OnePiece: Bringing Context Engineering and Reasoning to Industrial Cascade Ranking System
-
ArXiv URL: http://arxiv.org/abs/2509.18091v1
-
作者: See-Kiong Ng; Sunhao Dai; Yu Zhao; Kangle Wu; Xu Chen; Jiahua Wu; Kun Wang; Yuxuan Zhu; Jiakai Tang; Anxiang Zeng; 等14人
-
发布机构: National University of Singapore; Renmin University of China; Shopee; University of Science and Technology of China
TL;DR
本文提出了 OnePiece,一个统一的框架,它将大型语言模型(LLM)风格的上下文工程和多步推理机制成功地集成到工业级级联排序系统的召回和排序阶段,并取得了显著的离线和在线效果提升。
关键定义
- 结构化上下文工程 (Structured Context Engineering): 一种输入构建方法,它不仅仅使用原始的用户交互序列,还通过融合偏好锚点和情景描述符来丰富上下文,最终将这些异构信号统一成一个结构化的 token 输入序列。
- 块级潜在推理 (Block-wise Latent Reasoning): 一种多步推理机制,模型通过多个推理块(block)逐步优化其内部的隐状态表示。与传递单个隐状态相比,该方法通过调整块的大小来扩展推理带宽,从而在信息压缩与保留之间取得更好的平衡。
- 渐进式多任务训练 (Progressive Multi-task Training): 一种监督学习策略,它利用用户行为反馈链(如曝光 → 点击 → 加购 → 下单)作为分阶段的监督信号。每个推理步骤(块)都由一个特定复杂度的任务来指导,从而为多步推理过程提供了显式的过程化监督。
- 偏好锚点 (Preference Anchors): 根据领域知识构建的辅助物品序列(例如,在当前查询下点击次数最多的物品),用作高质量的参考点,为模型提供超越原始交互历史的、与特定情景相关的用户意图信号。
- 分组集合式排序 (Grouped Setwise Ranking): 在排序阶段采用的一种策略,将候选集随机划分为小分组(例如,每组12个),并在组内进行集合式(setwise)打分。该策略在计算效率和模型表达能力(捕捉候选物之间的交叉互动)之间取得了很好的平衡。
相关工作
当前的工业级排序系统(如搜索和推荐系统)大多致力于将 Transformer 架构移植到现有模型中。然而,尽管这些努力带来了一些效果,但相比于已经很强大的深度学习推荐模型 (Deep Learning Recommendation Models, DLRMs),其提升往往是增量式的,因为注意力等核心机制早已被深度集成。
LLM 的突破不仅仅来自其架构,更得益于两个关键机制:一是上下文工程 (context engineering),通过丰富原始查询来激发模型能力;二是多步推理 (multi-step reasoning),通过中间步骤迭代式地优化预测。然而,这两个机制在排序系统领域尚未得到充分探索。直接移植它们面临两大挑战:
- 上下文贫乏: 推荐系统的用户交互序列缺乏 LLM prompt 那样的结构化和丰富性,现有的特征工程也主要为 DLRM 设计,不清楚如何构建上下文来支持推理。
- 缺乏监督: LLM 可以利用大规模的思维链 (chain-of-thought) 数据进行监督,而排序系统中缺乏此类显式监督,领域专家也难以描述用户行为背后的潜在决策路径。
本文旨在解决上述问题,探索如何将上下文工程和多步推理有效引入工业级级联排序系统,以实现性能的突破。
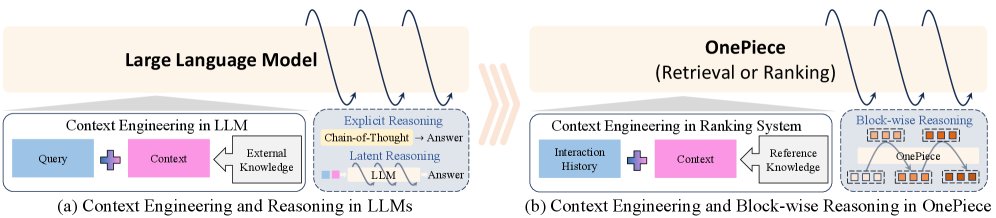
本文方法
本文提出了 OnePiece,一个统一的框架,将 LLM 风格的上下文工程和推理机制引入工业级级联排序系统。
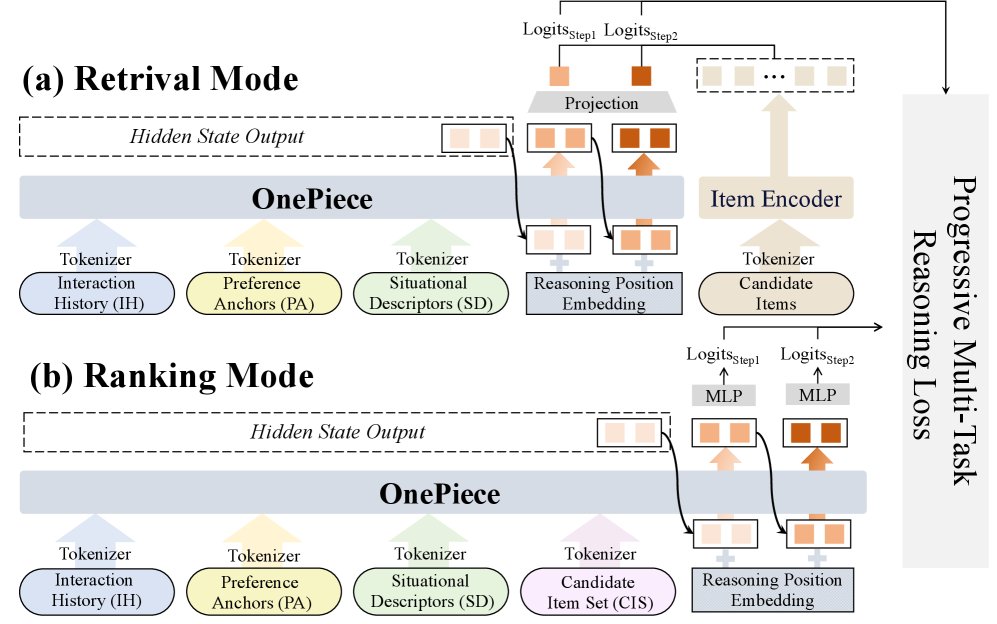
概述
OnePiece 框架的核心由三部分构成:
- 结构化上下文工程:一种灵活的 LLM 风格输入构建方法,将异构信号(用户历史、偏好锚点、情景描述符、候选物品)编码为统一的 token 序列。
- 块级潜在推理:在纯 Transformer 主干网络的基础上,增加潜在推理块,通过迭代式地优化中间表示,逐步建模用户偏好。
- 渐进式多任务训练:一种分阶段的优化策略,利用多层次的用户反馈(如点击、购买)来监督不同的推理块,从而实现由浅入深的偏好学习。
创新点1:结构化上下文工程
本文将所有输入都转换为统一的 token 序列,以便被 Transformer 模型处理。该序列由四种互补的 token 类型构成:
- 交互历史 (Interaction History, IH): 按时间顺序编码的用户历史交互物品,捕捉用户的动态偏好。
- 偏好锚点 (Preference Anchors, PA): 基于专家知识构建的辅助物品序列,提供与当前情景相关的意图线索。
- 情景描述符 (Situational Descriptors, SD): 用户的静态特征和查询信息,为当前排序任务提供必要的上下文。
- 候选物品集 (Candidate Item Set, CIS): 待排序的候选物品特征,仅在排序阶段使用,以实现候选物之间的交叉比较。
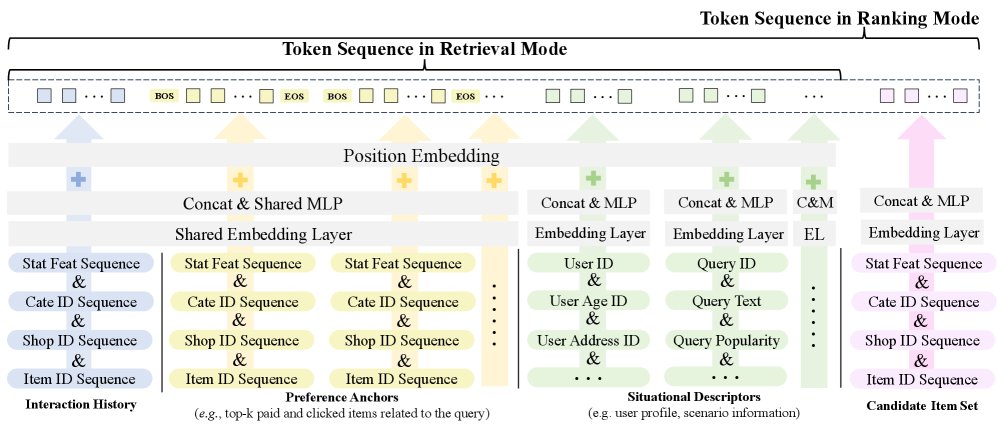
所有原始特征(用户、物品、查询)首先通过各自的嵌入函数 \($\phi(\cdot)\)$ 映射为嵌入向量,再通过特定的 MLP 投射层 \($\text{Proj}(\cdot)\)$ 统一到 \(d\) 维隐空间。
-
召回阶段输入: 最终的输入 token 序列由 IH、PA 和 SD 三部分拼接而成:
\[\mathcal{I}^{u}_{\mathrm{retrieval}}=\underbrace{(\mathbf{h}^{\mathrm{IH}}_{1},\ldots,\mathbf{h}^{\mathrm{IH}}_{n_{u}})}_{\text{chronological IH}}\ \oplus\ \underbrace{\bigoplus_{b=1}^{B}\big(\mathbf{e}_{\mathrm{BOS}},\ \mathbf{h}^{\mathrm{PA}}_{b,1},\ldots,\ \mathbf{h}^{\mathrm{PA}}_{b,m_{b}},\ \mathbf{e}_{\mathrm{EOS}}\big)}_{\text{PA groups ordered by business rule}}\ \oplus\ \underbrace{(\mathbf{h}^{\mathrm{U}},\ \mathbf{h}^{\mathrm{Q}},\ \ldots)}_{\text{SD segment}}.\]其中,IH token 带有位置编码,PA 组由特殊边界 token 包裹,SD token 则放在末尾。
-
排序阶段输入: 排序阶段的目标是在一个小候选集内进行精细比较。为了平衡 pointwise 方法(无法交叉比较)和全量 setwise 方法(计算成本过高)的优劣,本文采用了一种分组集合式排序 (grouped setwise ranking) 策略:将候选集随机分成大小为 \(C\) 的小组,在组内进行 setwise 推理。这使得模型既能学习候选物间的交互,又将计算成本控制在可接受范围内。
排序阶段的输入序列在召回序列的基础上,追加了候选物品集 (CIS) token。为了避免模型学到位置与排序标签间的虚假关联,CIS token 不带位置编码。
\[\mathcal{I}^{u}_{\mathrm{rank}}=\mathcal{I}^{u}_{\mathrm{retrieval}}\ \oplus\ \underbrace{(\mathbf{h}^{\mathrm{CIS}}_{1},\ldots,\mathbf{h}^{\mathrm{CIS}}_{C})}_{\text{no positional embedding}}.\]
创新点2:块级潜在推理
本文采用了一个 \(L\) 层的双向 Transformer 作为主干网络。在其之上,设计了块级多步推理机制。
与以往只传递单个隐状态的推理方法不同,该机制每次迭代传递并优化一个隐状态块 (block of hidden states)。这种设计的动机是,单个隐状态的传输带宽有限,可能过度压缩信息;而块级推理的“带宽”可调(通过块大小 \(M\)),能更好地平衡信息压缩与保留。
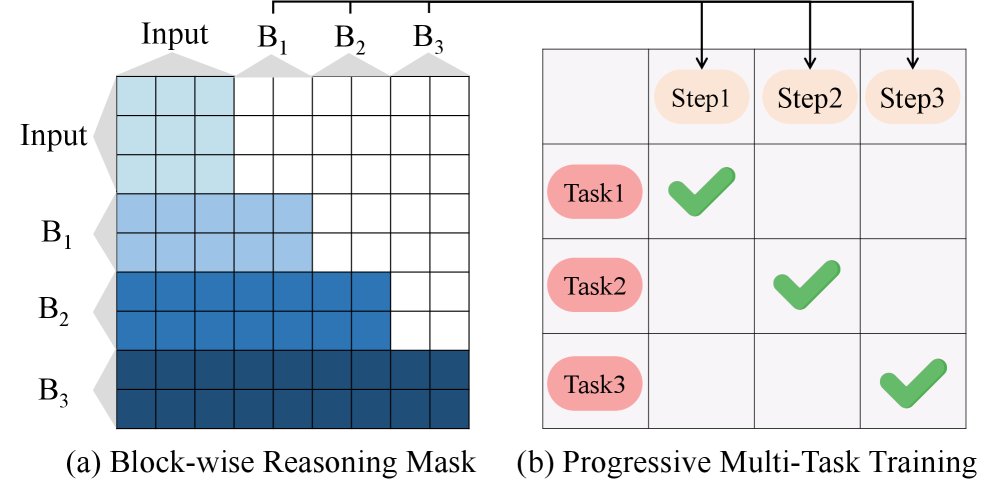
具体流程如下:
- 初始化: 第一个推理块 \($\mathbf{B}\_{0}\)$ 直接从 Transformer 最后一层的输出 \($\mathbf{H}^{L}\)$ 中提取。
- 迭代推理: 在第 \(k\) 步,将前 \(k-1\) 步优化后的推理块 \($\tilde{\mathbf{B}}\_{<k}\)$ 和当前块 \($\tilde{\mathbf{B}}\_{k}\)$ 拼接到原始输入序列 \($\mathcal{I}\)$ 之后,再次送入 Transformer 进行编码。为了区分不同步骤,引入了可学习的推理位置编码 (Reasoning Position Embeddings, RPE)。
- 信息流控制: 使用块级因果掩码 (causal block-wise mask),确保当前推理块 \($\tilde{\mathbf{B}}\_{k}\)$ 可以关注所有基础 token 和历史推理块,但不能关注未来的推理块。
- 任务适配:
- 召回模式: 块大小 \(M\) 设为情景描述符 (SD) 的长度。推理过程聚焦于强化用户和查询表示,以平衡个性化与相关性。
- 排序模式: 块大小 \(M\) 设为候选集分组大小 \(C\)。推理过程聚焦于对组内所有候选物进行比较和区分。
创新点3:渐进式多任务训练
为了有效监督多步推理过程,本文引入了渐进式多任务训练范式,它本质上是一种课程学习。
将学习目标 \($\mathcal{T}\)$ 按照从易到难的顺序排列(例如,点击 → 加购 → 下单),并将第 \(k\) 个推理步骤与第 \(k\) 个任务 \($\tau\_k\)$ 绑定。这样,模型首先学习预测点击等浅层行为,然后在此基础上学习预测购买等深层偏好。
- 召回模式训练: 在第 \(k\) 步,从推理块 \($\mathbf{B}\_k\)$ 中提取用户表示 \($\mathbf{r}\_k\)$。损失函数结合了两种目标:
- 二元交叉熵损失 (BCE Loss): 点对点的概率校准。
- 双向对比学习损失 (Bidirectional Contrastive Learning, BCL): 批次内的全局对比。它包含两个对称部分:\(U2I\)(用户从所有物品中识别正样本)和 \(I2U\)(正样本物品从所有用户中识别对应用户)。 总损失为:\($\mathcal{L}^{\mathrm{retrieval}}=\sum\_{k=1}^{K}\big(\mathcal{L}^{\mathrm{BCE}}\_{k}+\mathcal{L}^{\mathrm{BCL}}\_{k}\big)\)$
- 排序模式训练: 在第 \(k\) 步,从推理块 \($\mathbf{B}\_k\)$ 中提取 \(C\) 个候选物的隐状态 \($\mathbf{h}\_{i,k}\)$,并通过特定于任务的 MLP 计算得分 \($s\_{i,k}\)$。损失函数同样结合了两种目标:
- 二元交叉熵损失 (BCE Loss): 点对点的概率校准。
- 集合式对比学习损失 (Setwise Contrastive Learning, SCL): 在候选组内,让正样本的得分高于所有其他负样本。 总损失为:\($\mathcal{L}^{\mathrm{ranking}}=\sum\_{k=1}^{K}\left(\mathcal{L}^{\mathrm{BCE}}\_{k}+\mathcal{L}^{\mathrm{SCL}}\_{k}\right)\)$
实验结论
本文基于 Shopee 平台 30 天的真实日志数据进行了广泛的离线实验和在线 A/B 测试。
整体性能
如下表所示,OnePiece 在召回和排序任务上均显著优于所有基线模型,包括优化良好的生产 DLRM、HSTU 和 ReaRec。与最强的基线 ReaRec+PA 相比,OnePiece 在召回任务上将 R@100 从 0.485 提升至 0.517,在排序任务上将 C-AUC 从 0.862 提升至 0.911。这证明了其块级潜在推理和渐进式多任务训练的有效性。
| 模型 | R@100 | R@500 | C-AUC | C-GAUC | A-AUC | A-GAUC | O-AUC | O-GAUC |
|---|---|---|---|---|---|---|---|---|
| DLRM (生产基线) | 0.468 | 0.635 | 0.857 | 0.825 | 0.869 | 0.840 | 0.884 | 0.864 |
| HSTU | 0.443 | 0.618 | 0.841 | 0.814 | 0.852 | 0.824 | 0.871 | 0.848 |
| HSTU+PA | 0.459 | 0.627 | 0.856 | 0.824 | 0.869 | 0.838 | 0.883 | 0.860 |
| ReaRec | 0.460 | 0.630 | 0.853 | 0.821 | 0.858 | 0.828 | 0.873 | 0.849 |
| ReaRec+PA | 0.485 | 0.648 | 0.862 | 0.830 | 0.871 | 0.841 | 0.886 | 0.867 |
| OnePiece (本文) | 0.517 | 0.671 | 0.911 | 0.881 | 0.916 | 0.890 | 0.925 | 0.903 |
优点
- 上下文工程的有效性: 消融实验(下表)证实了结构化上下文工程的巨大价值。逐步加入交互历史(IH)、偏好锚点(PA)和情景描述符(SD)后,模型性能持续提升。特别是 PA,它提供了查询相关的上下文,显著增强了模型捕捉用户细粒度意图的能力。
| 版本 | 输入组成 | R@100 | R@500 | C-AUC | C-GAUC |
|---|---|---|---|---|---|
| V1 | IH (仅ID) | 0.432 | 0.612 | 0.821 | 0.793 |
| V2 | V1 + 物品侧信息 | 0.470 | 0.641 | 0.860 | 0.829 |
| V3 | V2 + PA (长度10) | 0.486 | 0.651 | 0.873 | 0.841 |
| … | … | … | … | … | … |
| V7 | V2 + PA (长度90) | 0.504 | 0.663 | 0.881 | 0.857 |
| V8 | V7 + SD | 0.517 | 0.671 | 0.911 | 0.881 |
- 训练策略的优越性: 消融实验证明,双向注意力、候选者之间的可见性(用于排序),以及本文提出的块级推理和渐进式多任务训练,都对最终性能有显著贡献。例如,在排序任务中,仅开启候选者组内互见的设置,就使 C-AUC 从 0.860 大幅提升至 0.881。
- 出色的数据效率和扩展性: 实验表明,OnePiece 不仅样本效率更高(使用更少天数的日志就能超越基线),而且随着训练数据的增加,其性能能够持续提升,而 DLRM 等模型则很快达到瓶颈。
- 在线业务价值显著: OnePiece 已成功部署到 Shopee 的主要个性化搜索场景。在线 A/B 测试显示,它带来了持续的业务增长,包括总计超过 \(+2%\) 的 GMV/UU(人均成交总额)和 \(+2.90%\) 的广告收入增长。
总结
本文成功地将 LLM 的两大核心优势——上下文工程和多步推理,创新性地适配并应用到工业级级联排序系统中。通过提出的 OnePiece 框架,模型能够更深刻地理解用户意图并进行复杂的偏好推理。大量的离线和在线实验不仅验证了每个设计模块的有效性,也证明了该框架在真实、大规模商业环境中的巨大实用价值和潜力。