MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
-
ArXiv URL: http://arxiv.org/abs/2308.02490v4
-
作者: Zicheng Liu; Weihao Yu; Kevin Lin; Jianfeng Wang; Linjie Li; Zhengyuan Yang; Lijuan Wang; Xinchao Wang
-
发布机构: Microsoft Azure AI; National University of Singapore
TL;DR
本文提出了一个名为 MM-Vet 的新基准,旨在通过评估大型多模态模型(LMMs)在整合多种核心视觉语言(VL)能力以解决复杂任务时的表现,来系统性地衡量其综合智能水平,并为此设计了一个基于大型语言模型(LLM)的自动化评估器。
关键定义
- MM-Vet (Multimodal Veterinarian):一个新提出的评估基准,专门用于衡量大型多模态模型(LMMs)的综合能力。其核心思想是,真正强大的LMMs能够整合多种基础能力来解决复杂的现实世界问题。
- 核心视觉语言能力 (Core Vision-Language Capabilities):本文定义了LMMs应具备的六种基础能力,作为评估的基石。它们分别是:
- 识别 (Recognition, Rec):识别场景、物体、属性、数量等视觉元素。
- 光学字符识别 (OCR):理解和推理图像中的场景文本。
- 知识 (Knowledge, Know):运用常识、百科知识、时事新闻等解决问题。
- 语言生成 (Language Generation, Gen):以清晰、丰富、有信息量的方式生成文本回复。
- 空间意识 (Spatial Awareness, Spat):理解物体或文本区域之间的空间关系。
- 数学 (Math):解决图像中出现的数学问题或算式。
- 能力整合 (Integrated Capabilities):指将上述六种核心能力中的两种或多种组合起来,以完成更复杂的任务。MM-Vet基准测试的核心就是评估模型在16种不同的能力整合场景下的表现。
- 基于LLM的评估器 (LLM-based Evaluator):一种新颖的评估方法,它使用 GPT-4 模型,通过精心设计的少样本提示(few-shot prompt),对LMMs生成的开放式回答进行打分(0到1分)。该方法能够统一评估不同问题类型和答案风格的输出,解决了传统评估指标的局限性。
相关工作
当前,大型多模态模型(LMMs)如 GPT-4V 展现出解决复杂问题的惊人能力。然而,现有的视觉语言(VL)基准,如 VQA、COCO 等,通常只关注单一或两种特定能力(如识别、描述),无法系统性地评估模型在处理需要多种能力协同的复杂任务时的表现。这构成了一个关键瓶颈:我们缺乏一个能够衡量LMMs“综合智能”的有效工具。
此外,由于LMMs的输出通常是开放式的自由文本,长度和风格各异,如何设计一个统一、公平且可扩展的评估指标也是一大挑战。
本文旨在解决上述两个问题:
- 如何系统地构建和评估需要多种核心能力整合的复杂多模态任务?
- 如何为格式多样的开放式回答设计一个统一且有效的评估指标?
本文方法
本文的核心贡献是提出了一个全新的评估框架,包括 MM-Vet 基准的设计和一个创新的评估器。
MM-Vet 基准设计
MM-Vet 的设计理念源于一个核心洞察:LMMs 解决复杂多模态任务的“涌现”能力,本质上来源于其对多种核心视觉语言能力的掌握和无缝整合。
基于此,MM-Vet 的构建分为两步:
- 定义核心能力:首先,通过分析现实世界中的复杂场景,提炼出六种最核心的VL能力:识别(Rec)、OCR、知识(Know)、语言生成(Gen)、空间意识(Spat)和数学(Math)。
- 构建综合任务:其次,围绕这六种能力的16种不同组合(例如“识别+知识+生成”用于解释视觉笑话,“OCR+空间意识+数学”用于计算购物清单总价),构建了包含200张图片和218个问题的测试集。这些问题均为开放式问答,覆盖了广泛的真实世界场景。
下图展示了MM-Vet数据集中各核心能力及其组合的分布情况。
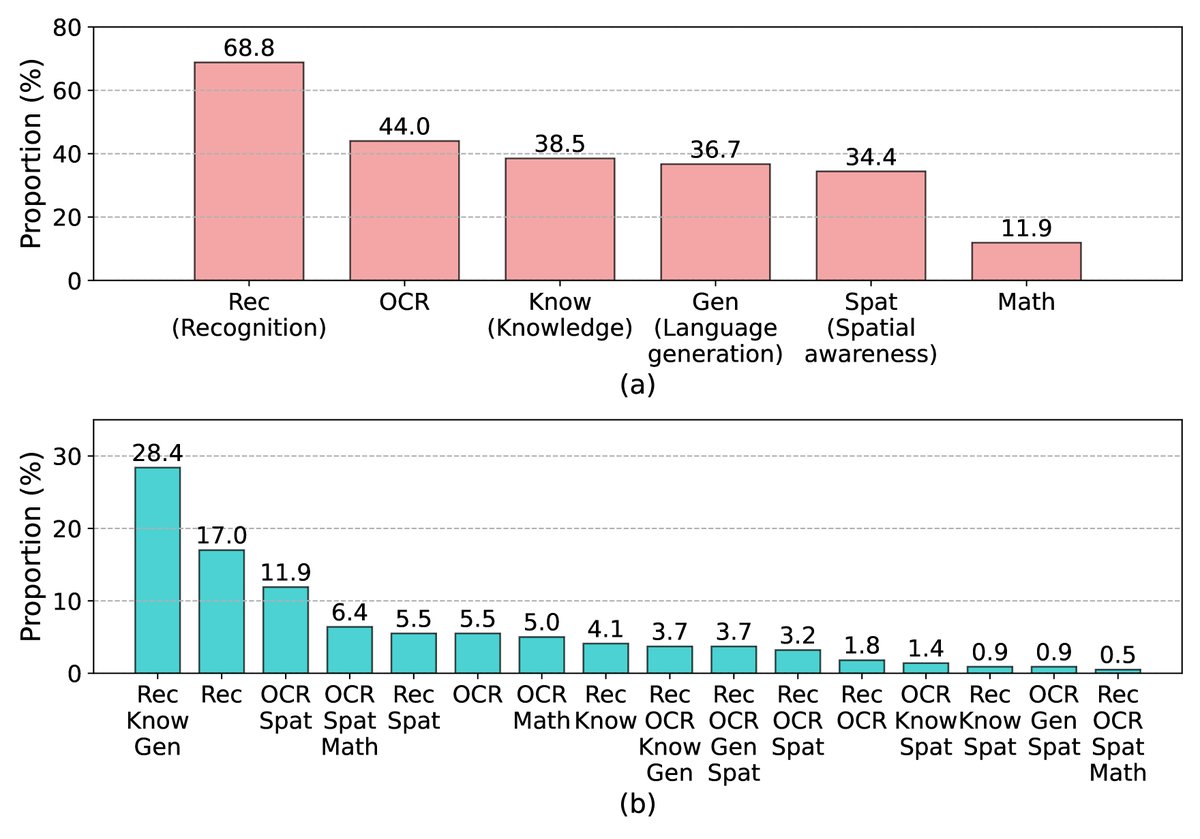 图注:(a) 数据集中每个单一能力的覆盖比例(因样本常涉及多能力,总和大于100%)。(b) 数据集中不同能力组合的分布比例(总和为100%)。
图注:(a) 数据集中每个单一能力的覆盖比例(因样本常涉及多能力,总和大于100%)。(b) 数据集中不同能力组合的分布比例(总和为100%)。
基于LLM的开放式评估器
为了解决开放式回答的评估难题,本文没有采用传统的关键词匹配或多项选择题模式,而是创新地提出了一个基于LLM的自动化评估器。
- 工作原理:该评估器利用 GPT-4 的强大语言理解和推理能力。对于每个测试样本,它会接收一个包含“问题(Question)”、“标准答案(Ground Truth)”和“模型预测(Prediction)”的提示(Prompt)。
- 少样本提示设计:提示是精心设计的少样本(few-shot)格式,如 Table 1 所示。它包含了多个评分范例,覆盖了从完全错误(0.0分)、部分正确(如0.4、0.5分)到完全正确(1.0分)的各种情况,并且同时包含了简短答案(如数学计算)和长文本答案(如解释meme)的例子。通过这些上下文中的示例,GPT-4 能够“学习”并推断出统一的评分标准。
Table 1: 用于GPT-4评估模型输出的少样本提示 下表中,$\mathcal{Q}$ 是样本问题,$\mathcal{G}$ 是标准答案,$\mathcal{P}$ 是模型输出。该提示包含了不同长度和类型的答案示例,使评估器能够处理多样化的输出。
| Compare the ground truth and prediction from AI models, to give a correctness score for the prediction. | |||
| Question | Ground truth | Prediction | Correctness |
| — | — | — | — |
| What is x in the equation? | -1 | x = 3 | 0.0 |
| What is x in the equation? | -1 | x = -1 | 0.5 |
| What is x in the equation? | -1 | x = -5 | 0.5 |
| What is x in the equation? | -1 | x = -5 or 5 | 0.5 |
| What is x in the equation? | -1 | x = -1 or x = -5 | 1.0 |
| Can you explain this meme? | This meme is poking fun at the fact that the names of the countries Iceland and Greenland are misleading. Despite its name, Iceland is known for its beautiful green landscapes, while Greenland is mostly covered in ice and snow. The meme is saying that the person has trust issues because the names of these countries do not accurately represent their landscapes. | The meme talks about Iceland and Greenland. It’s pointing out that despite their names, Iceland is not very icy and Greenland isn’t very green. | 0.4 |
| Can you explain this meme? | This meme is poking fun at the fact that the names of the countries Iceland and Greenland are misleading. Despite its name, Iceland is known for its beautiful green landscapes, while Greenland is mostly covered in ice and snow. The meme is saying that the person has trust issues because the names of these countries do not accurately represent their landscapes. | The meme is using humor to point out the misleading nature of Iceland’s and Greenland’s names. Iceland, despite its name, has lush green landscapes while Greenland is mostly covered in ice and snow. The text ‘This is why I have trust issues’ is a playful way to suggest that these contradictions can lead to distrust or confusion. The humor in this meme is derived from the unexpected contrast between the names of the countries and their actual physical characteristics. | 1.0 |
| $\mathcal{Q}$ | $\mathcal{G}$ | $\mathcal{P}$ |
-
计分方式:评估器为每个样本输出一个0到1之间的分数 $s_i$。总分 $S$ 和特定能力(或能力组合)得分 $S_c$ 的计算方式如下:
\[S=\frac{\sum\_{i=1}^{N}s\_{i}}{N}\times 100\\] \[S\_{c}=\frac{\sum s\_{i}}{N\_{c}}\times 100\,\quad i\in C\]其中,$N$ 是总样本数,$C$ 是需要特定能力的样本集合,$N_c$ 是该集合中的样本数。
实验结论
本文对两种主流LMM范式进行了评估:1) 端到端微调的LMMs(如LLaVA、InstructBLIP等);2) 基于LLM并使用外部工具的智能体系统(如MM-ReAct)。同时,也测试了闭源的GPT-4V模型。
核心能力评估摘要
Table 2: 各LMM在MM-Vet六大核心能力上的表现 (%) 绿色、橙色、蓝色分别表示各项得分的第一、二、三名。
| Model | Rec | OCR | Know | Gen | Spat | Math | Total |
|---|---|---|---|---|---|---|---|
| Transformers Agent (GPT-4) | 18.2 | 3.9 | 2.2 | 3.2 | 12.4 | 4.0 | 13.4$\pm$0.5 |
| MiniGPT-4-8B | 27.4 | 15.0 | 12.8 | 13.9 | 20.3 | 7.7 | 22.1$\pm$0.1 |
| BLIP-2-12B | 27.5 | 11.1 | 11.8 | 7.0 | 16.2 | 5.8 | 22.4$\pm$0.2 |
| LLaVA-7B | 28.0 | 17.1 | 16.3 | 18.9 | 21.2 | 11.5 | 23.8$\pm$0.6 |
| MiniGPT-4-14B | 29.9 | 16.1 | 20.4 | 22.1 | 22.2 | 3.8 | 24.4$\pm$0.4 |
| Otter-9B | 27.3 | 17.8 | 14.2 | 13.8 | 24.4 | 3.8 | 24.7$\pm$0.3 |
| OpenFlamingo-9B | 28.7 | 16.7 | 16.4 | 13.1 | 21.0 | 7.7 | 24.8$\pm$0.2 |
| InstructBLIP-14B | 30.8 | 16.0 | 9.8 | 9.0 | 21.1 | 10.5 | 25.6$\pm$0.3 |
| InstructBLIP-8B | 32.4 | 14.6 | 16.5 | 18.2 | 18.6 | 7.7 | 26.2$\pm$0.2 |
| LLaVA-13B | 30.9 | 20.1 | 23.5 | 26.4 | 24.3 | 7.7 | 26.4$\pm$0.1 |
| MM-ReAct-GPT-3.5 | 24.2 | 31.5 | 21.5 | 20.7 | 32.3 | 26.2 | 27.9$\pm$0.1 |
| LLaVA-7B (LLaMA-2) | 32.9 | 20.1 | 19.0 | 20.1 | 25.7 | 5.2 | 28.1$\pm$0.4 |
| LLaMA-Adapter v2-7B | 38.5 | 20.3 | 31.4 | 33.4 | 22.9 | 3.8 | 31.4$\pm$0.1 |
| LLaVA-13B (V1.3, 336px) | 38.1 | 22.3 | 25.2 | 25.8 | 31.3 | 11.2 | 32.5$\pm$0.1 |
| LLaVA-13B (LLaMA-2) | 39.2 | 22.7 | 26.5 | 29.3 | 29.6 | 7.7 | 32.9$\pm$0.1 |
| MM-ReAct-GPT-4 | 33.1 | 65.7 | 29.0 | 35.0 | 56.8 | 69.2 | 44.6$\pm$0.2 |
- 端到端模型 vs. 工具使用模型:
- MM-ReAct (基于GPT-4) 在 OCR、空间感知和数学 这三项能力上遥遥领先,因为它能够调用专门的外部API(如OCR工具、数学计算器),展现了工具使用的巨大优势。
- 端到端模型 中,LLaVA-13B (LLaMA-2) 和 LLaMA-Adapter v2-7B 在 识别、知识和语言生成 等需要更强模型内在融合能力的方面表现突出。这得益于其强大的视觉编码器、语言模型基座和大规模、多样化的微调数据。
能力整合评估摘要
Table 3: 各LMM在MM-Vet能力整合任务上的表现 (%) (部分列展示)
| Model | Rec+Know+Gen | Rec | OCR+Spat | OCR+Spat+Math | OCR+Math | … | Total |
|---|---|---|---|---|---|---|---|
| LLaVA-13B (LLaMA-2) | 29.8 | 59.5 | 21.2 | 14.3 | 36.2 | … | 32.9$\pm$0.1 |
| LLaMA-Adapter v2-7B | 35.3 | 54.1 | 13.5 | 7.1 | 38.5 | … | 31.4$\pm$0.1 |
| MM-ReAct-GPT-4 | 22.5 | 33.0 | 69.2 | 78.6 | 83.0 | … | 44.6$\pm$0.2 |
- 实验结果验证了MM-Vet的有效性,它能清晰区分不同模型架构的优劣势。例如,对于需要明确工具(如计算器)的任务(如 OCR+Spat+Math),MM-ReAct-GPT-4 得分高达78.6%,而端到端模型普遍表现不佳。相反,在需要“软”能力整合的任务(如 Rec+Know+Gen 的笑话解释)中,LLaMA-Adapter v2-7B (35.3%) 和 LLaVA (29.8%) 等模型则表现更优。
与 GPT-4V 的对比
Table 5: GPT-4V 在MM-Vet六大核心能力上的表现 (%)
| Model | Rec | OCR | Know | Gen | Spat | Math | Total |
|---|---|---|---|---|---|---|---|
| LLaVA-13B (LLaMA-2) | 39.2 | 22.7 | 26.5 | 29.3 | 29.6 | 7.7 | 32.9$\pm$0.1 |
| MM-ReAct-GPT-4 | 33.1 | 65.7 | 29.0 | 35.0 | 56.8 | 69.2 | 44.6$\pm$0.2 |
| GPT-4V | 67.5 | 68.3 | 56.2 | 60.7 | 69.4 | 58.6 | 67.7$\pm$0.3 |
| GPT-4V-Turbo-detail:high | 62.9 | 75.9 | 53.7 | 57.3 | 76.8 | 69.5 | 67.6$\pm$0.1 |
- 结论:GPT-4V 在MM-Vet上的表现全面领先于所有其他已测试的开源模型和工具系统,总分达到 67.7%,展现了其作为当前最先进LMM的强大综合能力。它在几乎所有核心能力和能力整合任务上都设立了新的技术标杆。
-
有趣的是,虽然GPT-4V整体强大,但在某些极其依赖特定工具的任务上(如 OCR+Spat+Math),配备了专业工具的 MM-ReAct-GPT-4 仍能与之媲美甚至略微超越,这揭示了未来LMM发展的两条可能路径:一是打造能力更全面的内生模型,二是构建更高效的工具调用与整合框架。
- 最终结论:MM-Vet被证明是一个有效的基准,它不仅能对LMMs进行排名,更重要的是,它能揭示不同模型在各项综合能力上的优势与短板,为未来LMM的研发提供了清晰的指导方向。实验表明,当前最强的LMM(GPT-4V)在综合能力上已远超其他模型,而工具增强型LMM在特定可分解任务上表现优异,端到端模型则在微调数据和模型规模的驱动下不断进步。