OpenVLA: An Open-Source Vision-Language-Action Model
-
ArXiv URL: http://arxiv.org/abs/2406.09246v3
-
作者: Chelsea Finn; Quan Vuong; A. Balakrishna; Moo Jin Kim; Ethan Foster; Thomas Kollar; Rafael Rafailov; Benjamin Burchfiel; Dorsa Sadigh; Siddharth Karamcheti; 等8人
-
发布机构: Google DeepMind; MIT; Physical Intelligence; Stanford University; Toyota Research Institute; University of California, Berkeley
TL;DR
本文介绍并开源了一款名为OpenVLA的7B参数视觉-语言-动作(Vision-Language-Action, VLA)模型,该模型通过在包含970k真实世界机器人演示的大规模多样化数据集上进行训练,其通用操作能力不仅超越了参数量大7倍的闭源模型RT-2-X,并且首次系统地展示了如何利用参数高效微调(LoRA)与量化技术,在消费级硬件上实现对此类大模型的高效适配与部署。
关键定义
- 视觉-语言-动作模型 (Vision-Language-Action Model, VLA): 一种将预训练的视觉语言模型(VLM)直接微调用于机器人控制的模型。它接收图像(视觉)和自然语言指令(语言)作为输入,直接输出机器人控制指令(动作),将机器人控制问题统一在语言模型的生成框架下。
- OpenVLA: 本文提出的核心模型。这是一个7B参数的开源VLA,其架构基于Prismatic-7B VLM,该VLM融合了Llama 2语言模型、DINOv2和SigLIP视觉编码器。OpenVLA在Open X-Embodiment数据集的970k个轨迹上进行了微调,旨在提供一个高性能、可访问的通用机器人策略基座。
- Prismatic-7B: OpenVLA所基于的视觉语言模型(VLM)主干。其显著特点是采用了双视觉编码器:一个DINOv2编码器用于捕捉精细的空间和几何信息,一个SigLIP编码器用于捕捉高级语义信息。这种特征融合被证明对需要精确空间推理的机器人任务至关重要。
- 动作离散化 (Action Discretization): 将连续的机器人动作(如末端执行器的位移和旋转)转换为离散Token的过程,以便语言模型能够处理和生成。本文中,每个动作维度被均匀地离散化为256个“桶”,然后这些桶被映射到Llama 2分词器词汇表中256个最不常用的Token上。
相关工作
当前,用于机器人操作的学习策略普遍存在泛化能力不足的问题,它们难以适应训练数据之外的新物体、新场景或未见过的指令。虽然视觉和语言基础模型(如Llama 2)展现了强大的泛化能力,但如何有效利用它们来赋能机器人仍然是一个挑战。
现有的通用机器人策略(如Octo)通常是将预训练的视觉或语言模块与从零开始训练的模型组件“拼接”起来,而最近的VLA模型(如RT-2)虽然性能优越,但存在两大瓶颈:
- 闭源与不可及:现有最先进的VLA模型(如RT-2、RT-2-X)均为闭源,其模型架构、训练数据和训练流程细节不为公众所知,阻碍了社群的研究和发展。
- 缺乏高效适配方法:现有工作未探讨如何将这些大型VLA模型高效地微调(fine-tuning)到新的机器人、环境和任务中,尤其是在消费级硬件上,这是其实际落地的关键。
本文旨在解决上述两个核心问题,即提供一个强大的开源VLA模型,并探索使其易于被社群适配和部署的高效方法。
本文方法
本文介绍了OpenVLA模型,一个在Open X-Embodiment数据集的970k个机器人演示上训练的7B参数VLA。以下是其模型、训练和关键设计决策的详细阐述。
模型架构
OpenVLA的架构基于一个强大的预训练视觉语言模型Prismatic-7B,主要包含三个部分:
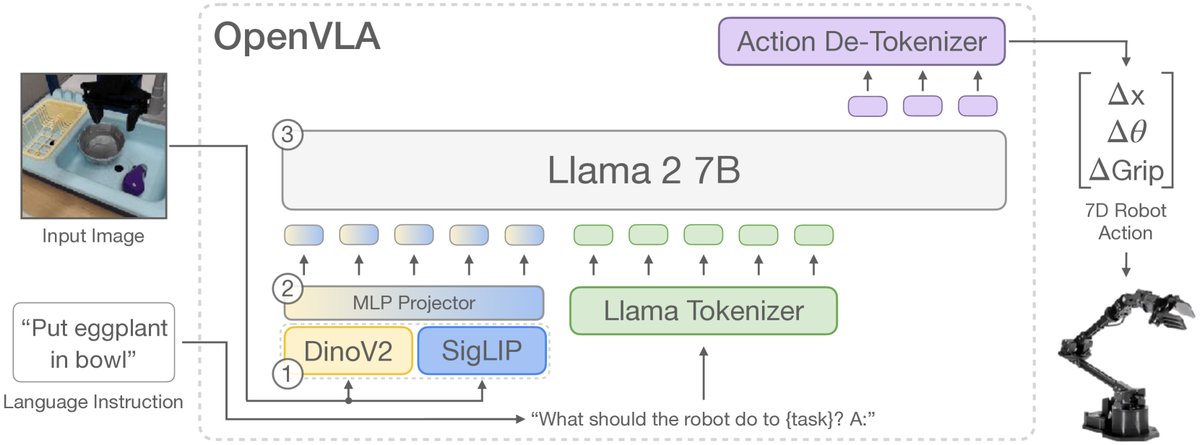
- 视觉编码器:这是一个创新的双重视觉编码器,它并行使用两个预训练模型:DINOv2和SigLIP。输入图像块同时通过这两个编码器,提取出的特征向量在通道维度上进行拼接。DINOv2擅长捕捉低层次的空间和几何信息,而SigLIP则提供高层次的语义理解。这种融合被证明能够提升模型的空间推理能力,对精确的机器人控制至关重要。
- 投影器 (Projector):一个简单的2层MLP,负责将拼接后的视觉特征向量映射到Llama 2语言模型的输入嵌入空间中。
- 大语言模型 (LLM) 主干:采用7B参数的Llama 2模型作为核心,负责整合视觉信息和语言指令,并自回归地生成动作序列。
训练过程
OpenVLA的训练过程将机器人动作预测问题转化为一个标准的下一Token预测任务。
- 动作表示:为了让LLM能够生成动作,连续的7维机器人动作(如末端执行器相对位移、旋转和夹爪状态)被离散化。具体来说,每个动作维度根据其在训练数据中的分布(1%到99%分位数之间)被均匀量化为256个离散值。这256个离散值随后被映射到Llama分词器词汇表中256个最不常用的Token上,从而使动作成为模型词汇表的一部分。
- 训练目标:给定当前的图像观测和语言指令,模型被训练来预测下一系列动作Token。训练采用标准的交叉熵损失函数,但损失计算仅限于预测的动作Token部分。
- 训练数据:为了实现强大的泛化能力,OpenVLA在一个精心策划的大规模数据集上进行训练。该数据集源自Open X-Embodiment (OpenX) 数据集,经过筛选和平衡,最终包含来自多个机器人平台、任务和场景的970k个轨迹。数据整理的目标是确保输入(第三人称视角图像)和输出(单臂末端执行器控制)的一致性,并平衡不同来源数据的贡献,以提升多样性。
创新点
- 架构选择:OpenVLA直接微调一个强大的、预对齐的VLM(Prismatic-7B),而不是像先前工作那样从头“拼接”不同模块。这一选择能更好地利用VLM在互联网规模数据上学到的视觉-语言联合先验知识。
- 融合视觉特征:通过采用结合DINOv2和SigLIP的双视觉编码器,模型获得了更强的空间推理能力,这在消歧多物体场景和精确操作方面展现出明显优势。
- 开源贡献:本文发布了首个高性能的通用VLA模型、完整的PyTorch训练代码库以及微调教程。这极大地降低了研究者进入该领域的门槛,为未来的VLA研究(如数据混合、训练目标和推理优化)提供了坚实的基础。
- 高效适配探索:本文是首个系统性研究并验证VLA模型高效适配可能性的工作。通过实验证明,参数高效微调(如LoRA)和模型量化等技术能够显著降低VLA模型在下游任务上的训练和部署成本,使其在消费级GPU上成为可能。
实验结论
本文通过在多个真实机器人平台上的广泛实验,验证了OpenVLA的有效性。
直接评估
在“开箱即用”的评估中,OpenVLA与先前的通用机器人策略(RT-1-X, Octo, RT-2-X)在WidowX和Google Robot两个平台上进行了比较。
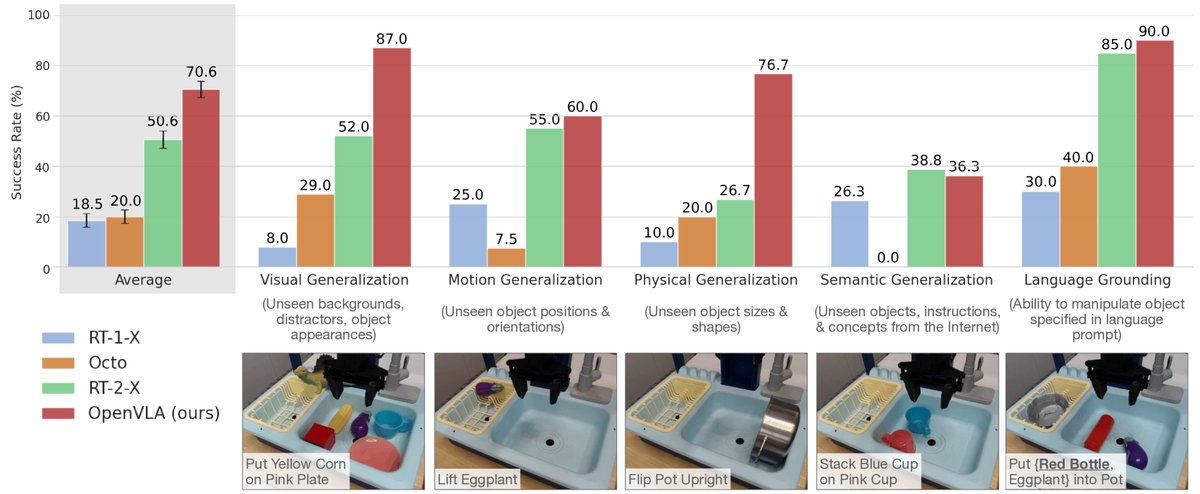

- 性能超越:OpenVLA (7B) 在BridgeData V2的29个任务上,绝对成功率比规模大近8倍的闭源SOTA模型RT-2-X (55B) 高出16.5%。在Google Robot任务上,两者表现相当。这证明了OpenVLA架构设计和训练数据选择的优越性。
- 泛化能力:相较于Octo等从零训练的策略,OpenVLA在面对视觉干扰、新物体和需要精确语言理解的任务时表现出显著更强的鲁棒性。
- 表现短板:在涉及训练数据中未见的互联网概念的“语义泛化”任务上,RT-2-X表现更优,这可能得益于其更大的模型规模和训练策略(在机器人数据和互联网数据上共同微调)。
数据高效的适配
实验在一个新的机器人平台(Franka Emika Panda)上评估了OpenVLA在小样本数据(10-150个演示)下的微调性能。
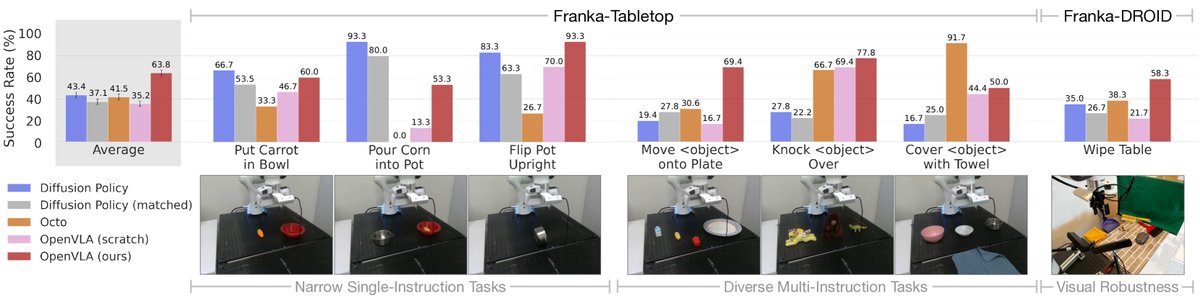
- 优于SOTA:与从零开始训练的SOTA模仿学习方法Diffusion Policy相比,微调后的OpenVLA在涉及多物体和复杂语言指令的多样化任务上表现更佳。
- 强大的基础模型:OpenVLA在所有测试任务上均取得了至少50%的成功率,表现出很强的综合能力,证明其可以作为一个强大的“默认选项”用于下游模仿学习任务。与之对比,未经过机器人数据预训练的VLM(OpenVLA (scratch))性能较差,凸显了大规模机器人数据预训练的重要性。
参数与内存高效的适配
本文进一步探索了在资源受限情况下适配OpenVLA的方法。
参数高效微调评估
| 策略 | 成功率 | 可训练参数 (百万) | 显存 (batch 16) |
|---|---|---|---|
| Full FT (完全微调) | 69.7 ± 7.2 % | 7,188.1 | 163.3 GB* |
| Last layer only (仅最后一层) | 30.3 ± 6.1 % | 465.1 | 51.4 GB |
| Frozen vision (冻结视觉) | 47.0 ± 6.9 % | 6,760.4 | 156.2 GB* |
| Sandwich | 62.1 ± 7.9 % | 914.2 | 64.0 GB |
| LoRA, rank=32 | 68.2 ± 7.5% | 97.6 | 59.7 GB |
| rank=64 | 68.2 ± 7.8% | 195.2 | 60.5 GB |
*: FSDP分片于2张GPU
- LoRA微调:低秩自适应(Low-rank adaptation, LoRA)微调在仅训练1.4%参数的情况下,达到了与完全微调相当的性能。这使得在单张A100 GPU上进行微调成为可能,计算成本降低了8倍。
量化推理的性能
| 精度 | Bridge 成功率 | 显存 |
|---|---|---|
| bfloat16 | 71.3 ± 4.8% | 16.8 GB |
| int8 | 58.1 ± 5.1% | 10.2 GB |
| int4 | 71.9 ± 4.7% | 7.0 GB |
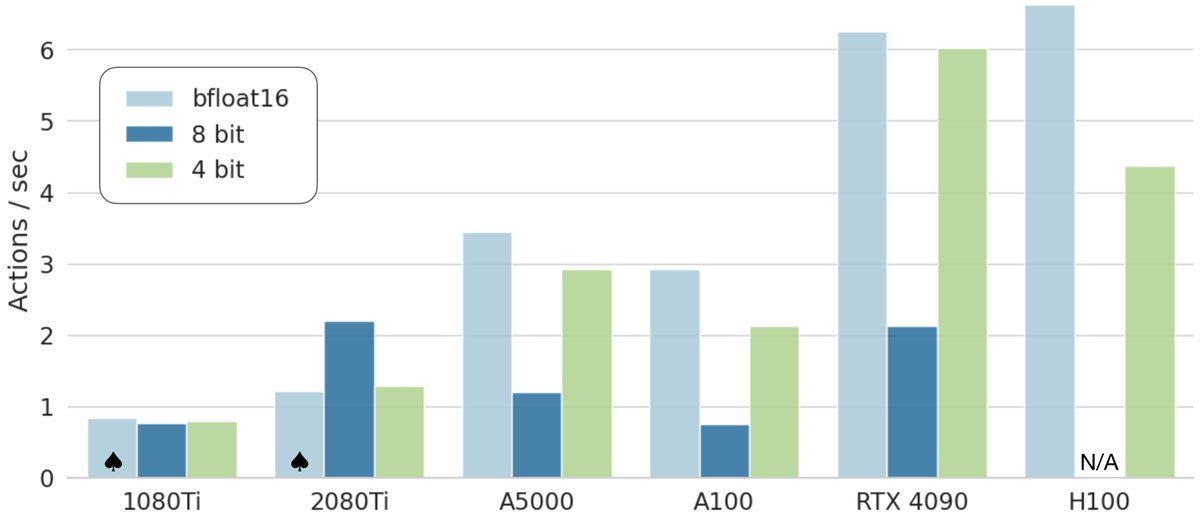
- 量化推理:4-bit量化可以在不牺牲任务成功率的情况下,将推理所需的显存从16.8GB降低到7.0GB。这使得OpenVLA能够流畅运行在拥有8GB显存的消费级GPU(如RTX 4090)上,并达到约6Hz的控制频率。
总结
OpenVLA不仅在性能上树立了开源通用机器人策略的新标杆,更重要的是,它通过开源模型和代码,并验证了一系列高效的适配与部署技术(LoRA和量化),为机器人社群利用和发展大规模基础模型铺平了道路,显著降低了技术门槛。