PaLM-E: An Embodied Multimodal Language Model
-
ArXiv URL: http://arxiv.org/abs/2303.03378v1
-
作者: Karol Hausman; Peter R. Florence; Igor Mordatch; Mehdi S. M. Sajjadi; Tianhe Yu; Q. Vuong; Daniel Duckworth; Corey Lynch; P. Sermanet; Vincent Vanhoucke; 等12人
-
发布机构: Google; Google Research; TU Berlin
TL;DR
本文提出了一种具身多模态语言模型 PaLM-E,通过将图像等连续的真实世界传感器数据直接注入到预训练语言模型的词嵌入空间,从而在一个统一的模型中实现了机器人规划、视觉问答和语言理解等多种任务,并证明了跨领域联合训练带来的正向知识迁移效应。
关键定义
- 具身语言模型 (Embodied Language Models):本文提出的核心概念,指一类直接将来自真实世界的连续传感器模态(如图像、机器人状态)整合到语言模型中的模型。这使得语言模型能够建立词语与感知之间的联系,从而进行更具“接地气”(grounded)的推理。
- 多模态语句 (Multimodal Sentences):PaLM-E 的核心输入形式。它是一种特殊的 Token 序列,其中来自不同模态(如图像、状态)的输入被编码成向量,并与文本 Token 的向量交错排列,形成一个统一的输入序列供语言模型处理。例如,\(Q: What happened between <img 1> and <img 2>?\)
- 实体指代 (Entity Referrals):一种针对物体中心(object-centric)表征的专门技术。在输入提示中,通过 \(Object 1 is <obj 1>\) 这样的文本为场景中的每个物体分配一个唯一的标签。这使得模型在生成的计划中可以使用如 \(obj 1\) 这样的特殊 Token 来明确指代特定物体,解决了当多个物体属性相似时难以用自然语言区分的问题。
相关工作
当前领域内,大型语言模型 (Large Language Models, LLMs) 已展现出强大的通用推理能力,但它们普遍面临接地气问题 (grounding problem):即难以将从海量文本中学到的抽象知识与现实世界的视觉、物理感知信息相关联。
先前的工作,如 SayCan,尝试通过“语言模型输出 -> 调用外部感知或策略模型 -> 获得反馈”的循环来解决机器人任务,但语言模型本身并未直接接触到视觉等非文本信息,这在需要精细几何理解的场景中存在局限。此外,当前顶级的视觉语言模型 (Visual-Language Models, VLMs) 虽然能处理图文任务,但在未经专门训练的情况下,直接应用于具身推理任务(如机器人规划)时效果不佳。
本文旨在解决上述接地气问题,目标是创建一个单一的、通用的多模态模型,该模型能够直接处理和理解来自机器人传感器的连续数据,并将其与语言知识无缝融合,从而有效执行具身推理任务(如机器人规划)和通用的视觉语言任务。
本文方法
PaLM-E 的核心思想是将机器人的视觉、状态等连续观测数据,通过编码器“翻译”成与语言 Token 相同维度的向量,然后将这些向量与文本 Token 向量混合,形成“多模态语句”,一同送入一个预训练的 LLM 进行处理。
 图1:PaLM-E 是一个通用的多模态语言模型,可以处理具身推理任务、视觉语言任务和纯语言任务。它将来自视觉-语言领域的知识迁移到具身推理中。PaLM-E 对多模态语句进行操作,即在文本 Token 中插入任意模态(如图像、神经3D表示或状态)的输入,并进行端到端训练。
图1:PaLM-E 是一个通用的多模态语言模型,可以处理具身推理任务、视觉语言任务和纯语言任务。它将来自视觉-语言领域的知识迁移到具身推理中。PaLM-E 对多模态语句进行操作,即在文本 Token 中插入任意模态(如图像、神经3D表示或状态)的输入,并进行端到端训练。
核心架构:多模态语句注入
PaLM-E 基于一个预训练的、仅解码器 (decoder-only) 的 LLM(如 PaLM)。其创新之处在于输入处理方式:
- 编码连续观测:对于一个连续观测 $O_j$(如一张图片),使用一个编码器 $\phi_j$ 将其映射为一个或多个向量序列,这些向量的维度 $k$ 與 LLM 的词嵌入空间维度相同。
-
构建多模态语句:将这些由观测编码而来的向量,与普通文本 Token 经过嵌入后的向量,按照在输入提示中指定的顺序交错排列。
\[x_i = \begin{cases} \gamma(w_i) & \text{如果 } i \text{ 是文本 Token} \\ \phi_j(O_j)_i & \text{如果 } i \text{ 对应观测 } O_j \end{cases} \quad (3)\]这里的 $x_i$ 是输入给 LLM Transformer 层的第 $i$ 个向量。
- 自回归生成:LLM 像处理纯文本一样处理这个混合向量序列,并自回归地生成文本作为输出。
输出与机器人控制
PaLM-E 的输出是文本。
- 对于视觉问答 (VQA) 等任务,输出的文本本身就是答案。
- 对于机器人规划任务,模型生成的文本是一系列高层指令(例如,“拿起红色积木”,“推到桌子角落”)。这些文本指令 následně 会被传递给一个已有的低层策略模型,由后者执行具体的机器人动作。PaLM-E 在此扮演了高层规划器的角色,它可以根据机器人执行后的新观测进行重新规划。
输入表征与编码器
本文探索了多种将不同传感器模态编码为向量的方法:
- 状态向量 (State estimation vectors):对于机器人的关节角度、物体位姿等低维状态向量,直接使用一个简单的多层感知机 (MLP) 将其编码。
- ViT (Vision Transformer):使用大规模预训练的 ViT 模型(如 ViT-4B 或 ViT-22B)作为图像编码器。ViT 输出的特征序列经过一个线性投影层,以匹配 LLM 的嵌入维度。
- 物体中心表征 (Object-centric representations):为了更好地与 LLM 的符号化处理方式对接,本文探索了将视觉输入分解为单个物体表征的方法。
- OSRT (Object Scene Representation Transformer):该方法无需分割掩码,能通过其架构的归纳偏置,以无监督方式从多视角图像中学习发现场景中的物体,并为每个物体生成一个“物体槽 (object slot)”向量。这些向量再通过 MLP 投影到 LLM 的嵌入空间。
训练策略
- 模型冻结 vs. 微调:
- 冻结 LLM:只训练输入侧的编码器(如 ViT)和投影层。这相当于为冻结的 LLM 学习一个由输入观测决定的“软提示 (soft-prompt)”,旨在不损害 LLM 原有的强大语言能力。
- 端到端微调:同时更新编码器、投影层和 LLM 的所有参数。
- 混合任务联合训练 (Co-training):本文的一个关键策略是将少量(约 8.9%)的具身机器人数据与海量的、多样化的互联网级视觉语言数据(如 VQA、图像描述)和纯语言数据混合在一起进行训练。其核心假设是,这种多样化的训练能够促进知识从通用领域向特定的机器人领域迁移。
实验结论

实验结果清晰地表明,将通用视觉语言数据与机器人数据混合训练,能显著提升模型在机器人任务上的性能、数据效率和泛化能力。
关键实验结果
- 正向知识迁移:这是本文最重要的发现。与仅在机器人数据上训练的模型相比,在“完整混合数据”上训练的 PaLM-E 在机器人规划任务上的性能得到了巨大提升(有时成功率翻倍以上)。这证明了从通用视觉语言领域到具身决策领域的知识迁移是真实有效的。这一现象在 TAMP 和 Language-Table 等多个机器人环境中都得到了验证。
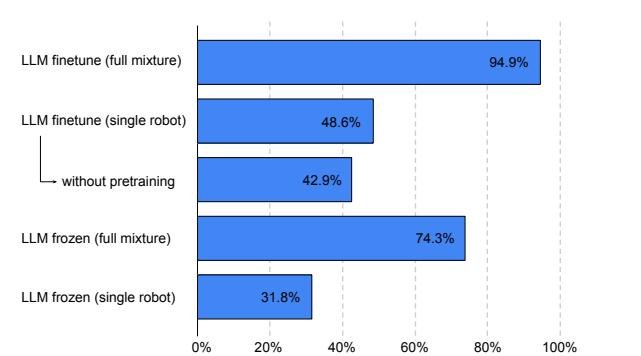 图4:TAMP 环境(1% 数据)中 PaLM-E-12B 的规划成功率。比较了使用完整训练混合数据、预训练以及冻结/微调语言模型的影响。来自完整混合数据的迁移效果尤其显著。
图4:TAMP 环境(1% 数据)中 PaLM-E-12B 的规划成功率。比较了使用完整训练混合数据、预训练以及冻结/微调语言模型的影响。来自完整混合数据的迁移效果尤其显著。
- 卓越的数据效率:得益于知识迁移,PaLM-E 仅需极少的机器人任务样本(例如,Language-Table 任务仅需 10 个示例,TAMP 任务仅需 320 个示例)就能达到很高的性能。这对于数据采集成本高昂的机器人领域至关重要。
- 优于基线模型:在具身推理任务上,PaLM-E 显著优于 zero-shot 的 SOTA 视觉语言模型 PaLI 和依赖外部模块的 SayCan。这证明了将视觉信息直接整合进 LLM 的架构是更优越的方案。
- 输入表征对比:在数据稀疏的场景下,基于几何和物体发现的 OSRT 表征展现出最高的学习效率和性能,凸显了结构化视觉输入的优势。
| 模型 | 物体中心 | LLM 预训练 | 具身 VQA | 规划 |
|---|---|---|---|---|
| q1, q2, q3, q4 | p1, p2 | |||
| SayCan (oracle afford.) | ✓ | - | 38.7, 33.3 | |
| PaLI (zero-shot) | ✓ | -, 0.0, 0.0, - | - | |
| PaLM-E (ViT-4B full mixture) | ✗ | ✓ | -, 70.7, 93.4, 92.1 | 74.1, 74.6 |
| PaLM-E (OSRT) | ✓ | ✓ | 99.7, 98.2, 100.0, 93.7 | 82.5, 76.2 |
表1:TAMP 环境中不同输入表征的性能对比(成功率%),仅使用 1% 训练数据。PaLM-E 在 VQA 和规划任务上均优于基线。ViT-4B 在“完整混合数据”上训练后性能大幅提升(从 30.6, 32.9 提升至 74.1, 74.6),显示了跨域迁移的效果。OSRT 表现最佳。
| PaLM-E 模型 (12B) | 训练数据 | LLM 冻结 | 10 Demos | 20 Demos | 40 Demos |
|---|---|---|---|---|---|
| 任务1 成功率 (%) | |||||
| PaLM-E-12B | 单一机器人数据 | n/a | 20.0 | 30.0 | 50.0 |
| PaLM-E-12B (finetune) | 完整混合数据 | ✗ | 70.0 | 80.0 | 80.0 |
表2 (简化版):Language-Table 仿真环境中规划任务成功率。使用“完整混合数据”训练的模型在少样本(10 demos)场景下性能远超仅用机器人数据训练的模型(70% vs 20%)。
- 模型规模的影响:
- 缓解灾难性遗忘:在进行端到端微调时,模型规模越大,其原有的语言能力被遗忘的程度就越低。PaLM-E-562B 在多模态训练后,其语言能力仅下降了 3.9%,而 PaLM-E-12B 则下降了 87.3%。
- 提升泛化能力:更大的模型在分布外任务(如处理更多物体的场景)上表现出更好的泛化性。
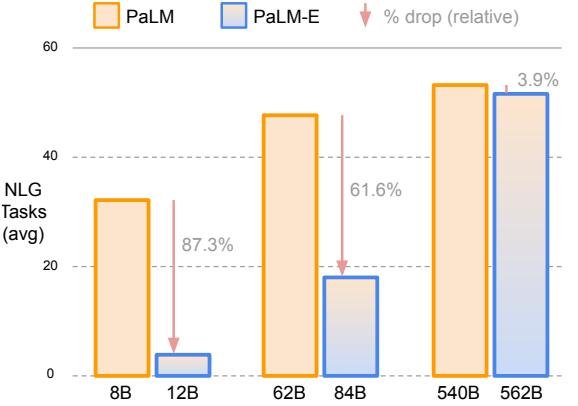 图6:通用语言任务性能。模型规模越大,多模态训练后对原有语言能力的灾难性遗忘越少。
图6:通用语言任务性能。模型规模越大,多模态训练后对原有语言能力的灾难性遗忘越少。
最终结论
PaLM-E 成功证明,通过将连续的传感器数据注入 LLM 的嵌入空间,可以创建一个强大的、端到端的具身多模态模型。该模型不仅能够有效地执行多类机器人上的复杂规划任务,同时也是一个性能顶尖的通用视觉语言模型。其核心贡献在于揭示并利用了从大规模通用数据到特定具身任务的正向知识迁移,极大地提升了机器人在数据稀疏环境下的学习效率。扩展模型规模是保留其强大语言能力同时获得具身能力的关键路径。
 图5:单个 PaLM-E 模型在两个真实机器人上执行任务。左图是在厨房中执行长时程移动操作任务,右图是在桌面操作机器人上展示单样本/零样本泛化能力。
图5:单个 PaLM-E 模型在两个真实机器人上执行任务。左图是在厨房中执行长时程移动操作任务,右图是在桌面操作机器人上展示单样本/零样本泛化能力。