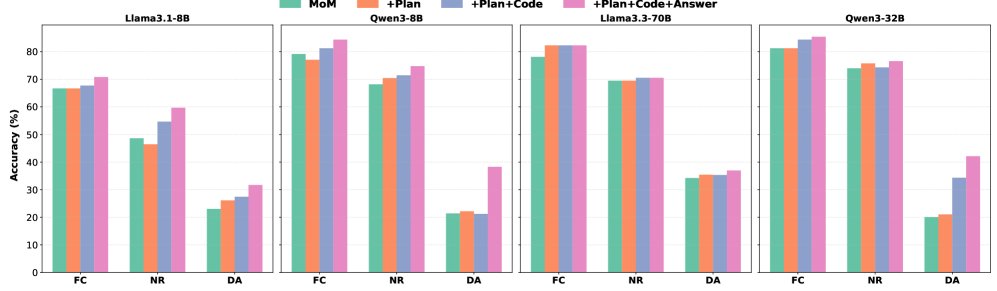
序贯训练的贡献:消融实验表明,序贯地训练规划、编码和回答智能体,每一步都能带来性能的单调提升。其中,训练回答智能体带来的增益最为明显,因为它直接对齐最终输出。
-
对测试时扩展的有效性:MoM 的结构天然支持测试时扩展(TTS)策略。实验证明,无论是并行多次采样取多数票,还是序贯地扩展推理路径,都能进一步提升模型表现。
总结
本文所提出的 Mixture-of-Minds (MoM) 框架,通过将表格理解任务分解为规划、编码和回答三个阶段,并结合基于 MCTS 和 RL 的自提升训练方法,成功地融合了 LLM 的灵活推理能力和代码执行的精确性。实验结果证明,该方法不仅在各类表格理解任务上取得了显著优于基线的性能,还能让中等规模的开源模型达到甚至超越顶尖闭源模型的水平,展示了结构化多智能体工作流结合强化学习在复杂推理任务上的巨大潜力。