Multi-Agent Evolve: LLM Self-Improve through Co-evolution
-
ArXiv URL: http://arxiv.org/abs/2510.23595v3
-
作者: Muhan Zhang; Siqi Zhu; Yiding Wang; Haofei Yu; Jiaxuan You; Yixing Chen; Tao Feng
-
发布机构: NVIDIA; Peking University; University of Illinois at Urbana-Champaign
TL;DR
本文提出了一种名为“多智能体进化 (Multi-Agent Evolve, MAE)”的框架,通过让单个大语言模型扮演提问者 (Proposer)、解答者 (Solver) 和裁判 (Judge) 三个协同进化的角色,利用强化学习在无需人工标注数据的情况下实现通用推理能力的自我提升。
关键定义
- 多智能体进化 (Multi-Agent Evolve, MAE):一个多智能体自我进化框架。它从单个基础LLM中实例化出三个协同但又相互竞争的角色(Proposer, Solver, Judge),通过强化学习进行联合训练,形成一个闭环的自我完善系统,以提升模型在数学、推理和通用问答等多样化任务上的能力。
- Proposer (提问者):MAE框架中的智能体之一,负责生成新的问题。其目标是提出既可解又有挑战性的问题,以驱动Solver智能体能力的进化。
- Solver (解答者):MAE框架中的核心智能体,负责解答Proposer提出的问题。整个框架的主要目标就是提升Solver解决问题的能力。
- Judge (裁判):MAE框架中的评估智能体,采用“LLM即裁判 (LLM-as-a-Judge)”范式。它负责评估Proposer生成问题的质量和Solver生成答案的正确性,并为它们提供奖励信号,从而引导整个系统的进化方向。
- 协同进化 (Co-evolution):指Proposer和Solver在训练过程中相互促进、共同发展的过程。Proposer学习提出对当前Solver更具挑战性的问题,而Solver则通过解决这些难题来提升自身能力,形成一个良性循环。
相关工作
当前,使用强化学习 (Reinforcement Learning, RL) 提升大语言模型 (LLM) 推理能力的方法显示出巨大潜力,但严重依赖人工标注的数据集和可验证的奖励函数。这限制了方法的可扩展性和通用性。虽然一些自博弈 (Self-Play) 方法借鉴了其在棋类游戏中的成功经验,实现了无监督的自我提升,但它们大多依赖于有特定反馈的“落地环境” (grounded environment),如代码解释器或游戏引擎,难以推广到自然语言推理等开放域。
本文旨在解决的核心问题是:如何构建一个有效的强化学习框架,使LLM能够在通用领域(如数学、常识推理等)中,在不依赖人工标注和特定“落地环境”的情况下实现自我提升。
本文方法
本文提出了多智能体进化 (Multi-Agent Evolve, MAE) 框架。该框架的核心思想是让一个共享的LLM扮演三个不同的角色:提问者 (Proposer)、解答者 (Solver) 和裁判 (Judge),通过它们之间的互动与协同进化来提升LLM自身解决问题的能力。
 MAE框架从单个LLM中实例化出Proposer、Solver和Judge三个互动角色,形成一个闭环自提升系统。Proposer生成新问题,Solver尝试解答,Judge评估两者的产出并提供奖励信号。Judge会奖励Solver的准确推理,而Proposer则会同时收到来自Judge的质量奖励和在Solver失败时增加的难度奖励,从而形成对抗性的协同进化过程,持续增强模型的推理能力。
MAE框架从单个LLM中实例化出Proposer、Solver和Judge三个互动角色,形成一个闭环自提升系统。Proposer生成新问题,Solver尝试解答,Judge评估两者的产出并提供奖励信号。Judge会奖励Solver的准确推理,而Proposer则会同时收到来自Judge的质量奖励和在Solver失败时增加的难度奖励,从而形成对抗性的协同进化过程,持续增强模型的推理能力。
Proposer智能体
Proposer智能体的任务是提出既可解又有挑战性的问题。其目标有两个:(1) 生成被Judge评为高质量、结构良好的问题;(2) 生成对当前Solver具有挑战性的问题。
该智能体生成的每个问题 $q$ 的奖励 $R_{P}(q)$ 由三部分加权组成:
- 质量奖励 ($R_{quality}$):由Judge智能体提供,评估问题的清晰度和可解性。
- 难度奖励 ($R_{difficulty}$):衡量问题对当前Solver的挑战程度。它通过计算Solver对该问题的平均得分 $\bar{R}_{S}(q)$ 来得到,公式为 $R_{difficulty}(q)=1-\bar{R}_{S}(q)$。当Solver的平均分较低时,难度奖励更高。
- 格式奖励 ($R_{format}$):确保Proposer的输出符合预定义的格式(如包含 \(<question>\) 标签),以便后续程序能正确解析。
Proposer的总奖励公式为:
\[R_{P}(q)=\lambda_{quality}R_{quality}+\lambda_{difficulty}R_{difficulty}+\lambda_{format}R_{format}\]此外,框架还引入了质量过滤 (Quality Filtering) 机制,即只有Judge评分高于特定阈值(如0.7)的问题才会被加入到有效问题池中,以防止在长期训练中问题质量下降。
Solver智能体
Solver智能体的任务是针对Proposer提出的问题 $q$ 生成高质量的答案 $a$。整个MAE框架的最终目的就是提升Solver的能力。
Solver生成的每个答案 $a$ 的奖励 $R_{S}(a)$ 由两部分加权构成:
- 裁判奖励 ($R_{judge}$):这是Solver最主要的奖励来源。由于框架设计用于通用领域,问题可能没有标准答案,因此奖励由Judge智能体根据答案的质量和正确性进行评估后给出,即 $R_{judge}=V_{J}(a,q)$。
- 格式奖励 ($R_{format}$):与Proposer类似,该奖励确保Solver的输出包含正确的标签(如 \(<answer>\)),便于系统自动解析。
Solver的总奖励公式为:
\[R_{S}(a)=\lambda_{judge}R_{judge}+\lambda_{format}R_{format}\]Judge智能体
Judge智能体扮演着一个生成式奖励模型的角色,为Proposer和Solver提供数值化的奖励分数。它采用思维链 (Chain-of-Thought) 的方式,先生成详细的分析,再输出最终分数,确保评估的合理性。Judge根据严格的评分标准执行两项评估任务:
- 评估答案:评估Solver的答案时,最看重正确性。任何事实、逻辑或计算错误都会导致得分在 \([1,3]\) 区间;事实正确但有小瑕疵的答案得分在 \([4,7]\) 区间;只有完美无瑕的答案才能获得 \([8,10]\) 的高分。
- 评估问题:评估Proposer提出的问题时,最看重可解性和逻辑一致性。无法解决、自相矛盾的问题得分低;有歧义但大体合理的问题得分居中;清晰、逻辑性强的问题得分高。
为了保证整个自动化训练环路的稳定性,Judge自身也需要接受训练。其奖励来自于一个格式奖励 ($R_{format}$),激励其输出结构清晰、可被程序解析(即包含唯一的 \(<score>X</score>\) 标签)。
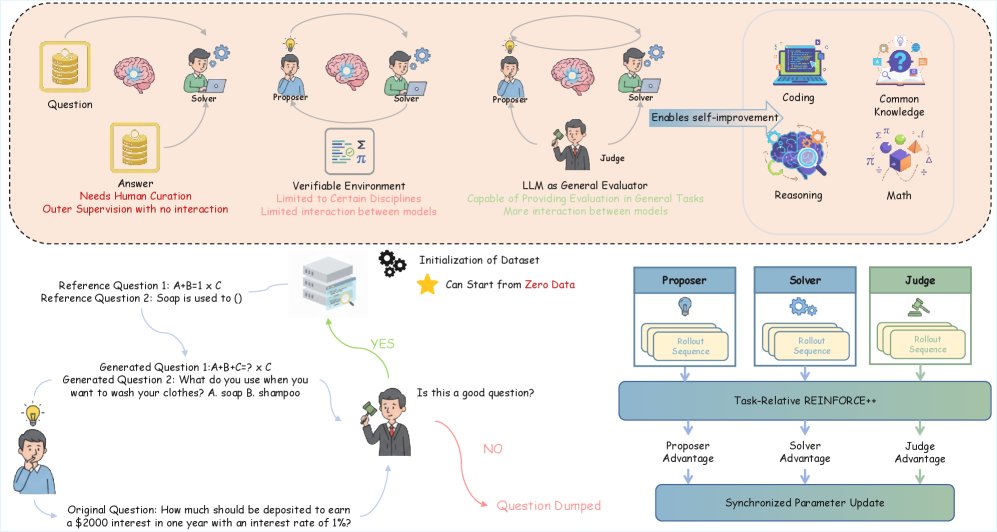 (上) MAE利用LLM自身作为通用评估器,评估问题和答案。这带来了对通用任务的适应性和智能体间更强的互动性。(左下) 框架将质量过滤技术应用于Proposer的生成循环,防止在长期训练中数据集质量下降。(右下) 多智能体训练采用Task-Relative REINFORCE++,为每个角色分别计算优势函数,然后对统一模型进行同步参数更新。
(上) MAE利用LLM自身作为通用评估器,评估问题和答案。这带来了对通用任务的适应性和智能体间更强的互动性。(左下) 框架将质量过滤技术应用于Proposer的生成循环,防止在长期训练中数据集质量下降。(右下) 多智能体训练采用Task-Relative REINFORCE++,为每个角色分别计算优势函数,然后对统一模型进行同步参数更新。
智能体间的协调
MAE的训练流程如下(见算法1):
- Propose阶段:Proposer从现有问题池中采样参考问题或从零开始生成一批新问题。
- Judge评估问题:Judge对新生成的问题进行质量评估和打分。只有评分合格的问题才会被加入问题池。
- Solve阶段:Solver从问题池中采样问题并生成答案。
- Judge评估答案:Judge对Solver生成的答案进行评估和打分。
- 梯度更新:收集完Proposer、Solver和Judge各自的奖励后,使用一种名为 Task-Relative REINFORCE++ 的算法计算各自的梯度,并对共享的LLM模型参数进行同步更新。
创新点
- 通用域自博弈:将自博弈范式从依赖代码解释器等“落地环境”的领域,成功扩展到了无需外部验证器的通用推理领域。
- 三位一体的闭环进化:创新性地让单个LLM扮演Proposer、Solver和Judge三个角色,形成了一个高效、数据利用率高的闭环自我提升系统。通过角色间的协同进化,模型能够自我生成训练数据并提供奖励信号。
- 领域无关的奖励设计:设计了基于内部Judge评估的质量奖励、难度奖励和格式奖励,摆脱了对人工标注的“标准答案”的依赖,使框架能够适用于任意领域。
- 稳定的训练机制:集成了质量过滤和格式奖励等机制,确保了在长期自博弈训练过程中的稳定性和数据质量,避免了以往方法中常见的模型能力退化或崩溃问题。
实验结论
本文在 Qwen2.5-3B-Instruct 模型上进行了实验,以验证MAE框架的有效性。实验分为使用参考问题和不使用参考问题两种设定。
结果与发现
以下是主要的实验结果表格:
| Model | GSM8K | MATH | HumanEval | ARC-C | MMLU | BBH | Overall Avg. | ID Avg. | OOD Avg. | |
|---|---|---|---|---|---|---|---|---|---|---|
| w/o reference | Base | 60.40 | 6.80 | 18.00 | 80.60 | 50.81 | 43.10 | 57.72 | 65.59 | 39.54 |
| AZR | 59.80 | 6.80 | 18.00 | 74.36 | 45.42 | 41.76 | 57.72 | 63.85 | 39.54 | |
| MAE(zero) | 64.20 | 7.40 | 18.60 | 83.90 | 52.28 | 46.70 | 58.51 | 67.43 | 42.45 | |
| with reference | Base | 60.40 | 6.80 | 18.00 | 80.60 | 50.81 | 43.10 | 55.33 | 64.91 | 38.31 |
| SFT | 63.60 | 6.80 | 17.40 | 80.40 | 51.04 | 36.36 | 53.87 | 63.28 | 37.41 | |
| MAE(no reference) | 64.40 | 7.60 | 18.00 | 83.25 | 51.87 | 43.20 | 58.18 | 66.86 | 42.48 | |
| MAE(with reference) | 66.20 | 7.80 | 19.20 | 82.52 | 51.52 | 41.60 | 58.62 | 68.07 | 43.18 | |
| MAE(half reference) | 65.40 | 7.60 | 18.00 | 84.84 | 51.52 | 45.45 | 59.98 | 68.95 | 43.96 |
- 在无参考问题的情况下:MAE (zero) 设置仅从极少数种子问题开始,不使用任何真实世界数据。即便如此,它在大多数基准测试中都超越了基础模型和强大的AZR基线。这证明了MAE框架仅通过多角色协同进化就能有效提升模型的通用能力。
- 在使用参考问题的情况下:
- 首先,标准的监督微调 (SFT) 基线在使用带标准答案的种子数据进行训练后,性能反而下降,这可能是因为数据集分布广泛而规模有限所致。
- 相比之下,所有MAE变体都显著优于SFT基线,即使MAE并未使用标准答案。
- 表现最佳的是 \(MAE (half reference)\) 设置,它在生成新问题时,一半情况参考现有问题,一半情况从零开始创造。这种在“利用”和“探索”之间取得平衡的策略,在分布内 (ID) 和分布外 (OOD) 的测试集上均取得了最高的平均分,总体平均分达到59.98%,相比基础模型提升了4.65%。
训练稳定性与曲线分析
MAE框架展现了优秀的训练稳定性。模型可以在250个训练步长(批量大小为128)中持续提升性能,远超之前一些自博弈方法仅能迭代数次的表现。这得益于高质量的问题池和三个智能体间的稳定互动。训练曲线显示,问题池中的问题数量稳步增加,同时Proposer逐渐学会生成对Solver有适当挑战性的问题,这表明协同进化机制在有效运作。
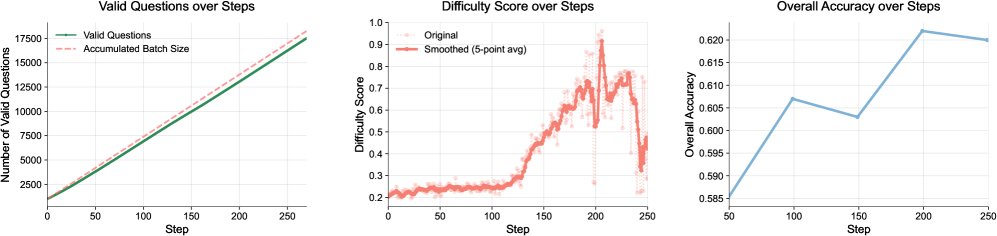 (左) 数据集中的问题数量稳定增长,同时低质量问题被有效过滤。(中和右) Proposer学会生成对Solver具有理想难度的问题,从而促进模型在后续训练中的进步。
(左) 数据集中的问题数量稳定增长,同时低质量问题被有效过滤。(中和右) Proposer学会生成对Solver具有理想难度的问题,从而促进模型在后续训练中的进步。
最终结论:实验结果有力地证明,Multi-Agent Evolve是一个可扩展、数据高效的框架,能够以最少的人工监督,显著增强大语言模型在数学、推理、编码和通用问答等多个领域的综合能力。