OpenAssistant Conversations – Democratizing Large Language Model Alignment
-
ArXiv URL: http://arxiv.org/abs/2304.07327v2
-
作者: Christoph Schuhmann; Abdullah Barhoum; Sotiris Anagnostidis; Huu Nguyen; A. Mattick; K. Stevens; Yannic Kilcher; David Glushkov; Dimitri von Rutte; Nguyen Minh Duc; 等8人
TL;DR
本文发布了一个通过全球众包构建的大规模、多语言、人工标注的对话数据集——OpenAssistant Conversations,旨在通过开放高质量的人类反馈数据,推进大型语言模型对齐技术的研究民主化。
关键定义
本文提出或使用的核心概念包括:
-
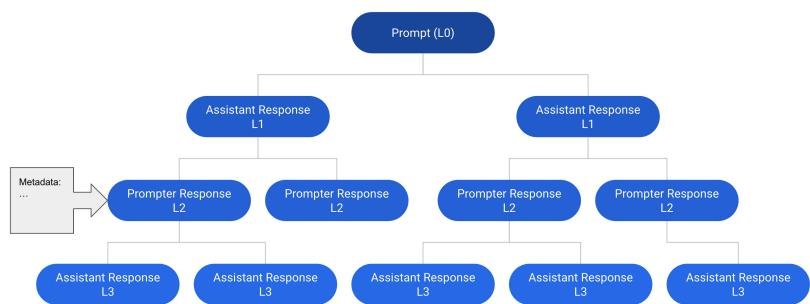
对话树 (Conversation Tree, CT):一种核心数据结构,用于表示对话。树的根节点是初始提示(prompt),每个节点代表对话中的一条消息。一个节点可以有多个子节点,代表对该消息的不同回复,从而形成对话的分支。从根节点到任意节点的路径构成一个完整的对话线程。
-
对话角色 (Prompter & Assistant):为避免混淆,本文定义了对话中的两个角色。\(prompter\) 负责发起对话和提出后续问题/指令,而 \(assistant\) 负责提供回复。这两个角色原则上可以由人类用户或机器扮演。
-
消息树状态机 (Message Tree State Machine):一个管理对话树在数据收集中进展的系统方法。对话树会经历不同状态,如“初始提示审查”、“生长中”、“已完成”或“因低质量而中止”,以确保数据收集流程的系统性和质量控制。
相关工作
当前,最先进的大型语言模型(LLM)对齐技术,如监督微调(SFT)和基于人类反馈的强化学习(RLHF),严重依赖高质量的人类反馈数据。然而,这类数据的创建成本高昂,且通常为少数大型研究机构所私有,并不公开。
虽然存在一些开放获取的指令数据集,但它们大多是利用语言模型自动生成的合成数据,在复杂性、创造性和质量上受到限制。这导致对齐研究的进展被少数能承担大规模数据收集的机构所垄断,阻碍了该领域的包容性和多样化发展。
本文旨在解决这一关键问题:缺乏一个大规模、高质量、多语言且完全开放的人类生成与标注的对话数据集,以支持更广泛的社区进行语言模型对齐研究。
本文方法
本文的核心贡献是通过一次大规模的全球众包活动,创建并发布了 OpenAssistant Conversations 数据集。
数据格式
数据集由一系列对话树(CT)组成。每个对话树的根节点是初始提示,后续节点交替扮演 \(prompter\) 和 \(assistant\) 的角色。每个父节点可以有多个子回复,形成树状分支结构。这种结构允许一条初始指令衍生出多条不同的对话路径。每个消息节点都附带元数据,如用户提供的质量标签、时间戳和语言信息。\(assistant\) 的回复还带有一个排序值(rank),表示其相对于其他兄弟回复的优劣。
数据收集
数据收集通过一个专门的 Web 应用进行,有超过 13,500 名志愿者参与。整个过程被分解为五个独立的微任务,以提高效率并减少因用户流失造成的数据损失。
- 创建提示 (Create a prompt):用户提交一个初始提示,作为新对话树的根。
- 扮演助理回复 (Reply as assistant):用户针对 \(prompter\) 的请求提供详细、有用的回答。
- 扮演提问者回复 (Reply as prompter):用户继续对话,可以提出澄清问题、修改意图或转换话题。
- 标注提示或回复 (Label a prompt or reply):用户对消息进行多维度评估,包括是否为垃圾信息、是否遵循指南(如包含仇恨言论、个⼈身份信息等),以及在质量、创造性、幽默性等多个维度上进行五分制打分。
- 排序助理回复 (Rank assistant replies):用户对同一提示下的多个 \(assistant\) 回复进行优劣排序。
质量控制
为确保数据质量,本文采取了多管齐下的方法:
- 贡献者指南:提供详细的指南,明确定义了标签含义、评分标准,并指导 \(assistant\) 的回复应礼貌、有益、简洁、安全,同时鼓励 \(prompter\) 的提问具有多样性和挑战性。
- 消息树状态机:通过自动化的流程管理对话树的生命周期,从未经审核的初始提示开始,经过生长阶段,最终达到完成状态,或因质量过低而被中止。这确保了每个对话树都经过了系统的审查和扩展。
- 激励与审核机制:
- 积分与排行榜:用户完成任务可获得积分,积分用于排行榜排名,以激励高质量贡献。如果贡献被其他用户评价为低质量或垃圾信息,积分会被扣除。
- Trollboard:一个面向管理员的特殊排行榜,展示收到负面标签最多的用户,帮助管理员高效地识别和审查潜在的恶意贡献者。
- 人工审核:用户可以举报不当内容,由社区志愿者管理员进行手动审查和删除。
数据集构成
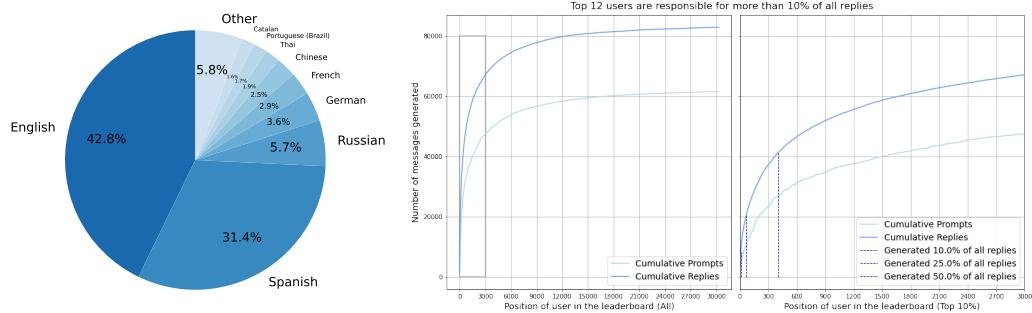
最终发布的数据集包含 161,443 条消息,分布在 66,497 个对话树中,涵盖 35 种不同语言,并附有 461,292 条质量评分。其中,人类提交的消息有 152,867 条。
- 语言分布:数据集以英语和西班牙语为主,这与项目社区的起源和推广有关。
- 贡献者分布:少数“超级用户”贡献了大部分数据,这可能在数据中引入偏差。
- 数据发布:数据集在 Hugging Face Hub 上以多种形式发布,推荐用于指令微调的版本是已完成并经过审核的对话树子集。
实验结论
为了验证数据集的有效性,本文基于 Pythia、LLaMA 和 Falcon 等开源模型,使用 OpenAssistant Conversations 数据集进行了监督微调(SFT)和基于人类反馈的强化学习(RLHF)实验。
模型性能
实验结果表明,使用 OpenAssistant Conversations 数据集进行微调的模型,在多个标准基准测试中(如 LMEH)的性能一致优于其对应的基础模型。例如,使用该数据集微调的 LLaMA-30B 模型甚至超过了更大的 LLaMA-65B 基础模型。然而,在不同基准上,RLHF 模型并不总是优于 SFT 模型。这表明数据集的有效性,同时也反映了自动评估语言模型的局限性。
| 模型 | LMEH | VEL | OAIE | HE |
|---|---|---|---|---|
| gpt-3.5-turbo (ChatGPT) | 1110 | 0.87 | 0.72 | |
| EleutherAI/pythia-12b | 60.33 | |||
| OpenAssistant/pythia-12b-sft-v8-7k-steps | 60.28 | 997 | 0.10 | 0.10 |
| tiiuae/falcon-40b | 72.29 | |||
| OpenAssistant/falcon-40b-sft-top1-560 | 74.04 | 1192 | 0.26 | 0.09 |
| OpenAssistant/falcon-40b-sft-mix-1226 | 74.40 | 1053 | 0.44 | 0.13 |
| huggyllama/llama-65b | 67.24 | |||
| OpenAssistant/oasst-sft-7e3-llama-30b | 68.03 | 979 | 0.52 | 0.20 |
| OpenAssistant/oasst-rlhf-3-llama-30b-5k-steps | 68.51 | 1068 | 0.51 | 0.15 |
垃圾信息与毒性分析
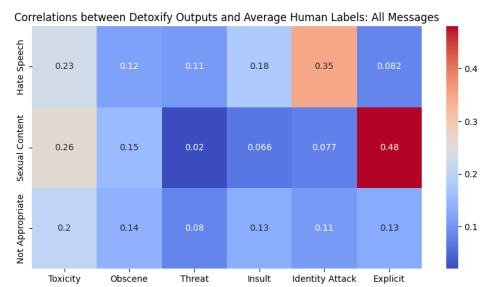
本文使用 Detoxify 模型对数据集中的内容进行了自动毒性评估,并与人类标注进行了比较。
- 一致性:自动毒性评分与人类的“仇恨言论”、“不当内容”等标签之间存在正相关性,验证了人类标注的有效性,也展示了自动化工具的潜力与局限。
- 审核有效性:通过比较被 moderators 删除的消息和保留在数据集中的消息,发现被删除消息的平均自动毒性评分显著更高。这证明了社区审核流程在过滤不当内容方面的有效性。
| 状态 | 毒性 | 淫秽 | 威胁 | 侮辱 | 身份攻击 | 露骨 | N |
|---|---|---|---|---|---|---|---|
| 已删除 | 4.625% | 1.965% | 0.411% | 2.085% | 0.651% | 1.39% | 3422 |
| 已保留 | 0.988% | 0.574% | 0.102% | 0.715% | 0.121% | 0.177% | 71359 |
总结
本文成功创建一个大规模、高质量的开放对话数据集,并证明了其在模型对齐任务中的价值。模型在标准基准上取得了一致的性能提升。然而,本文也承认存在局限性,如奖励模型的数据收集方式与 InstructGPT 不同、数据可能存在主观和文化偏见(贡献者以男性为主),以及数据集中可能仍残留少量不安全内容。因此,发布的模型仅推荐用于学术研究,并强烈建议使用者在使用前对其进行彻底的安全性和偏见评估。