Paper2Agent: Reimagining Research Papers As Interactive and Reliable AI Agents
-
ArXiv URL: http://arxiv.org/abs/2509.06917v1
-
作者: Jiacheng Miao; James Zou
-
发布机构: Stanford University
TL;DR
本文提出了 Paper2Agent,一个自动化框架,它能将研究论文及其代码库转化为交互式、可靠的AI智能体,让用户能通过自然语言使用论文中的方法,从而加速科学知识的传播和应用。
关键定义
本文主要建立在一个现有协议之上,并围绕它构建了新的概念:
-
Paper2Agent: 本文提出的核心框架。它是一个多智能体AI系统,能够自动分析研究论文和相关代码库,将其中的方法、数据和工作流封装成一个可供AI调用的标准化服务器,从而将静态的论文“激活”成一个可交互的智能体。
-
模型上下文协议 (Model Context Protocol, MCP): Paper2Agent 框架所依赖的行业标准协议。MCP为大型语言模型(LLM)和智能体提供了一个统一的接口,使其能够访问外部的工具和资源,而无需进行定制化集成。
- MCP 服务器 (MCP Server): Paper2Agent 流程的核心产物。每个服务器代表一篇论文,包含三个关键组件:
- MCP 工具 (Tools): 封装了论文核心方法的可执行函数,并预配置了运行环境。
- MCP 资源 (Resources): 论文相关的静态资产,如论文文本、数据集、图表等。
- MCP 提示 (Prompts): 编码了复杂、多步骤分析流程的模板,用于指导AI智能体按正确顺序执行任务。
- 论文智能体 (Paper Agent): 将一个通用的AI聊天智能体(如 Claude Code)与特定论文的MCP服务器连接后形成的最终产品。用户可以通过自然语言与该智能体对话,调用论文中的复杂方法完成科学分析任务。
相关工作
当前,科学研究成果主要以研究论文的形式传播。然而,论文是一种被动的知识载体。读者若想应用论文中提出的新计算方法,通常需要投入大量精力去发现、理解和调试其代码,包括安装依赖、配置环境、解读API等,这构成了知识传播和复用的巨大障碍。
为了解决这一问题,学术界已有一些尝试:
- 可执行论文 (Executable Papers):如基于 Jupyter Notebook 的出版物,虽提升了可复现性,但仍要求用户具备相当的技术背景。
- Papers with Code:该平台通过链接论文与代码库改善了代码的可发现性,但并未解决安装和执行代码的技术壁纯。
- 通用AI科学家平台:一些新兴平台致力于构建通用的AI科研助手,但它们并非为转化特定研究成果而设计。
本文旨在解决的具体问题是:如何将任何一篇包含计算方法的研究论文,从一个静态的知识制品,自动转化为一个动态、交互式且易于使用的AI智能体,从而彻底消除普通用户(尤其是缺乏编程背景的科学家)在应用前沿方法时遇到的技术壁垒。
本文方法
本文提出的 Paper2Agent 框架,其核心思想是将一篇研究论文及其相关资产,通过自动化的方式,打包成一个遵循 MCP 标准的远程服务器。这个服务器随后可以被任何兼容的AI智能体调用,从而化身为一个“懂”这篇论文的专业智能体。
框架工作流
Paper2Agent 的工作流程由一个多智能体系统驱动,如下图所示,主要包括代码提取、环境配置、工具封装、迭代测试和最终部署几个阶段。
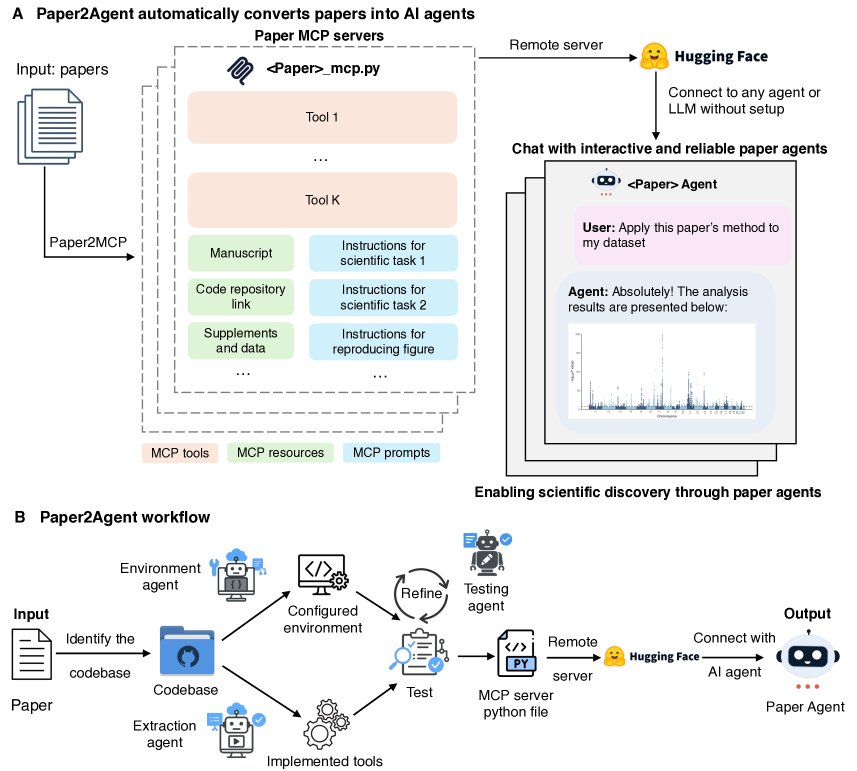
- 代码库提取与环境配置:工作流始于一篇论文及其关联的代码库。首先,一个环境智能体 (environment agent) 会自动分析代码依赖,配置一个可复现的软件环境。
- 方法提取与工具封装:接着,一个提取智能体 (extraction agent) 负责识别代码库中的核心分析功能,并将它们封装成标准化的 MCP 工具 (MCP Tools)。这些工具是模块化的、可执行的函数,代表了论文的主要方法论贡献。
- 迭代测试与稳健性验证:这是确保智能体可靠性的关键步骤。一个测试智能体 (testing agent) 会自动运行验证测试,将封装工具的输出与论文报告的结果或示例数据进行对比。通过迭代式的“测试-反馈-修正”循环,不断完善工具代码和运行环境,直到结果完全匹配,从而有效避免了大型语言模型常见的“代码幻觉”问题,保证了科学分析的准确性。
- MCP 服务器构建与部署:一旦所有工具通过验证,它们就会与论文相关的MCP 资源(如数据集、文本)和MCP 提示(用于指导复杂工作流)一同被打包成一个 MCP Python 文件。该文件随后被部署到远程服务器(如 Hugging Face Spaces),形成一个独立的 MCP 服务器。
- 论文智能体实例化:最后,将一个通用的AI聊天智能体(本文使用 Claude Code)连接到该 MCP 服务器。通过这种方式,就创建了一个专门针对该论文的论文智能体,用户可以通过自然语言与其交互来执行复杂的分析。
创新点
- 自动化与可靠性的结合:通过专门的测试智能体进行迭代验证,确保了从代码到工具的转化是忠实且可复现的。这解决了AI直接生成代码可能带来的不可靠和不准确问题。
- 标准化与模块化:采用 MCP 协议,使得生成的论文智能体具有良好的互操作性。不同的论文智能体(即不同的MCP服务器)可以被同一个聊天界面灵活调用和组合,实现跨研究成果的协同分析。
- 交互范式的转变:Paper2Agent 将科学知识从静态的文档转变为动态的、可对话的实体。用户不再需要“阅读并实现”论文,而是可以直接“使用和查询”论文,极大地降低了前沿科研成果的应用门槛。
实验结论
本文通过三个案例研究,展示了 Paper2Agent 在不同生物信息学领域的有效性。
AlphaGenome 智能体(基因组数据解读)
- 成果: Paper2Agent 自动为 AlphaGenome(一个用于预测DNA变异影响的AI模型)生成了22个MCP工具,涵盖了其全部核心功能。
- 验证: 该智能体在复现原始教程的15个任务和一系列全新的未知任务上均达到了100%的准确率,证明了其可靠性和泛化能力。
- 发现: 在一个分析GWAS位点的任务中,该智能体通过自主规划和执行,得出了与原论文不同的潜在致病基因推断(优先考虑SORT1基因而非CELSR2/PSRC1),这一新假设得到了外部数据(GTEx eQTL)的支持。这表明论文智能体不仅能复现,还能用于重新评估和挑战已有结论。

TISSUE 智能体(空间转录组学分析)
- 成果: 为 TISSUE 方法(一种用于空间转录组学不确定性分析的方法)生成了6个核心工具。
- 验证: 在处理新数据时,该智能体成功复现了人类专家手动运行整个分析流程的结果,证明了其处理完整工作流的能力。
- 亮点: TISSUE 智能体还能充当一个交互式问答向导,向用户解释方法所需的输入格式。同时,它利用 MCP 资源,将论文中提及的数据集构建成一个结构化注册表,实现了“根据需求自动下载数据并运行分析”的无缝体验。

Scanpy 智能体(单细胞数据预处理)
- 成果: 针对广泛使用的 Scanpy 工具包,Paper2Agent 快速生成了7个用于单细胞数据预处理和聚类的工具。
- 亮点: 本案例重点展示了 MCP 提示 (MCP Prompts) 的应用。框架自动从代码中推断出标准的分析流程(如质控、标准化、降维、聚类等),并将其编码为一个MCP提示。用户只需提供数据路径,智能体便能遵循该提示,自动按正确顺序执行整个工作流。
- 验证: 在三个未用于训练的公开单细胞数据集上,Scanpy 智能体成功复现了人类专家的处理结果,验证了MCP提示在简化复杂工作流执行方面的有效性。

总结
实验结果有力地证明,Paper2Agent 能够将不同领域的复杂计算研究论文成功转化为可靠、易用、可交互的AI智能体。这些智能体不仅能精确复现原文结果,还能泛化到新数据上,并以自然语言交互的方式,极大地降低了科研方法的应用门槛。本文提出的框架为科学知识的传播和利用开创了一种全新的范式。