Object Recognition Datasets and Challenges: A Review
-
ArXiv URL: http://arxiv.org/abs/2507.22361v1
-
作者:
-
发布机构: University of British Columbia
TL;DR
本文通过对超过160个数据集的统计和描述,对物体识别领域的数据集和挑战赛进行了全面的回顾与分析,重点探讨了数据集在推动算法发展中的关键作用、主要数据集的演进趋势以及评估基准的变化。
关键定义
本文主要沿用并梳理了计算机视觉领域已有的核心概念,并未提出新的定义。关键概念如下:
- 物体识别 (Object Recognition):一个通用术语,涵盖了图像分类、物体定位、物体检测、实例分割和语义分割等一系列相关的计算机视觉任务。
- 图像分类 (Image Classification):为整张图像分配一个类别标签。
- 物体检测 (Object Detection):在图像中定位感兴趣的物体并为其分配类别标签,通常通过边界框(Bounding Box)实现。
- 语义分割 (Semantic Segmentation):为图像中的每个像素分配一个类别标签(类别感知),不区分同一类的不同实例。
- 实例分割 (Instance Segmentation):在像素级别识别物体边界,并区分同一类别的不同实例(实例感知)。
- 全景分割 (Panoptic Segmentation):结合语义分割和实例分割,对图像中的所有像素进行分割,既要识别“事物”(Things,可数物体)的实例,也要分割“材料”(Stuff,背景区域)。
相关工作
物体识别是计算机视觉的基础任务之一。随着研究的深入,特别是深度学习技术的兴起,算法的性能越来越依赖于大规模、高质量的训练数据。在算法发展的每个阶段,都有相应的数据集被构建出来以匹配当时最先进算法的能力。
然而,现有文献中虽然有许多关于算法进展和应用的综述,但缺乏一篇专门从数据集发展的角度对物体识别领域进行深入分析的综述。本文旨在填补这一空白,通过详细剖析过去二十年中主流物体识别数据集的演进、挑战和趋势,为研究者提供一个关于数据在物体识别领域所扮演角色的全面理解,并为未来的数据集构建指明方向。
背景
物体识别任务概述
物体识别是涵盖多个具体任务的总称。这些任务在粒度和目标上有所不同,构成了一个层次化的理解体系。
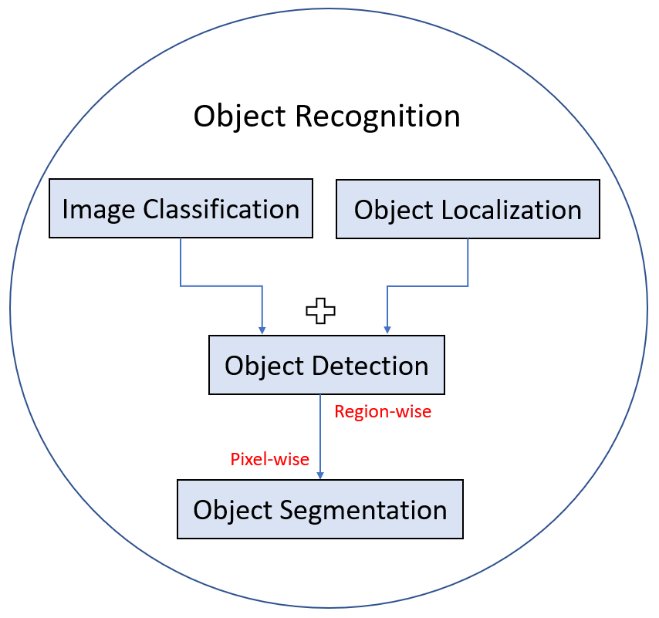
- 图像分类:判断图像整体属于哪个类别。
- 物体定位 (Object Localization):在图像中用边界框标出单个或多个物体的位置。
- 物体检测:结合了定位和分类,找出所有感兴趣的物体并给出其类别。
- 图像分割:在像素层面进行划分。
- 语义分割:为每个像素标记其所属的类别(如所有标记为“车”的像素)。
- 实例分割:不仅标记类别,还区分同类别的不同个体(如“车1”、“车2”)。
物体识别历史里程碑
物体识别算法和数据集的发展历程与技术进步紧密相连,大致可分为深度学习兴起前后的两个阶段。
深度学习前时代(2012年以前): 早期的算法主要依赖于为特定应用设计的精巧的手工特征,如 SIFT (Scale-Invariant Feature Transform) 、HOG (Histogram of Oriented Gradients) 等。数据集也多为特定应用而生,如人脸识别的FERET、手写数字识别的MNIST。这些数据集通常分辨率较低,场景简单,物体姿态受控。PASCAL VOC系列挑战赛的推出,为当时的算法提供了一个标准的基准测试平台,推动了领域发展。
深度学习时代(2012年至今): 2012年,AlexNet在ImageNet大规模视觉识别挑战赛 (ILSVRC) 上取得突破性成功,标志着深度学习时代的到来。这证明了大规模、高质量标注的数据集对于释放深度神经网络(DCNNs)潜力的重要性。此后,算法和数据集的复杂性都大幅提升。
- 算法演进:出现了一系列经典的深度学习模型,如R-CNN系列 (R-CNN, Fast R-CNN, Faster R-CNN)、SSD、YOLO系列、用于实例分割的Mask R-CNN,以及用于语义分割的DeepLab系列和U-Net等。
- 数据集演进:数据集向着更大规模、更精细标注(从边界框到像素级掩码)、更自然场景(而非标志性视图)的方向发展。
下图展示了物体识别算法和数据集发展的关键里程碑。 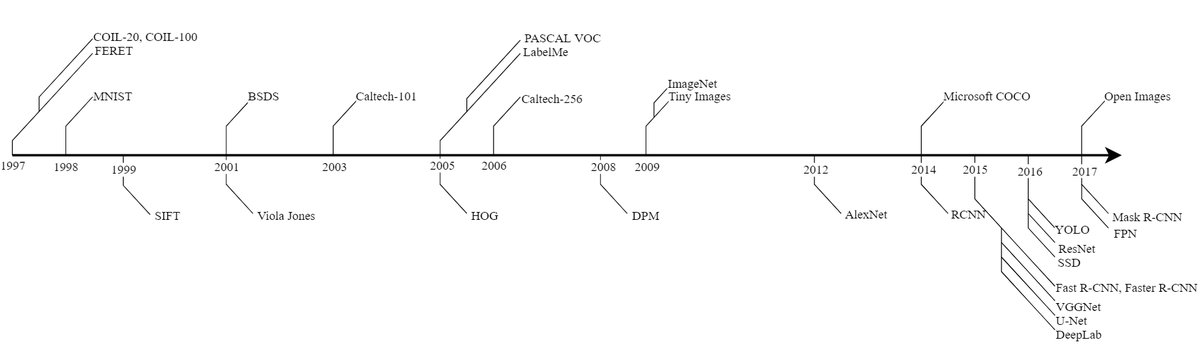
评估指标
为了量化评估算法性能,本文介绍了几种核心指标。这些指标基于以下四个基本概念:
- 真阳性 (True Positive, TP):正确预测为正例。
- 假阳性 (False Positive, FP):错误预测为正例。
- 真阴性 (True Negative, TN):正确预测为负例。
- 假阴性 (False Negative, FN):错误预测为负例。
主要评估指标
-
精确率 (Precision):预测为正的样本中有多少是真正的正例。
\[Precision=\frac{TP}{TP+FP}\] -
召回率 (Recall):所有真实正例中有多少被成功预测。
\[Recall=\frac{TP}{TP+FN}\] -
准确率 (Accuracy):所有样本中被正确预测的比例。
\[Accuracy=\frac{TP+TN}{TP+TN+FP+FN}\] -
$F_1$ 分数 ($F_1$ Score):精确率和召回率的调和平均数,用于综合考量两者。
\[F_1=2\frac{precision\times recall}{precision+recall}\] -
交并比 (Intersection over Union, IoU):预测区域与真实区域的交集面积除以并集面积,是衡量检测和分割任务中预测区域准确度的常用指标。
\[IoU=\frac{Area of Overlap}{Area of Union}=\frac{TP}{TP+FN+FP}\] - 平均精度 (Average Precision, AP):在不同召回率水平下精确率的平均值,常用于评估单个类别的检测或分割性能。通过对所有类别的AP取平均,得到平均精度均值 (mean Average Precision, mAP)。
-
全景质量 (Panoptic Quality, PQ):用于评估全景分割任务,同时衡量分割质量和检测质量。
\[PQ=\frac{\sum_{(p,q)\in TP}IoU(p,g)}{ \mid TP \mid +\frac{1}{2} \mid FP \mid +\frac{1}{2} \mid FN \mid }\]其中,第一项是匹配分割的平均IoU(分割质量),第二项是类$F_1$分数(检测质量)。
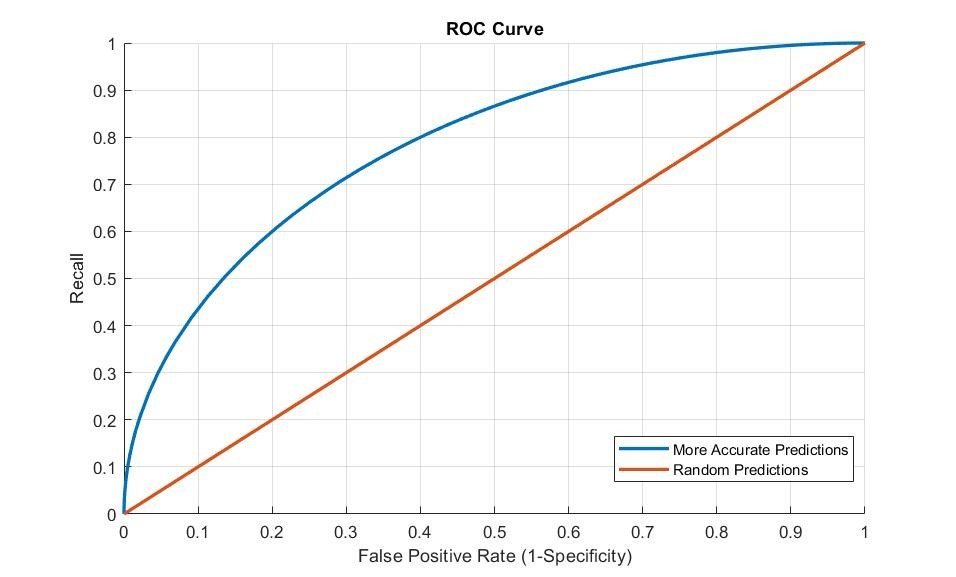 Figure 3: ROC Curve
Figure 3: ROC Curve
- ROC曲线 (Receiver Operative Characteristic Curve):通过绘制真阳性率(召回率)与假阳性率(1-特异度)的关系曲线来评估分类器性能。曲线下面积(AUC)越大,性能越好。
通用物体识别数据集
近年来,公开的标注数据集数量激增。本节对通用物体识别数据集及其相关挑战赛进行综述。
主要大规模数据集
有四个公认的主要大规模物体识别数据集,它们极大地推动了领域的发展。
| 数据集 | 类别数 | 图像数 | 每张图平均物体数 | 首次发布 | | :— | :— | :— | :— | :— | | PASCAL VOC | 20 | 22,591 | 2.3 | 2005 | | ImageNet | 21,841 | 14,197,122 | 3 | 2009 | | Microsoft COCO | 91 | 328,000 | 7.7 | 2014 | | Open Images | 600 | 9,178,275 | 8.1 | 2017 | Table 1: PASCAL VOC, ImageNet, MS COCO, 和 Open Images 的数据集统计
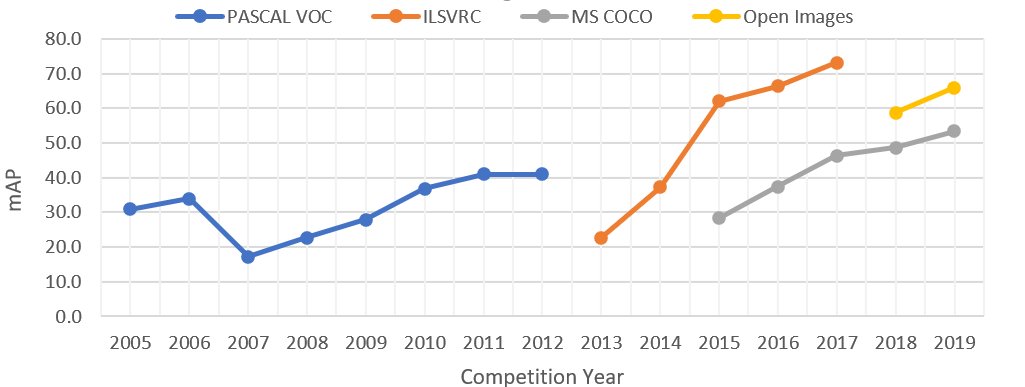 Figure 4: 主要挑战赛物体检测赛道获胜算法的准确率提升。PASCAL VOC 2007年准确率下降是由于类别从4个增加到20个。
Figure 4: 主要挑战赛物体检测赛道获胜算法的准确率提升。PASCAL VOC 2007年准确率下降是由于类别从4个增加到20个。
数据集概述
- PASCAL VOC:最早的大型挑战赛数据集,于2005年发布。它奠定了物体识别评估指标的基础。虽然规模相对较小,但仍被用作新算法的便捷基准。
- ImageNet:于2010年推出,拥有千万级的图像和上万个细粒度类别。其层次化结构基于WordNet。ILSVRC挑战赛(2010-2017)极大地推动了深度学习的发展。ImageNet至今仍是预训练复杂模型的标准数据集,但其每图仅单物体标注和缺乏丰富上下文的缺点也催生了更复杂的数据集。
- Microsoft COCO:为解决ImageNet的问题而生,图像数量较少但标注更丰富。它强调物体在自然上下文中的表现,并提供像素级的实例分割掩码。COCO还注重类别间的实例数量平衡,并发布了补充的COCO-Stuff数据集用于背景区域分割。
- Open Images:最新一代的大规模数据集,包含超过九百万张图像、600个物体类别的边界框以及部分分割掩码。其特点是引入了视觉关系标注(如“人骑自行车”)和负标签(明确指出图像中不存在的物体),以增强模型的分类能力。
挑战赛任务
四大挑战赛涵盖了从简单到复杂的各种任务,其评估标准也随之演进。
| 挑战赛 | 任务 | 类别数 | 图像 | 已标注物体 | 活跃年份 | 任务描述 | 评估指标 | | :— | :— | :— | :— | :— | :— | :— | :— | | PASCAL VOC | 图像分类 | 20 | 11,540 | 27,450 | 2005 - 2012 | 预测每张图中是否至少存在一个各类别的实例 | AP | | | 检测 | 20 | 11,540 | 27,450 | 2005 - 2012 | 为图像中所有挑战类别的实例预测边界框 | AP (IoU > 0.5) | | | 分割 | 20 | 2,913 | 6,929 | 2007 - 2012 | 对物体类别进行语义分割 | IoU | | ILSVRC | 图像分类 | 1000 | 1,331,167 | 1,331,167 | 2010 - 2014 | 对每张图的一个已标注类别进行分类 | Top-5预测的二元类别错误率 | | | 物体检测 | 200 | 476,688 | 534,309 | 2013 - 2017 | 为每张图的所有实例预测边界框 | AP(IoU阈值与框大小成比例) | | MS COCO | 检测 | 80 | 123,000+ | 500,000+ | 2015 - 至今 | 对物体类别(things)进行实例分割 | AP at IoU in [0.5:0.05:0.95] | | | 关键点 | 17 | 123,000+ | 250,000+ | 2017 - 至今 | 同时进行物体检测和关键点定位 | 基于OKS的AP | | | Stuff | 91 | 123,000+ | - | 2017 - 至今 | 对背景类别进行像素级分割 | mIoU | | | 全景 | 171 | 123,000+ | 500,000+ | 2018 - 至今 | 对图像进行完整分割(stuff 和 things) | Panoptic Quality (PQ) | | Open Images | 物体检测 | 500 | 1,743,042 | 12,421,955 | 2018 - 至今 | 基于层次结构的边界框检测 | mAP | | | 实例分割 | 300 | 848,000 | 2,148,896 | 2018 - 至今 | 对物体类别进行实例分割;包含负标签以优化训练 | mAP (IoU > 0.5) | | | 视觉关系检测 | 57 | 1,743,042 | 380,000关系三元组 | 2018 - 至今 | 用关系三元组标记图像 | mAP和召回率的加权和 | Table 2: PASCAL VOC, ILSVRC, MS COCO, 和 Open Images 的挑战赛描述
- 分类:主要在PASCAL VOC和ILSVRC中出现,后者采用Top-5错误率作为标准。
- 检测:四大挑战赛均包含此任务,但评估标准从固定的IoU阈值(PASCAL VOC, Open Images)演变为更复杂的动态阈值(ILSVRC)和多阈值平均(MS COCO)。
- 分割:从PASCAL VOC的语义分割,发展到MS COCO更全面的实例分割、Stuff分割和全景分割,评估指标也从简单的IoU发展到更综合的PQ。
- 特定任务:各挑战赛还推出了特定应用的任务,如PASCAL VOC的人体部件布局、MS COCO的人体关键点检测和Open Images的视觉关系检测,推动了更细分领域的发展。
其他物体识别数据集
除了上述四大主流数据集,还存在许多其他有价值的数据集。
物体检测数据集
尽管趋势是向分割掩码发展,但边界框标注因其成本低、一致性高而仍在许多数据集中使用。
| 数据集 | 图像数 | 类别数 | 边界框数 | 年份 | | :— | :— | :— | :— | :— | | Caltech 101 [75] | 9,144 | 102 | 9,144 | 2003 | | MIT CSAIL [234] | 2,500 | 21 | 2,500 | 2004 | | Caltech 256 [92] | 30,307 | 257 | 30,307 | 2006 | | Visual Genome [126] | 108,000 | 76,340 | 4,102,818 | 2016 | | YouTube BB [197] | 5.6 m | 23 | 5.6 m | 2017 | | Objects 365 [211] | 638,000 | 365 | 10.1 m | 2019 | Table 3: 通用物体检测数据集(不含3.1节中已介绍的)
物体分割数据集
这些数据集提供实例级或语义级的分割掩码。近年来,视频物体分割 (Video Object Segmentation, VOS) 成为一个热门方向,DAVIS和YouTube-VOS是该领域的主要基准。
| 数据集 | 图像数 | 类别数 | 物体数 | 年份 | 挑战赛 | 描述 | | :— | :— | :— | :— | :— | :— | :— | | SUN [256] | 130,519 | 3819 | 313,884 | 2010 | 否 | 主要用于场景识别,但也提供了实例级分割掩码 | | SBD [95] | 10,000 | 20 | 20,000 | 2011 | 否 | PASCAL VOC训练/验证图像上的物体轮廓 | | Pascal Part [46] | 11,540 | 191 | 27,450 | 2014 | 否 | PASCAL VOC数据集中20个类别的物体部件分割 | | DAVIS [30] | 150 (视频) | 4 | 449 | 2016 | 是 | 一个专注于半监督和无监督分割任务的视频物体分割数据集和挑战赛 | | YouTube-VOS [260] | 4,453 | 94 | 7,755 | 2018 | 是 | 从短视频片段(3-6秒)收集的视频物体分割数据集 | | LVIS [94] | 164,000 | 1000 | 2 m | 2019 | 是 | 针对长尾分布类别的实例分割标注,这些类别样本很少 | | LabelMe[207] | 62,197 | 182 | 250,250 | 2005 | 否 | 实例级分割;部分背景类别也被标注 | Table 4: 物体分割数据集
场景理解数据集中的物体识别
对图像的全面理解不仅需要识别物体,还需要理解场景。单纯的物体识别可能提供一些上下文线索,但也可能产生误导。背景属性(Stuff),如草地、天空,在传统物体识别数据集中常被忽略,但它们对提供几何关系和上下文推理至关重要。因此,许多以场景为中心的数据集被提出来,以实现更深层次的视觉理解。