Octo: An Open-Source Generalist Robot Policy
-
ArXiv URL: http://arxiv.org/abs/2405.12213v2
-
作者: H. Walke; Dibya Ghosh; Quan Vuong; Kevin Black; Chelsea Finn; Oier Mees; Tobias Kreiman; Jianlan Luo; Dorsa Sadigh; Sergey Levine; 等8人
-
发布机构: Carnegie Mellon University; Google DeepMind; Stanford; University of California, Berkeley
TL;DR
本文介绍了一款名为 Octo 的开源通用机器人策略 (generalist robot policy),它是一个基于 Transformer 的大型策略模型,在迄今为止最大的机器人操作数据集 (Open X-Embodiment) 的 800k 条轨迹上进行预训练,能够通过简单的微调高效适应具有新传感器和动作空间的新机器人平台。
关键定义
本文沿用了现有研究中的关键定义,并通过特定的组合与设计加以创新。核心概念包括:
- 通用机器人策略 (Generalist Robot Policies, GRPs): 指那些能够直接将机器人观测数据映射到动作,并在不同任务、环境和机器人系统间展现零样本或少样本泛化能力的底层视觉-运动控制模型。
- Tokenization (令牌化): 将不同模态的输入(如图像、语言、机器人自身状态)转换成统一的、可由 Transformer 处理的离散单元(token)序列的过程。这是模型处理异构输入的关键。
- Readout Tokens: 模型架构中的一种特殊可学习 token。它们在序列中“读取”过去的观测和任务 token 的信息,但不被这些 token 所关注。这使得它们可以作为整个序列信息的紧凑摘要,传递给动作解码头,同时保证了输入输出模块的独立性和可扩展性。
- 动作分块 (Action Chunks): 模型不只预测单个时间步的动作,而是预测未来一小段连续的动作序列。这有助于提高策略的稳定性和远见。
- 扩散解码 (Diffusion Decoding): 一种用于动作生成的概率模型方法。它通过一个去噪过程从高斯噪声中逐步生成精确的、多模态的连续动作分布,相比均方误差 (MSE) 或离散化动作能更好地建模复杂行为。
相关工作
当前机器人学习的主流方法是为特定机器人和任务从零开始训练策略,这需要大量的数据收集工作,且泛化能力有限。近年来,研究界开始探索“通用机器人模型”,旨在通过在多机器人、多任务的大规模数据集上进行预训练,来提升下游任务的泛化能力和学习效率。
然而,现有的通用机器人策略(如 GNM, RoboCat, RT-X)存在一些关键瓶颈:
- 灵活性不足:通常要求下游用户严格遵守预训练时设定的输入配置(如固定的单个摄像头视图),难以适应新的传感器或动作空间。
- 缺乏有效的微调支持:对于适应新领域,没有提供高效的微调方法。
- 模型不开源:最大、最强的模型通常不向公众开放,限制了社区的研究和应用。
本文旨在解决这些问题,通过设计一个更加灵活、可扩展且完全开源的通用机器人策略系统,使其能广泛适用于多样化的机器人应用场景。
本文方法
Octo 的核心设计思想是灵活性和可扩展性。它是一个基于 Transformer 的策略模型,其架构设计使其能够灵活地处理多样的输入输出,并在大规模数据上进行有效训练。

架构设计
Octo 模型由三个主要部分组成:输入 tokenizer、Transformer 主干网络和输出头。
- 输入与 Tokenizer:Octo 使用特定模态的 tokenizer 将所有输入(语言指令 $\ell$、目标图像 $g$、观测序列 $o_{1:H}$)转换为统一的 token 序列。
- 语言输入:通过一个预训练的 T5-base 模型进行编码。
- 图像输入:通过一个轻量级的卷积网络 (CNN) 提取特征,然后切分成图像块 (patches) 并展平,类似于 ViT 的做法。
- 所有 token 会加上可学习的位置编码,然后按时间顺序拼接成 Transformer 的输入序列。
-
Transformer 主干网络:Octo 的主干是一个 Transformer 模型,但其注意力模式经过了特殊设计。它采用分块因果注意力 (block-wise masked attention),即在任一时间步 $t$ 的观测 token 只能关注当前及之前的观测 token ($o_{0:t}$) 和任务相关的 token (如语言指令)。这种模块化设计使得在微调时可以轻松添加或移除某些输入(如增加一个手腕摄像头),而无需改变预训练模型的权重。
- Readout Tokens 与动作头:在输入序列中,模型会插入可学习的 “readout tokens” $\mathcal{T}_{R,t}$。这些 token 只“读取”之前的信息,而不影响其他 token 的计算,功能类似于 BERT 中的 \([CLS]\) token。它们将观测序列信息汇总成一个紧凑的向量,然后送入一个轻量级的扩散解码头 (diffusion decoding head) 中,以预测一个动作序列(action chunk)。这种设计将繁重的计算集中在主干网络,而动作生成则由一个小型高效的模块完成。
创新点
Octo 架构的创新之处在于其极致的模块化和灵活性。与之前将视觉编码器与 MLP 输出头融合的固定架构不同,Octo 的设计允许在微调时:
- 增删输入:可以为新机器人增加新的传感器输入(如新的摄像头、力矩传感器),只需添加一个新的 tokenizer 和位置编码,而 Transformer 主干网络权重可以完全保留。
- 改变输出:可以为新的机器人适配不同的动作空间(如从末端执行器控制改为关节位置控制),只需添加一个新的输出头。
这种设计使得 Octo 成为一个真正意义上的“通用”模型,因为它不必在预训练阶段就覆盖所有可能的机器人配置,而是通过高效微调来适应未来的多样化需求。
训练数据
Octo 在 Open X-Embodiment 数据集的一个精选子集上进行训练。该子集包含来自 25 个不同数据集的约 800k 条机器人演示轨迹。
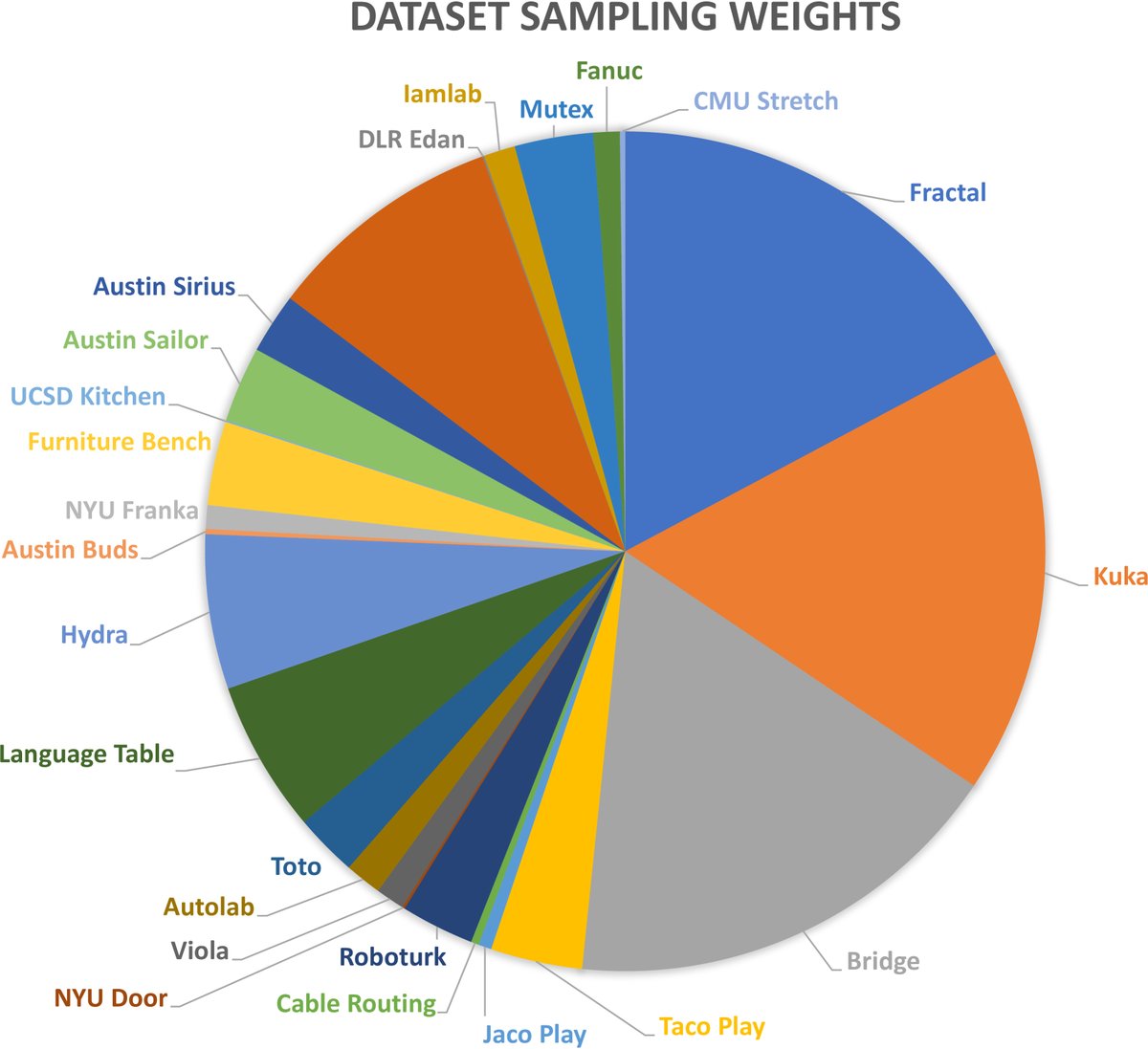
数据筛选标准包括:
- 必须包含图像观测流。
- 使用末端执行器 delta 控制方式。
- 移除了行为过于重复、图像分辨率过低或任务过于小众的数据集。
在训练时,数据根据其多样性进行了加权,以平衡不同数据集的贡献,避免被少数大型但单调的数据集主导。
训练目标
Octo 使用条件扩散解码 (conditional diffusion decoding) 来预测连续且多模态的动作分布。训练过程遵循标准的 DDPM 目标,即向专家动作中添加高斯噪声,并训练一个去噪网络 $\epsilon_{\theta}$ 来恢复原始动作。
\[x^{k-1}=\alpha(x^{k}-\gamma\epsilon_{\theta}(x^{k},e,k)+\mathcal{N}\big{(}0, \sigma^{2}I\big{)}).\]其中 $e$ 是 Transformer readout token 的输出嵌入。这种方法的好处是,Transformer 主干网络每个预测步只需前向传播一次,后续的多步去噪过程完全在小型的扩散头内部完成,计算效率高。在微调时也采用相同的训练目标,并更新整个模型参数。
开源资源
本文发布了训练、微调和运行 Octo 模型所需的全部资源,包括:
- Octo-Small (27M) 和 Octo-Base (93M) 两个尺寸的预训练模型。
- 完整的 JAX 预训练和微调代码。
- 兼容 JAX 和 PyTorch 的 Open X-Embodiment 数据加载器。
实验结论
实验在 4 个机构的 9 个真实机器人平台上进行,旨在验证 Octo 在零样本控制、数据高效微调以及关键设计选择上的有效性。

零样本控制能力
在无需额外训练的情况下,Octo 能够直接控制多种在预训练数据中出现过的机器人。
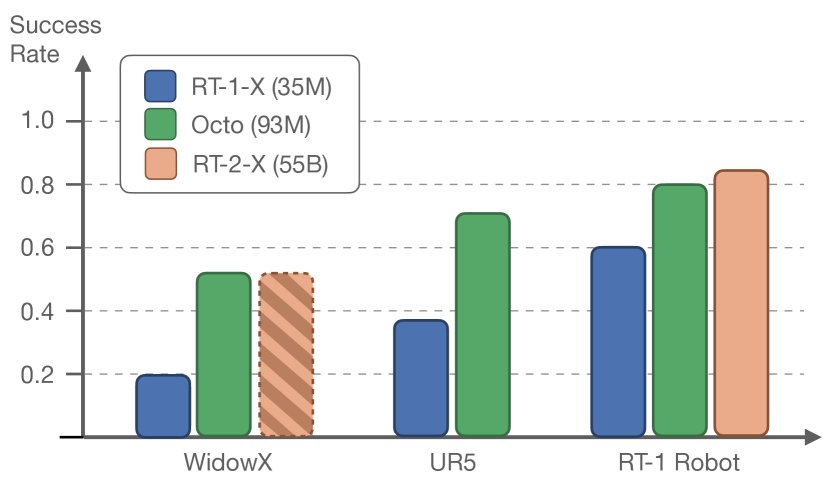
- 性能优越:在语言指令任务上,Octo 的平均成功率比当前最好的开源通用策略 RT-1-X 高出 29%。
- 媲美更大模型:在部分任务上,Octo 的表现与参数量为其数百倍的 RT-2-X (55B) 相当。
- 多模态指令:与只能使用语言指令的 RT-1-X/RT-2-X 不同,Octo 还支持目标图像指令,并且在实验中表现出比语言指令更高的成功率 (高出 25%),因为目标图像提供了更丰富的任务信息。
数据高效的微调能力
Octo 作为预训练权重,能够极大地提升在新领域的学习效率。实验在 6 个新任务上进行,每个任务仅使用约 100 条演示数据,在单个消费级 GPU 上微调不到 5 小时。
| 伯克利插入* | 斯坦福咖啡 | CMU 烘焙 | 伯克利拾取† | 伯克利可乐 | 伯克利双臂† | 平均 | |
|---|---|---|---|---|---|---|---|
| ResNet+Transformer 从零训练 | 10% | 45% | 25% | 0% | 20% | 20% | 20% |
| VC-1 [57] | 5% | 0% | 30% | 0% | 10% | 50% | 15% |
| Octo (本文) | 70% | 75% | 50% | 60% | 100% | 80% | 72% |
表1:微调评估。*:新观测输入(力-扭矩)。†:新动作空间(关节位置控制)。
- 显著超越基线:微调后的 Octo 平均成功率达到 72%,远超从零开始训练 (20%) 或使用预训练视觉表征 (VC-1, 15%) 的方法。
- 适应新输入输出:实验证明,Octo 能够成功微调到包含新观测(力-力矩传感器)和新动作空间(关节位置控制)的机器人上,展示了其架构的灵活性。
关键设计决策分析
通过消融实验,本文探究了哪些设计对通用机器人策略的性能至关重要。
| 综合性能 | ||
|---|---|---|
| Octo-Small (本文) | 83% | |
| 数据 | RT-X 数据集混合 [67] | 60% |
| 单一机器人数据集 (Bridge) | 43% | |
| 策略 | 离散化动作预测 [67] | 18% |
| 连续动作预测 (MSE) | 35% | |
| 架构 | Resnet-50 + Transformer [67] | 70% |
表2:模型消融实验。
- 架构:“Transformer-first” 架构(类似 ViT)在大规模多样化数据上的表现优于传统的“ResNet+小 Transformer”架构。
- 数据:使用更广泛、更多样的数据集混合进行预训练,性能显著提升。数据集的多样性至关重要。
- 训练目标:扩散解码头的表现远优于均方误差损失 (MSE) 和离散化动作的交叉熵损失,因为它既能建模多模态动作分布,又能保持连续动作的精度。
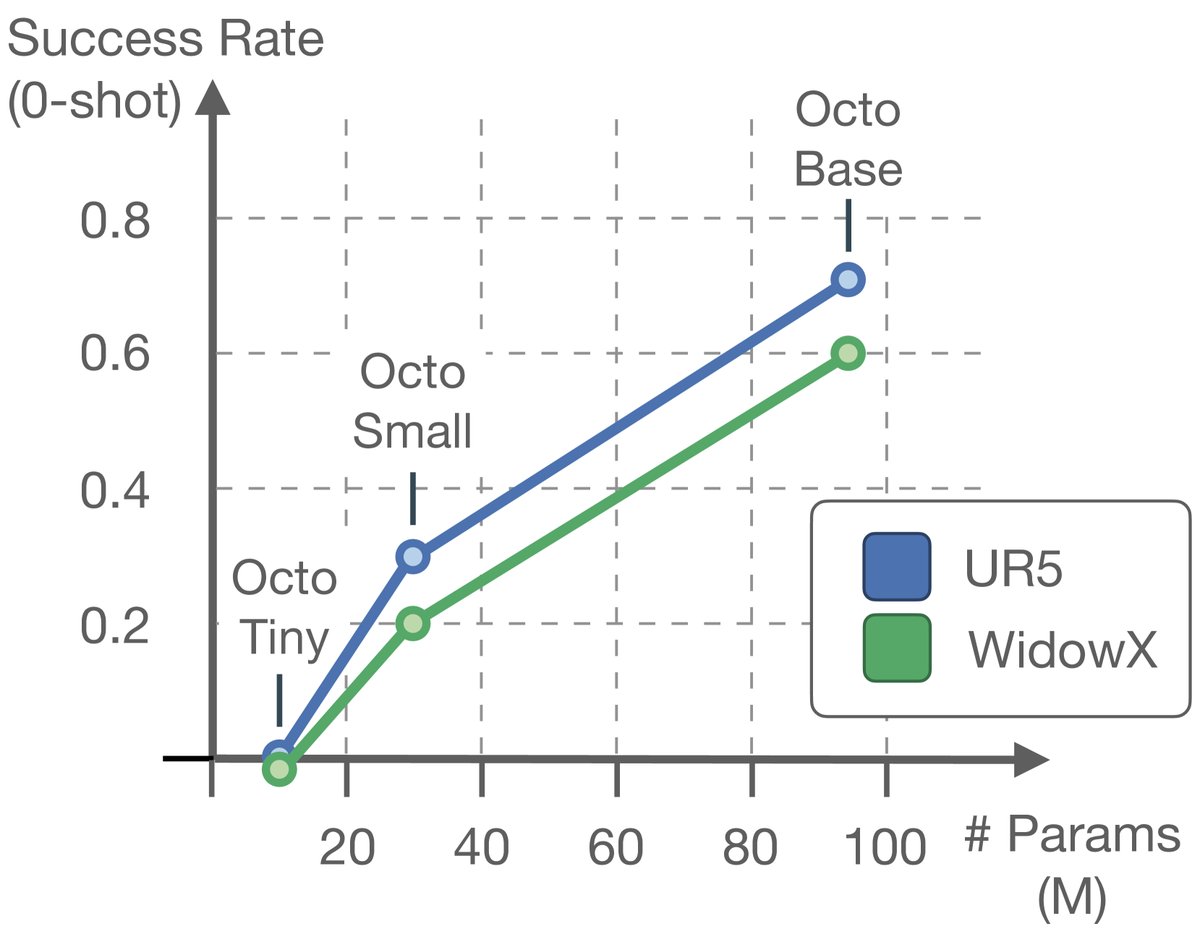
- 模型规模:模型性能随参数规模的增大而提升。更大的模型(Octo-Base)在场景感知和鲁棒性上优于小模型。
总结
Octo 作为一个开源、灵活且可扩展的通用机器人策略,在零样本控制和数据高效微调方面均取得了强大的性能。实验证明,其“Transformer-first”架构、扩散动作解码头以及在超大规模多样化数据集上的预训练是其成功的关键。尽管模型在处理手腕摄像头和语言指令方面仍有提升空间(主要归因于训练数据中相应模态的稀疏性),但 Octo 为机器人学界提供了一个强大的基础模型和研究平台。