Multimodal Deep Learning
-
ArXiv URL: http://arxiv.org/abs/2301.04856v1
-
作者: A. Khosla; Juhan Nam; Honglak Lee; Jiquan Ngiam; A. Ng; Mingyu Kim
TL;DR
本文是一份关于多模态深度学习的综合性技术手册,系统性地梳理了该领域从基础的单模态技术到前沿的多模态架构,核心在于根据模态间的交互方式对多模态模型进行了清晰的分类,并展望了未来的发展趋势。
引言
“多模态” (multimodal) 指的是像人类一样,同时结合来自不同渠道(如视觉、听觉、文本)的信息来理解世界。多模态深度学习旨在借鉴人类的学习过程,训练人工智能模型处理和融合多种类型的数据。
本文首先介绍了自然语言处理 (Natural Language Processing, NLP) 和计算机视觉 (Computer Vision, CV) 这两个核心领域的前沿技术,它们是构建多模态模型的基础。随后,重点剖析了多模态架构,并根据信息转换和辅助的方向将其分为几大类:文图互生成(Image2Text, Text2Image)、模态间相互辅助以增强表征学习,以及能够同时处理两种模态的联合模型。最后,文章探讨了将模型扩展到更多模态(如视频、语音、表格数据)的挑战,并介绍了通用模型和生成艺术等前沿应用。
介绍模态
本章介绍了构建多模态模型所依赖的两个基础领域:自然语言处理(NLP)和计算机视觉(CV)的最新进展,以及相关的基准资源。
自然语言处理 (NLP) 的最新进展
NLP 领域的发展历程中出现了几个关键突破:
- 词嵌入 (Word Embeddings):该技术将单词表示为稠密的数值向量,使得语义相近的词在向量空间中也相互靠近。它克服了传统独热编码 (one-hot encoding) 的稀疏性和无法捕捉词间相似性的问题。Word2vec 和 GloVe 是代表性方法。
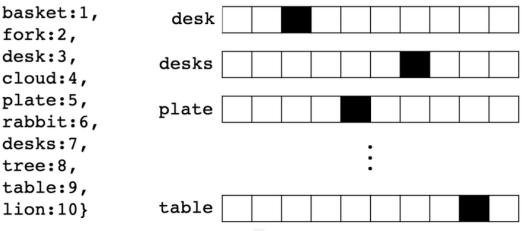 FIGURE 2.1: 十个独热编码的单词
FIGURE 2.1: 十个独热编码的单词 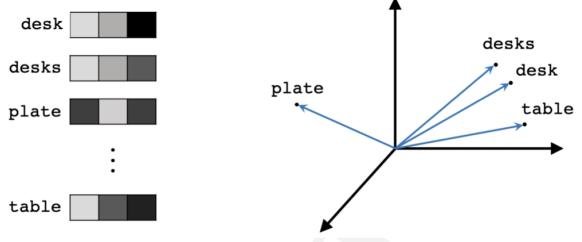 FIGURE 2.2: 三维词嵌入示意图
FIGURE 2.2: 三维词嵌入示意图 - 编码器-解码器 (Encoder-Decoder):也称为序列到序列 (sequence-to-sequence) 架构,它能够将一个可变长度的输入序列映射到一个可变长度的输出序列。编码器将输入序列压缩成一个固定长度的上下文向量 (context vector) \(c\),解码器则基于该向量生成输出序列。这种架构在机器翻译等任务中非常有效。
 FIGURE 2.6: 简化的序列到序列模型进行翻译
FIGURE 2.6: 简化的序列到序列模型进行翻译 - 注意力机制 (Attention Mechanism):为了解决编码器-解码器架构中单一上下文向量成为信息瓶颈的问题,注意力机制被提出。它允许解码器在生成每个输出时,都能“关注”到输入序列中最相关的部分,并赋予更高的权重。这极大地提升了长序列任务的性能。
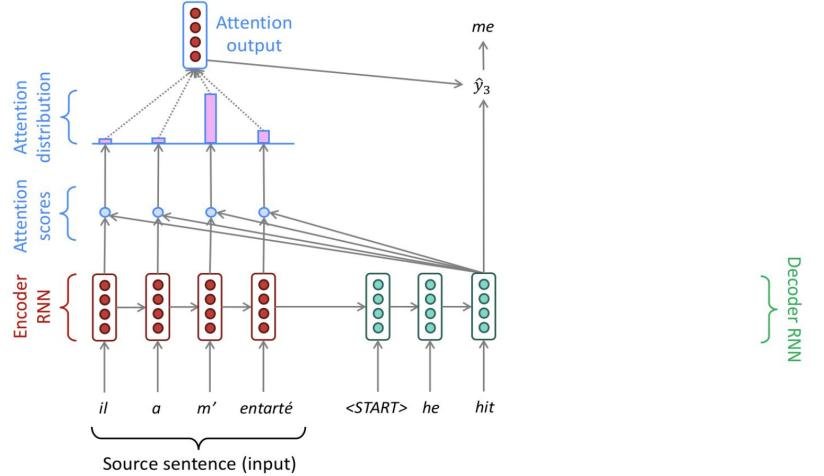 FIGURE 2.9: 带有注意力机制的翻译过程
FIGURE 2.9: 带有注意力机制的翻译过程 - Transformer:这一架构完全摒弃了循环神经网络 (RNN) 的顺序处理方式,完全基于自注意力 (self-attention) 机制。自注意力使得模型在处理序列中的每个词时,都能同时计算其与序列中所有其他词的关联度。这种设计允许大规模并行计算,极大地提高了训练效率,并能更好地捕捉长距离依赖关系。Transformer 已成为当今 NLP 领域的主导架构,催生了 BERT、GPT 等著名模型。
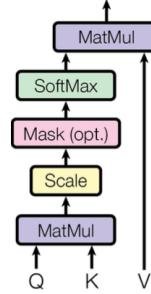 FIGURE 2.15: 缩放点积注意力 (Scaled dot-product attention)
FIGURE 2.15: 缩放点积注意力 (Scaled dot-product attention)
计算机视觉 (CV) 的最新进展
CV 领域同样取得了显著进展,主要体现在以下几个方面:
- 网络优化:通过改进网络结构来提升图像分类的精度。例如,ResNet 引入残差学习框架解决深度网络训练退化问题;EfficientNet 则提出一种复合缩放方法,系统性地平衡网络深度、宽度和图像分辨率,以实现更高的效率和准确性。
- 自监督学习 (Self-supervised learning):在不依赖人工标注的情况下学习有效的视觉表征。SimCLR 提出了一个简单的对比学习框架,通过最大化同一图像不同增强视图(正样本对)的相似度,和最小化不同图像视图(负样本对)的相似度来学习。BYOL 则是一种非对比学习方法,它通过预测一个视图的表征来匹配另一个视图的编码,避免了使用负样本。
- 视觉 Transformer (Vision Transformer):受 NLP 领域的启发,研究者将 Transformer 架构直接应用于图像处理。通过将图像分割成小块 (patches) 并视其为序列 Token,ViT 模型在图像分类等任务上取得了与卷积神经网络 (CNN) 相媲美甚至更好的结果。
资源与基准
无论是 NLP 还是 CV,大规模数据集的预训练都至关重要。
- NLP 数据集:通常使用海量文本语料库,如维基百科、BookCorpus 和 CommonCrawl。
- CV 数据集:ImageNet 是最经典的分类基准数据集。
- 多模态数据集:视觉语言任务需要高质量的图文对数据,如 COCO、Visual Genome、Conceptual Captions 和 LAION-5B(目前最大的公开图文对数据集)。
- 基准 (Benchmarks):用于评估和比较模型性能。NLP 领域有 GLUE、SuperGLUE 等。CV 领域有 ImageNet、COCO 等。多模态领域则有 VQA(视觉问答)、VCR(视觉常识推理)、Flickr30K 等。
多模态架构
本章是本文的核心,它根据模态间的交互方式和任务目标,对多模态深度学习模型进行了系统的分类。这个分类体系清晰地揭示了不同架构的设计思想和应用场景。
分类体系
该分类体系主要基于数据流向和模态间的关系,具体维度如下:
- 生成与转换:一个模态的数据被用来生成另一个模态的数据。
- 单向辅助:一个模态作为辅助信息,用来增强另一个主模态的表征学习或任务性能。
- 联合处理:两个模态被同等对待,模型学习它们之间深度的联合表征。
3.1 Image2Text (图像到文本)
这类任务的目标是将输入的图像转换为文本描述,最典型的应用是图像描述生成 (Image Captioning)。
- 数据集:Microsoft COCO 是该领域的关键数据集,提供了大量带有多条人工描述的图像。
- 模型:M2 Transformer (Meshed-Memory Transformer) 是一个代表性模型。它利用 Transformer 架构,通过一种网状的记忆机制来同时编码图像的区域特征和先前的文本描述,从而生成更准确和相关的文本。
3.2 Text2Image (文本到图像)
这类任务与 Image2Text 相反,目标是根据文本提示生成对应的图像。
- 早期方法:生成对抗网络 (Generative Adversarial Networks, GANs) 和 变分自编码器 (Variational Autoencoders, VAEs) 是早期的主流技术。
- 前沿模型:随着技术发展,基于 Transformer 和扩散模型 (Diffusion Models) 的架构取得了突破性进展。DALL-E 和 GLIDE 是其中的佼佼者,它们能够根据复杂的文本描述生成高质量、富有创意甚至达到照片级逼真度的图像。
3.3 Images supporting Language Models (图像辅助语言模型)
在这类架构中,视觉信息被用来“锚定”或丰富语言模型的理解能力,即视觉接地 (visual grounding)。
- 实现方式:通过将图像特征与词嵌入进行融合,可以采用顺序嵌入、更高级的接地嵌入或在 Transformer 内部进行融合等方式。其核心思想是让语言模型不仅仅理解文本符号,更能将其与现实世界的视觉概念联系起来。
3.4 Text supporting Vision Models (文本辅助视觉模型)
这类模型利用大规模的文本数据来改善视觉模型的学习效果,尤其是在零样本 (zero-shot) 学习能力上。
- 核心思想:通过对比学习 (contrastive learning) 在一个共享的嵌入空间中对齐图像和其对应的文本描述。
- 代表模型:
- CLIP (Contrastive Language-Image Pre-training):通过在海量图文对上进行预训练,CLIP 学会了将图像和描述其内容的文本映射到相近的向量位置。这使得它无需针对特定任务进行微调,就能在各种下游分类任务中实现强大的零样本识别能力。
- ALIGN 和 Florence 也采用了类似的思想,但在数据规模和模型设计上有所不同。这些模型通常被称为“基础模型” (foundation models),因为它们可以作为其他复杂模型(如 DALL-E 2)的基石。
3.5 Models for both modalities (双向/联合模型)
这类架构旨在同时处理和理解图像与文本两种模态,学习它们之间更深层次的交互和联合表征。
- 核心机制:通常采用协同注意力 (co-attention) 机制,允许模型在一个模态的上下文中关注另一个模态的特定部分,反之亦然。
- 代表模型:
- VilBERT:将流行的 BERT 架构扩展为双流模型,一个流处理图像区域,另一个流处理文本,并通过协同注意力层进行交互。
- Flamingo:谷歌 DeepMind 提出的一个强大的视觉语言模型。它通过冻结预训练好的视觉模型和语言模型,并引入新颖的交叉注意力层,实现了强大的少样本学习 (few-shot learning) 能力,能用一个模型处理多种不同的多模态任务。
- Data2Vec:提出了一种通用的学习方法,可统一应用于语音、视觉和语言模态,旨在探索一种不依赖特定模态的通用表征学习范式。
其他主题
本章探讨了多模态学习的前沿方向和更广泛的应用,指出了未来的研究机遇与挑战。
4.1 引入更多模态
多模态学习的未来远不止于图像和文本。研究正向着包含更多模态(如视频、音频、表格数据等)的通用模型发展。
- 核心挑战:
- 多模态融合 (Multimodal Fusion):如何有效地结合来自不同模态、具有不同统计特性和数据结构的信息。
- 对齐 (Alignment):如何在不同模态的数据元素之间建立有意义的对应关系(例如,将视频中的动作与语音中的描述词对齐)。
- 表征方式:选择联合表征 (joint representation)(将所有模态映射到同一个共享空间)还是协同表征 (coordinated representation)(为每个模态维护独立但相关的空间)是一个关键的设计决策。
4.2 结构化与非结构化数据融合
许多现实世界的应用需要同时处理非结构化数据(如图像、文本)和结构化数据(如表格、数据库记录)。本节探讨了不同的融合策略,并通过在生存分析和经济学领域的两个用例来说明其应用价值。
4.3 通用模型 (Multipurpose Models)
这是多模态研究的宏大目标之一:创建一个单一的、统一的模型,能够处理来自不同模态的输入,并胜任多种不同的任务。
- 代表项目:谷歌的 “Pathway” 模型旨在构建这样一个能够动态扩展和适应不同任务与模态的单一架构,被认为向通用人工智能迈出的一步。
4.4 生成艺术 (Generative Art)
本节展示了多模态深度学习的一个引人注目的应用。像 DALL-E 这样的文本到图像生成模型,已经被艺术家们用来创作新颖的艺术作品,模糊了技术与创造力之间的界限。
结论
本文系统性地回顾了多模态深度学习的关键技术和架构。通过从 NLP 和 CV 的基础技术讲起,逐步深入到各类多模态模型的分类体系,清晰地展示了该领域的发展脉络。其核心贡献在于根据模态间的数据流向和交互关系,将现有模型划分为模态转换 (Image2Text, Text2Image)、单向辅助 (Text-supports-Vision, Image-supports-Language) 和联合处理三大类。最后,文章展望了该领域向着引入更多模态、融合结构化数据以及构建通用模型的未来发展方向,凸显了多模态学习在推动人工智能走向更全面、更类人智能的道路上的巨大潜力。