MoM: Mixtures of Scenario-Aware Document Memories for Retrieval-Augmented Generation Systems
-
ArXiv URL: http://arxiv.org/abs/2510.14252v1
-
作者: Simin Niu; Zhiyu Li; Hanyu Wang; Feiyu Xiong; Zhiyuan Ji; Jihao Zhao
-
发布机构: Institute for Advanced Algorithms Research; MemTensor (Shanghai) Technology Co., Ltd.; Renmin University of China
TL;DR
本文提出一个名为MoM(Mixtures of Scenario-aware Document Memories)的框架,通过模拟专家阅读过程,将传统检索增强生成(RAG, Retrieval-Augmented Generation)中的被动文本分块,转变为主动提取结构化的“文档记忆”(包含大纲、核心内容和原子分块),并训练小语言模型(SLM, small language models)掌握此能力,最终通过一个理论支持的三层检索机制提升了知识检索的精度和深度。
关键定义
- 文档记忆 (Document Memory):本文提出的核心概念,指对非结构化文本进行深度理解和重构后得到的结构化知识体系。它被定义为一个三元组 \(M_doc = {O, C, A}\),其中:
- \(O\) (Outline):文档的宏观逻辑结构,由核心主题构成的大纲。
- \(C\) (Core Content):从每个大纲节点对应内容中提炼出的高度浓缩的知识点集合。
- \(A\) (Atomic Chunks):在大纲指导下对原文进行的、具有强语义内聚性的细粒度内容分块。
- 链式记忆提取推理 (Chain of Memory extraction, CoM):一种为训练小模型而设计的“思维链”。通过逆向工程,让大语言模型(LLM)生成从原始文档到最优文档记忆的详细推理路径,作为高质量的训练数据。
- MemReader: 指通过MoM框架训练后、能够像人类专家一样主动阅读原始文档并自主生成结构化文档记忆的小语言模型(SLM)。
- 分块清晰度 (Chunk Clarity):本文设计的一个评估指标,用于衡量原子分块之间语义边界的清晰程度。清晰度越高,代表分块的逻辑性和独立性越好。
- 核心内容完备性 (Core Content Completeness):本文设计的另一个评估指标,用于衡量核心内容 \(C\) 对原始分块 \(A\) 信息覆盖的有效性和简洁性。
相关工作
当前主流的RAG系统在文本预处理阶段严重依赖于被动的、与上下文无关的分块策略,如固定大小或递归分块。这些方法忽略了文档深层的语义和逻辑结构。虽然有部分研究开始探索语义分块,但它们多采用“自下而上”的构建逻辑,缺乏对文档整体架构的宏观把握,导致知识块在组合后可能偏离主题。此外,现有的RAG记忆系统研究严重偏向于对话场景中的短期和长期记忆管理,而对文档本身进行结构化、整体性记忆构建的机制尚处于初级阶段。
本文旨在解决传统RAG范式中的两个核心问题:
- 如何让模型能像领域专家一样,主动将非结构化文本转化为语义完整、逻辑连贯的结构化知识(即文档记忆)?
- 如何高效地将这种深度理解能力赋予小语言模型(SLM)?
本文方法
MoM框架的核心目标是学习一个映射函数 $f_{\text{MoM}}: \mathcal{D} \to \text{M}_{\text{doc}}$,将原始文档 $\mathcal{D}$ 转化为结构化的文档记忆 $\text{M}_{\text{doc}}$。该过程主要包括记忆提取、CoM构建和模型训练。
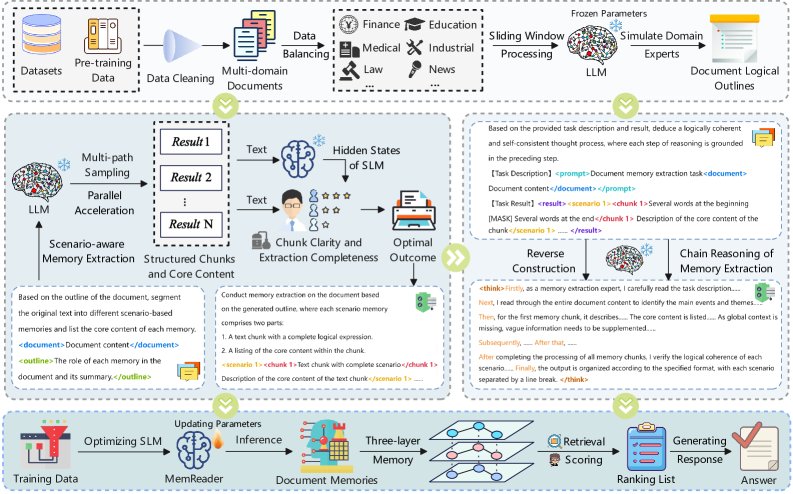
文档记忆提取与评估
该过程模拟专家认知,分步构建并筛选高质量的文档记忆。
- 专家模拟与生成:首先,利用一个强大的引导模型 $\mathcal{M}_{G}$(如DeepSeek-R1)扮演领域专家,对输入文档 $\mathcal{D}$ 进行宏观分析,生成逻辑大纲 $O$。
- 分层内容提取:以大纲 $O$ 为框架,引导模型 $\mathcal{M}_{G}$ 进一步为每个大纲节点提炼核心内容 $C$ 和对应的原子分块 $A$。
- 多路径采样与评估:为避免单次生成的局限性,通过调整解码参数生成 $N$ 个候选文档记忆。为了从中选出最优解,本文设计了两个量化评估指标:
- 分块清晰度 ($\mathcal{S}_{\text{clarity}}$):评估原子分块之间的语义边界是否清晰。分数越高,分块结构越合理。
- 核心内容完备性 ($\mathcal{S}_{\text{comp}}$):评估核心内容对原文信息的覆盖效率。分数越高,代表核心内容越简洁且信息量大。
-
最优记忆选择:使用倒数排序融合(Reciprocal Rank Fusion)算法结合上述两个指标的排名,计算每个候选记忆的综合得分 $\mathcal{S}_{\text{RRF}}$,并选择得分最高的作为最终的文档记忆。
\[\mathcal{S}_{\text{RRF}}(\text{M}_{\text{doc}}^{(i)})=\frac{1}{k+\text{rank}_{\text{clarity}}^{(i)}}+\frac{1}{k+\text{rank}_{\text{comp}}^{(i)}}\]
CoM的逆向构建与MemReader训练
为了将这种复杂的知识构建能力迁移到SLM上,本文采用了一种创新的训练策略。
- 逆向构建CoM:不仅仅提供输入-输出对,而是再次利用引导模型 $\mathcal{M}_{G}$,为其提供原始文档 $\mathcal{D}$ 和已选出的最优文档记忆 $\text{M}_{\text{doc}}$,让其逆向生成达到该最优结果的详细推理路径 $\mathcal{P}$。这个路径 $\mathcal{P}$ 就是高质量的CoM数据。
-
训练MemReader:基于构建的约40K个训练样本(每个样本为三元组 $(\mathcal{D}, \mathcal{P}, \text{M}_{\text{doc}})$),通过标准的自回归损失函数对SLM进行微调,使其成为能够直接从原始文档生成推理路径和文档记忆的MemReader。
\[\mathcal{L}_{\text{F}}(\theta)=-\frac{1}{\tau}\sum_{t=1}^{\tau}\log P(o_{t} \mid o_{<t},s;\theta)\]
三层文档记忆检索
基于生成的文档记忆 $\text{M}_{\text{doc}}={O,C,A}$,本文构建了一个三层检索机制,并从概率模型角度证明了其优越性。
理论基础: 本文提出语义分歧假设 (Semantic Divergence Hypothesis),即用户的查询意图在向量空间中天然分为两类:寻求宏观理解的全局查询(global queries, $q_{\text{abs}}$)和探索细节的局部查询(local queries, $q_{\text{query}}$)。这两种查询向量的分布中心是不同的($\ \mid \mu_{\text{abs}}-\mu_{\text{query}}\ \mid _{2}>0$)。
方法对比:
- 分层多向量检索 (Hierarchical Multi-Vector, HMV),即本文方法:独立计算大纲和核心内容的向量,分别应对全局和局部查询。这种方法能够无偏地估计两种语义中心。
- 单向量融合检索 (Single-Vector Fusion, SVF),即传统方法:在检索前将所有信息融合成一个单一向量。这种方法产生的是一个有偏的、折衷的估计,稀释了两种语义的表达纯度。
理论证明: 本文证明了,在预期相似度上,HMV方法优于SVF方法。对于全局查询,HMV的预期相似度为1,而SVF小于1。局部查询同理。这意味着独立检索再融合(HMV)相比于先融合信息再检索(SVF),能更有效地减少信息损失,实现更精准的知识定位。
实验结论
-
主要成果:在三个不同领域的问答数据集(CRUD、OmniEval、MultiFieldQA)上的实验表明,MoM框架训练的MemReader模型显著优于所有基线方法。尤其在CRUD新闻数据集上,即使是1.5B和3B参数量级的MemReader也超越了所有对比方法,展示了框架的高效性。在更具挑战性的金融(OmniEval)和多领域(MultiFieldQA)数据集上,MemReader同样展现出强大泛化能力和最佳或次佳的性能。
-
对评估指标的探索:实验验证了本文提出的“分块清晰度”指标的有效性。该指标与衡量生成质量的ROUGE-L指标之间表现出强正相关性(相关系数在0.70-0.75之间),证明其可作为评估分块质量的直接、快速的度量。
| 评估模型 | 与ROUGE-L的相关系数 |
|---|---|
| 模型 1 | 0.7044 |
| 模型 2 | 0.7585 |
| 模型 3 | 0.7248 |
注:三种评估模型下的相关系数均表明强正相关。Qwen2.5-7B被用作基础评估模型。
-
对检索内容支持度的分析:为了更精细地评估检索模块的性能,本文设计实验直接量化了检索到的内容对生成正确答案的“信息支持度”。结果显示,在MultiFieldQA数据集上,MoM方法检索到的上下文内容能够为推断出正确答案提供最强的支持,优于所有其他方法。
-
最终结论:MoM框架通过主动、结构化的记忆提取,成功提升了RAG系统的性能上限。同时,它也证明了训练小型语言模型(SLM)实现以人为中心的高质量文本处理是可行的。