ParallelMuse: Agentic Parallel Thinking for Deep Information Seeking
-
ArXiv URL: http://arxiv.org/abs/2510.24698v1
-
作者: Zhengwei Tao; Yong Jiang; Pengjun Xie; Runnan Fang; Jingren Zhou; Haiyang Shen; Jialong Wu; Yida Zhao; Baixuan Li; Wenbiao Yin; 等11人
-
发布机构: Alibaba Group; Tongyi Lab
TL;DR
本文提出了一种名为 ParallelMuse 的两阶段智能体并行思维框架,通过“功能指定的局部展开”策略和“压缩推理聚合”方法,在提升深度信息寻求 (deep information-seeking) 任务效果的同时,显著降低了探索所需的Token成本。
关键定义
- ParallelMuse: 本文提出的核心框架,是一个用于深度信息寻求智能体的两阶段并行思维范式。它包含“功能指定的局部展开”和“压缩推理聚合”两个阶段,分别对应并行思考中的探索性采样和答案生成过程。
- 功能指定的局部展开 (Functionality-Specified Partial Rollout): ParallelMuse 的第一阶段。该方法将智能体生成的序列划分为“推理”和“探索”等功能区域,独立评估各区域的不确定性,并从不确定性高的步骤(即探索潜力大的步骤)进行选择性地分支扩展,同时通过复用上下文(KV Cache)来提升效率。
- 压缩推理聚合 (Compressed Reasoning Aggregation): ParallelMuse 的第二阶段。该方法将多条完整的推理轨迹压缩成保留核心逻辑的结构化报告,每份报告包含问题分解、工具调用和答案综合等关键信息。最后,模型基于这些浓缩的报告进行综合推理,生成最终答案,从而避免了传统多数投票或置信度选择的弊端。
- 功能区域 (Functional Regions): 本文将智能体在每个步骤中生成的Token序列划分为两个功能子集:用于内部思考的推理Token (\(reasoning tokens\), $\mathcal{T}^{r}_{t}$) 和用于调用工具与环境交互的探索Token (\(exploration tokens\), $\mathcal{T}^{e}_{t}$)。这两个区域展现出不同的不确定性模式,是进行针对性局部展开的基础。
相关工作
当前,通过与环境持续互动和内部推理,深度信息寻求(IS)智能体已经能够解决复杂问题。在此背景下,并行思考作为一种测试时扩展(test-time scaling)的方法,通过增加并行探索路径的数量来拓宽搜索范围,从而提升性能。
然而,现有的并行思考方法存在两大瓶颈:
- 探索效率低下:传统的展开(rollout)策略在每次迭代时都从头开始,这在探索多样性较低的推理阶段尤其低效且消耗大量Token。尽管有方法通过不确定性来指导分支,但它们通常假设所有Token功能同质,这与智能体任务中“推理”和“工具调用”行为具有不同不确定性模式的现实不符。
- 聚合方法失效:在复杂的智能体任务中,由于采样空间巨大,正确答案往往只占少数,导致多数投票(majority voting)等方法失效。同时,不断融入的外部信息会干扰模型的置信度校准,使基于置信度的选择也不可靠。仅聚合最终答案会忽略中间过程,而聚合完整轨迹又因上下文长度限制而不可行。
本文旨在解决上述问题,提出一个专为深度信息寻求智能体设计的、更高效、更可靠的并行思考框架。
本文方法
本文提出的 ParallelMuse 是一个由两个互补部分组成的两阶段智能体并行思维范式:(i)功能指定的局部展开 (Functionality-Specified Partial Rollout) 和(ii)压缩推理聚合 (Compressed Reasoning Aggregation)。这两个部分分别对应并行思考过程中的探索性采样和答案生成阶段。
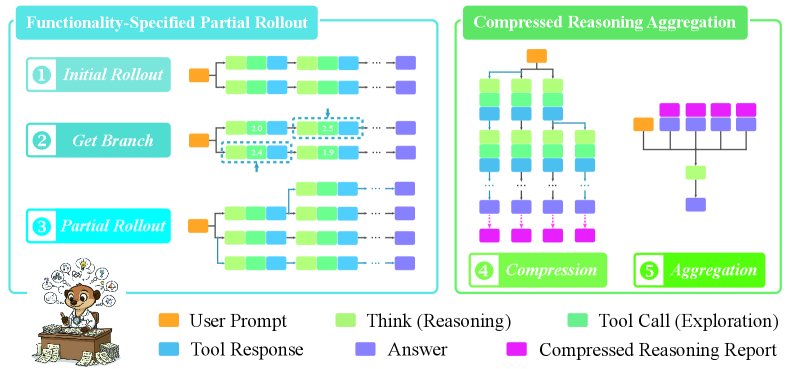 ParallelMuse 的工作流程,包括(左)功能指定的局部展开,其中根据(探索)工具调用的不确定性选择top-k步骤作为分支标准(仅为例),以及(右)压缩推理聚合。
ParallelMuse 的工作流程,包括(左)功能指定的局部展开,其中根据(探索)工具调用的不确定性选择top-k步骤作为分支标准(仅为例),以及(右)压缩推理聚合。
功能指定的局部展开 (Functionality-Specified Partial Rollout)
此阶段旨在通过更智能的采样策略,提高探索效率。
创新点
1. 功能指定的切入点识别:智能体模型生成的Token天然地被特殊标记(如 \(<thought>\) 和 \(<tool_code>\))划分为不同的功能区域。本文利用这些标记识别出推理和探索片段。为了识别探索潜力最高的推理步骤,本文通过计算每个功能区域内的困惑度(Perplexity, PPL)来量化模型的不确定性。
\[\text{PPL}(f,t)=\exp\left(-\frac{1}{ \mid \mathcal{T}^{f}_{t} \mid }\sum_{x_{t,i} \in \mathcal{T}^{f}_{t}}\log p(x_{t,i}\mid x_{<t,i})\right),\quad f\in\{r,e\}\]其中 $f$ 代表功能区域($r$ 为推理,$e$ 为探索)。该过程通过离线分析少量初始轨迹,选定不确定性最高的 \(top-k\) 个步骤作为后续局部展开的“切入点”。
2. 异步局部展开:从选定的高不确定性步骤开始,系统异步地启动额外的局部展开。每个分支直接复用先前的上下文(通过键值缓存,Key-Value (KV) cache),而不是从头生成,从而避免了冗余的前向传播,显著节省了Token和计算成本。通过异步调度引擎,多个分支可以并发扩展,进一步提升效率。
优点
该方法的加速来源于前缀复用 (prefix reuse)和异步并行 (asynchronous parallelization)。总加速比近似为:
\[\text{Speedup}_{\text{total}}\approx\left(1+\frac{\sum_{j}p_{j}}{\sum_{j}s_{j}}\right)P\]其中 $p_j$ 是复用前缀的长度,$s_j$ 是生成后缀的长度,$P$ 是并行分支数。这种设计联合利用了确定性的前缀复用和异步并行,以较低的Token成本实现了近线性的探索效率提升。
压缩推理聚合 (Compressed Reasoning Aggregation)
此阶段旨在解决如何从多个探索路径中可靠地生成最终答案。
创新点
1. 结构化的报告式压缩:本文观察到智能体的完整推理轨迹包含大量冗余信息。为此,该方法首先将每个候选推理轨迹压缩成一份结构化的报告。该报告只保留推导答案所必需的核心要素:
- 问题分解 (Problem Decomposition):描述主问题如何分解为子问题及其相互依赖关系。
- 工具调用 (Tool Invocation):明确为解决各子问题所调用的工具、参数及获得的中间答案。
- 答案综合 (Answer Synthesis):阐述如何整合子问题和子答案以得出最终结论。 通过这种方式,无关的探索内容被剔除,有效地重构了对答案推导至关重要的信息状态图 $\mathcal{G}$。
2. 推理引导的答案聚合:获得 N 份压缩报告后,模型可以在有限的上下文窗口内,对所有候选路径的全局推理逻辑进行综合评估,而不仅仅关注最终答案。在聚合阶段,模型被明确指示要基于推理的连贯性而非答案的一致性来做判断,从而减轻了多数答案的偏见。同时,由于报告已包含充分的溯源信息,此阶段无需进行额外的工具调用,纯粹基于报告内容进行推理。
优点
这种方法能够在有限的上下文中高效地整合更丰富的中间推理信息。通过对推理连贯性的全面评估,它能生成更可靠、更合理的最终答案,同时避免了传统聚合方法的系统性偏差。
实验结论
本文在四个具有挑战性的深度信息寻求基准(BrowseComp、BrowseComp-zh、GAIA、HLE)上,针对四种不同参数规模的开源智能体模型(GPT-OSS-20B/120B, DeepSeek-V3.1-T, Tongyi-DR-30B-A3B)进行了全面评估。
-
总体性能显著提升:在所有模型和基准上,ParallelMuse 均一致且显著地超越了包括标准推理、多数投票等在内的所有基线方法。尤其在 Tongyi-DR-30B-A3B 模型上应用后,其性能达到甚至超过了部分闭源智能体。实验还证实,基于置信度的聚合方法在智能体任务中因外部信息干扰而表现不佳,而 ParallelMuse 通过其独特的聚合机制有效避免了这一问题。
-
局部展开策略的有效性:不确定性引导的局部展开策略持续优于从零开始的完整展开。这表明该方法能像蒙特卡洛树搜索(MCTS)一样,将有限的采样预算集中在探索收益预期更高的区域,从而提高了探索的效率和效果。
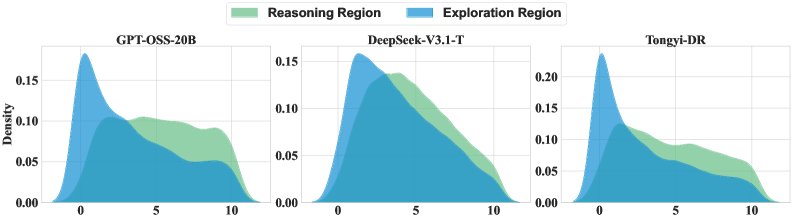 在 BrowseComp 子集上,不确定性最高的4个步骤的分布。结果显示,探索不确定性(PPL(e,t))在任务初期最高,而推理不确定性(PPL(r,t))在稍后信息整合阶段达到峰值。
在 BrowseComp 子集上,不确定性最高的4个步骤的分布。结果显示,探索不确定性(PPL(e,t))在任务初期最高,而推理不确定性(PPL(r,t))在稍后信息整合阶段达到峰值。 -
压缩推理聚合的增益:即使不使用第一阶段的局部展开,仅凭第二阶段的“压缩推理聚合”方法,性能提升也最为显著。这证明了该方法通过对推理轨迹进行近无损压缩,并高效整合关键信息,能够在不增加额外工具调用的情况下,最大化地利用已采样的信息,平衡了效率与求解质量。
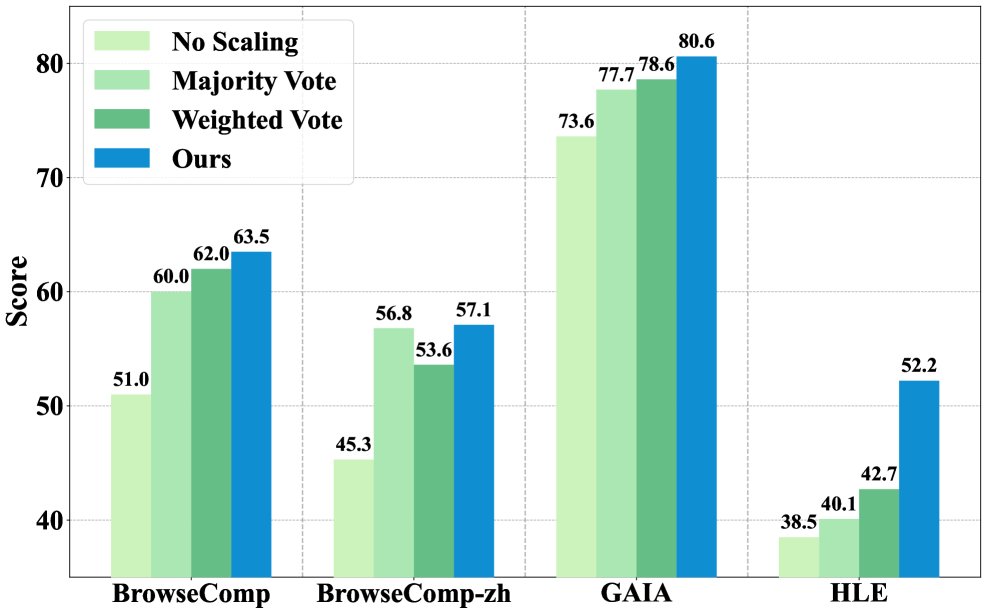 在固定采样(8次从零展开)的条件下,本文的压缩推理聚合方法(CRA)带来的性能提升最大。
在固定采样(8次从零展开)的条件下,本文的压缩推理聚合方法(CRA)带来的性能提升最大。 -
效率优势:ParallelMuse 的效率增益来自两个方面:
- 上下文复用节省Token:通过在局部展开中复用上下文,该方法相较于从零开始的展开节省了高达 83.3% 的Token消耗。
- 轨迹压缩降低聚合成本:轨迹压缩显著减少了最终聚合阶段所需的上下文Token数量。
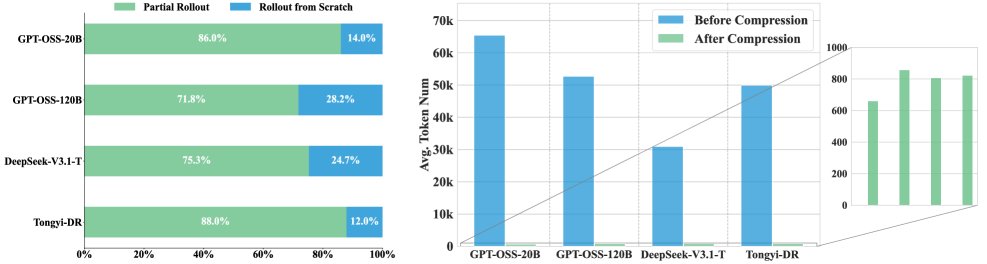 (左)局部展开通过上下文复用减少了Token消耗;(右)轨迹压缩前后上下文Token用量的对比。
(左)局部展开通过上下文复用减少了Token消耗;(右)轨迹压缩前后上下文Token用量的对比。
最终结论:本文提出的 ParallelMuse 框架通过其两阶段设计——功能指定的局部展开和压缩推理聚合——成功地解决了现有并行思考方法在深度信息寻求智能体应用中的效率和可靠性瓶颈,为智能体推理的研究提供了新的思路和有效的实践方法。