Open Data Synthesis For Deep Research
-
ArXiv URL: http://arxiv.org/abs/2509.00375v1
-
作者: Hongjin Qian; Ziyi Xia; Zheng Liu; Kun Luo
-
发布机构: BAAI
TL;DR
本文提出了一个名为 InfoSeek 的可扩展数据合成框架,它将复杂的“深度研究”任务形式化为分层约束满足问题(HCSP),并自动生成高质量的训练数据,使一个3B参数量的小模型在复杂的深度研究任务上,性能超越了32B的大模型及部分商业API。
关键定义
本文提出或沿用了以下几个核心概念,对理解其贡献至关重要:
- 深度研究 (Deep Research):指超越简单事实查询的复杂任务,要求智能体能够将复杂问题分解为子问题、协调多步推理,并从多样化的信息源中综合证据。
- 分层约束满足问题 (Hierarchical Constraint Satisfaction Problem, HCSP):本文提出的对具有可验证答案的深度研究任务的形式化定义。与平面的约束满足问题(CSP)或线性的多跳问题(MHP)不同,HCSP包含一个相互依赖的约束层级结构,必须通过逐层解决子问题才能得到最终答案。
- 研究树 (Research Tree):用于构建 HCSP 的底层数据结构。树中的每个顶点(vertex)代表一个知识实体或事实,边(edge)代表它们之间的逻辑关系。该树的层级结构直接映射到 HCSP 的推理层级。
- InfoSeek: 本文提出的一个创新的、可扩展的数据合成框架。它使用一个双智能体系统,从大规模网页中自动、递归地构建研究树,并将其转化为自然语言问题,旨在解决高质量深度研究训练数据的稀缺问题。
相关工作
目前,大型语言模型(LLM)在处理简单问答上表现出色,但面对需要分解问题、多步推理和整合多源信息的“深度研究”任务时仍显不足。已有的研究现状和瓶颈主要体现在:
- 基准数据集过于简单:像 Natural Questions (NQ) 和 HotpotQA 这样的经典数据集,主要考察单跳或多跳(multi-hop)的问答,其结构复杂度远低于真实的深度研究场景。
- 现有合成数据质量不高:尽管近期有一些工作尝试合成更复杂的数据,但它们往往存在推理捷径(shortcut reasoning)、知识泄露或结构深度不足等问题。
- 缺乏开源的高质量数据集与框架:许多针对复杂问答的研究工作,其数据集和数据生成流程并未公开,这限制了社区在该方向上的发展。如下表所示,开源领域缺少专为深度研究设计的大规模、高质量数据集。
本文旨在解决的核心问题是:如何为“深度研究”任务自动、可扩展地生成结构复杂、质量可控且无推理捷径的高质量训练数据,以推动语言智能体在该领域能力的提升。
| 名称 | 问题类型 | 数据来源 | 问答对数量 | 轨迹数据 | 框架开源 |
|---|---|---|---|---|---|
| NQ | 单跳 | Wiki | 300k+ | – | – |
| HotpotQA | 多跳 | Wiki | 100k+ | – | – |
| WebWalkerQA | 多跳 | Web | 14.3k | – | – |
| InForage | 多跳 | Web | – | – | – |
| SimpleDeepSearcher | 多跳 | – | – | 871 | Open |
| Pangu DeepDiver | 多跳 | Web | – | – | – |
| WebDancer | 多跳 | Wiki&Web | 200 | 200 | – |
| WebShaper | 复杂 | Wiki | 500 | – | – |
| InfoSeek | HCSP | Wiki&Web | 50k+ | 16.5k | Open |
本文方法
概述
为了解决深度研究数据稀缺的问题,本文提出了一个两阶段的解决方案:
- InfoSeek 数据合成框架:一个自动化的流程,用于生成符合 HCSP 定义的复杂问答数据。
- InfoSeeker 智能体:一个基于 InfoSeek 数据集训练的深度研究智能体,其工作流和训练方法都经过精心设计。
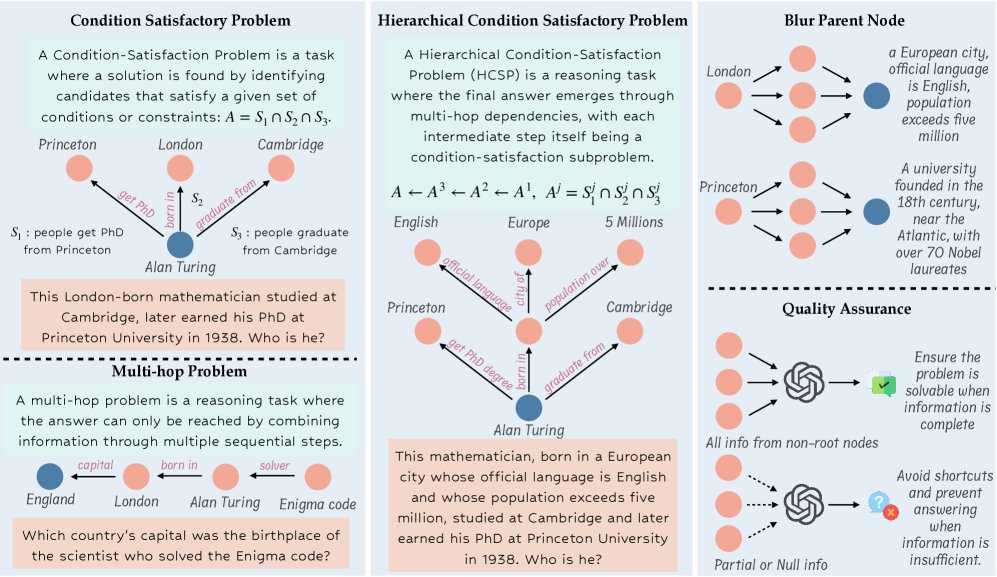
InfoSeek:可扩展的数据合成框架
InfoSeek 的核心是通过一个双智能体(规划器 Planner 和浏览器 Browser)系统,基于维基百科和网页内容,以程序化的方式构建“研究树”,并将其转换为高质量的问答对。
研究树的构建过程
该过程由四个核心动作(Action)组成,由规划器和浏览器协同完成:
- 动作1:初始化 (Initialization):从知识库(如维基百科)中随机选择一个实体作为最终答案,创建研究树的根节点(root)。
- 动作2:用约束模糊化父节点 (Blurring Parent with Constraints):为了增加问题的“并行”复杂度,该动作为树中的某个节点 \(v\) 添加多个约束(即子节点),这些约束共同指向 \(v\)。此举可确保仅靠单个约束无法轻易确定 \(v\),必须综合所有信息,形成一个局部的 CSP。
- 动作3:扩展树的深度 (Extending the Tree):为了增加问题的“串行”复杂度(即推理深度),该动作通过提取实体页面上的超链接来创建一个新的子节点,从而延长推理链条。
- 动作4:终止与问题生成 (Termination and Generation):当研究树达到预设的复杂度(如节点数)后,系统会终止构建过程,并调用一个强大的 LLM(如 GPT-4.1)将这个结构化的树转化为一个自然的、需要完整多步推理才能解答的语言问题。
数据质量保证
为了确保生成数据的质量,InfoSeek 采用了一套严格的双重验证流程:
- 难度验证 (Difficulty):用一个强大的闭源模型(Qwen2.5-32B-Inst)直接回答生成的问题。如果模型能够轻易答对(仅有2%),则将该样本剔除,以保证问题的挑战性。
- 可验证性 (Verifiability):将生成的问题、真实的证据网页以及一些干扰网页一同提供给 Gemini 2.5 Flash API。如果该 API 无法利用给定的真实信息得出唯一正确答案,则表明该问题存在歧义或无法求解,同样会被剔除。
这一流程有效地避免了问题“欠定”(答案不唯一)或“过定”(答案太简单)的情况。
数据集统计
最终生成的 InfoSeek 数据集包含超过5万个样本。数据显示,即便是强大的 Qwen2.5-72B 模型,在采用思维链(CoT)提示的情况下,面对该数据集的整体失败率也高达91.6%,且失败率与问题的复杂度(顶点数)正相关,证明了该数据集的高挑战性和复杂度可控性。
| # 顶点数 | 数量 | 失败率 (%) | 成本 ($) | 问题长度 (tok) | 答案长度 (tok) |
|---|---|---|---|---|---|
| 3 | 3,841 | 88.1 | 43.9 | 31.97 | 6.17 |
| 4 | 15,263 | 91.7 | 142.8 | 43.38 | 5.91 |
| 5 | 15,051 | 91.0 | 160.4 | 54.35 | 5.75 |
| 6 | 17,714 | 92.6 | 214.4 | 65.52 | 5.64 |
| ≥7 | 269 | 94.1 | 10.3 | 81.59 | 5.23 |
| 总计 | 52,138 | 91.6 | 571.8 | 53.43 | 5.79 |
InfoSeeker:深度研究智能体
InfoSeeker 是一个基于 InfoSeek 数据集训练的、用于执行深度研究任务的智能体框架。
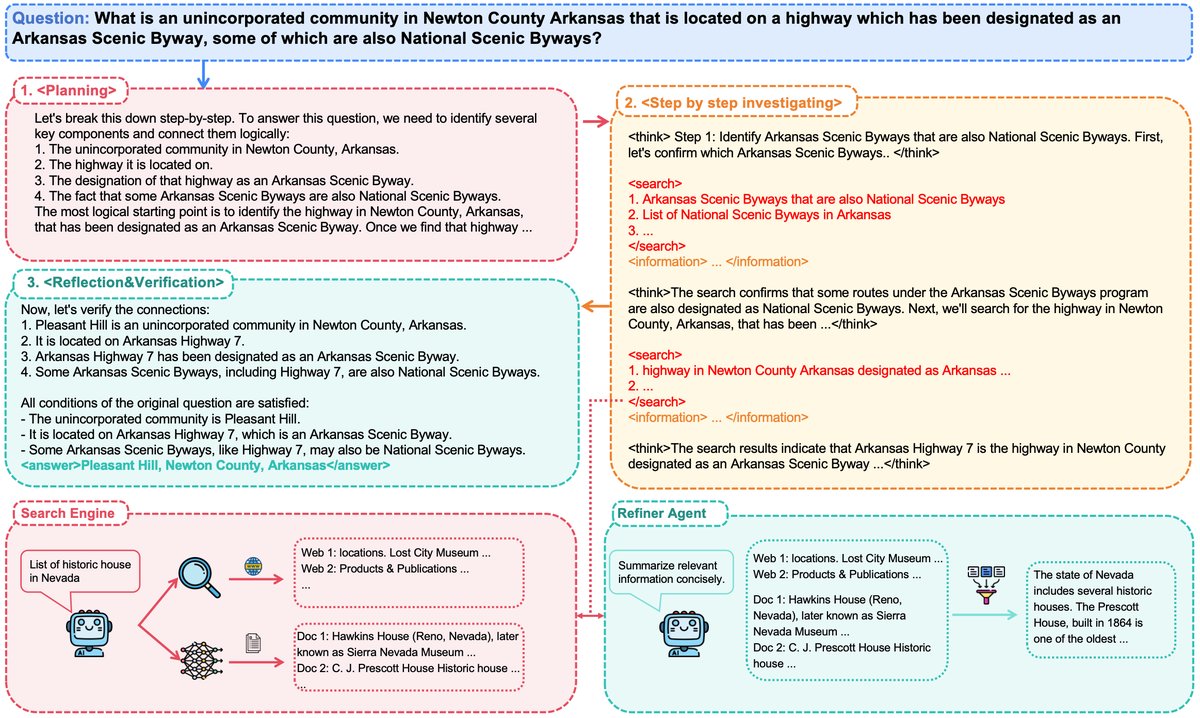
工作流程创新
InfoSeeker 的工作流程设计巧妙,旨在解决传统智能体在信息检索中面临的“上下文爆炸”和信息冗余问题:
- 行动前思考 (Think Before Action):在每一步行动前,模型会先在 \(<think>\) 标签内进行规划,明确已知信息和下一步需要检索的内容。
- 并行多查询搜索 (Parallelized Multi-Query Search):在一个推理步骤中,智能体可以生成多个不同的搜索查询,并行执行。这比单查询方法更高效,覆盖面更广。
- 精炼智能体 (Refiner Agent):这是本文方法的一大创新。引入一个专门的、轻量级的“精炼智能体”(本文使用 Qwen2.5-7B-Inst),对每次多查询返回的大量搜索结果进行压缩和总结,提取核心证据。这既保证了高信息召回率,又保持了主智能体工作上下文的简洁和高效。
两阶段训练方法
- SFT 阶段:拒绝采样 (Rejection Sampling):为了得到高质量的训练轨迹,本文首先使用一个强大的教师模型(teacher model)生成大量解题轨迹。然后,通过“拒绝采样”的方法,只保留那些最终答案正确且推理过程无误(如没有走捷径)的“黄金”轨迹,用于监督微调(SFT)。这为模型提供了一个非常好的初始能力。
- RL 阶段:强化学习:在 SFT 的基础上,本文使用 GRPO(一种策略梯度算法)进行强化学习。奖励函数设计得非常直接:只有当模型输出的格式正确且最终答案也正确时,才给予奖励1,否则为0。这个阶段进一步强化了模型在复杂推理和精确搜索方面的能力。
实验结论

核心实验结果
- 强大的泛化智能体搜索能力:在 NQ、HotpotQA 等多个传统的单跳和多跳问答基准上,InfoSeeker-3B 全面超越了包括 RAG 和其他高级智能体搜索方法在内的所有基线模型。这表明 InfoSeek 数据集赋予了模型很强的通用推理能力。
| 模型 | 单跳QA平均 | 多跳QA平均 | 总平均 | | :— | :— | :— | :— | | RAG-based Models | | | | | AutoRefine-3B | 49.3 | 32.2 | 39.6 | | InForage-3B | 49.0 | 34.2 | 40.6 | | InfoSeeker | | | | | InfoSeeker-3B | 49.3 | 39.0 | 43.5 | 注:为简洁起见,此处仅展示平均分和部分强基线。
- 卓越的深度研究能力:在为深度研究设计的、极具挑战性的 BrowseComp-Plus 基准上,InfoSeeker-3B (16.5% 准确率) 的表现令人瞩目。它不仅远超参数量是其10倍的 Qwen3-32B (3.5%),还超越了多个轻量级商业 API(如 Gemini 2.5 Flash),并达到了与更强的 Gemini 2.5 Pro (19.0%) 相近的水平。这证明了 InfoSeek 框架在将深度研究能力“压缩”到小模型上的高效性。
| 模型 | 检索器 | 准确率 (%) | 搜索调用次数 |
|---|---|---|---|
| Gemini 2.5 Flash | BM25 | 15.5 | 10.56 |
| Gemini 2.5 Pro | BM25 | 19.0 | 7.44 |
| Qwen3-32B | BM25 | 3.5 | 0.92 |
| InfoSeeker-3B | BM25 | 16.5 | 8.24 |
- InfoSeek 数据集的有效性验证:实验直接对比了使用 InfoSeek 和传统 NQ+HQA 数据集进行训练的效果。结果显示,在 BrowseComp-Plus 任务上,使用 InfoSeek 训练的模型准确率达到了 16.5%,而使用 NQ+HQA 训练的模型仅为 3.0%。这强有力地证明了 InfoSeek 数据集对于培养深度研究能力的优越性。
总结
本文通过将深度研究任务形式化为 HCSP,并提出 InfoSeek 这一创新的数据合成框架,成功解决了高质量复杂问答数据稀缺的核心痛点。实验证明,基于 InfoSeek 数据集训练的 InfoSeeker 智能体,即使是小参数模型也能在复杂的深度研究任务上取得与顶尖大模型和商业API相媲美的性能。这项工作不仅为社区提供了一个强大、开源的数据合成工具和高质量数据集,也为未来设计更复杂的奖励机制和轨迹级优化策略开辟了新的可能性。