Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
-
ArXiv URL: http://arxiv.org/abs/2404.14219v4
-
作者: Young Jin Kim; Michael Santacroce; Hardik Modi; Anh Nguyen; Ahmed Awadallah; Nikos Karampatziakis; Mahoud Khademi; Ning Shang; J. Aneja; P. Witte; 等78人
TL;DR
本文介绍了phi-3系列模型,特别是38亿参数的phi-3-mini,它通过在一个精心筛选和合成的高质量数据集上进行训练,实现了与Mixtral 8x7B和GPT-3.5等大模型相媲美的性能,同时其模型尺寸小到可以在手机上本地部署。
关键定义
- Phi-3 模型家族 (Phi-3 model family): 本文发布的一系列语言模型,主要包括:
- phi-3-mini: 38亿参数,为在资源受限设备(如手机)上高效运行而优化。
- phi-3-small: 70亿参数,引入了新的块稀疏注意力机制。
- phi-3-medium: 140亿参数,是phi-3-mini的直接扩展。
- phi-3.5 系列: 针对特定能力增强的版本,包括支持多语言和长上下文的\(phi-3.5-mini\),采用混合专家架构的\(phi-3.5-MoE\),以及多模态模型\(phi-3.5-Vision\)。
-
数据最优机制 (Data Optimal Regime): 与追求“计算最优”不同,这是一种为特定规模的模型校准训练数据的策略。它强调数据质量而非数量,通过精细过滤公共网络数据并结合合成数据,优先保留能提升模型“推理能力”的内容,而舍弃对小模型而言容量过载的纯“知识性”信息。
- 块稀疏注意力 (Blocksparse Attention): 为phi-3-small模型设计的一种新颖注意力模块。它为每个注意力头强制施加不同的稀疏模式,将上下文划分为块,使每个查询Token在不同头上关注不同的键值(KV)缓存块组合(包括局部块和远距离的垂直步进块),从而在减少KV缓存的同时,保证了对全局信息的捕获。
相关工作
当前大型语言模型(Large Language Models, LLMs)研究的主流趋势是通过不断增大模型和数据集规模来提升性能,即遵循所谓的“缩放定律” (scaling laws)。然而,这些定律通常假设数据源是固定的。这一假设正被前沿LLM自身的能力所打破,因为它们可以用来创造和筛选更高质量的数据。
此前的phi系列模型(如phi-2)已经证明,通过结合LLM筛选的公共数据和LLM生成的合成数据,小型模型能够达到通常只有大数十倍的模型才能企及的性能水平。然而,如何将这种以数据为中心的方法进一步扩展,创造出一个既能媲美业界顶尖模型(如GPT-3.5),又小到足以在手机等终端设备上运行的模型,仍然是一个具有挑战性的问题。
本文旨在解决这一问题,通过对phi-2使用的数据配方进行大规模升级和改进,探索在“数据最优机制”下,小型语言模型的性能极限。
本文方法
本文的核心思想是延续并大规模扩展“教科书级别”高质量数据的训练范式,以突破传统缩放定律的限制,用更小的模型尺寸实现顶尖的性能。
训练方法论
1. 数据为核心的训练策略
本文的训练方法继承自“Textbooks Are All You Need”的研究路径,其关键在于训练数据的质量。训练数据由两部分组成:
- 高度过滤的公共网络数据: 根据“教育价值”从各种开放互联网源中筛选而来。
- 合成的LLM生成数据: 用于教授模型逻辑推理和各种特定技能。
这种方法旨在将训练过程校准到前述的“数据最优机制”,即为特定模型规模精心挑选最有效的数据组合,优先保证模型的“推理”能力而非单纯的“知识”存储。
2. 两阶段预训练
预训练分两个不相交的连续阶段进行:
- 阶段一: 主要使用旨在传授通用知识和语言理解的网络数据。
- 阶段二: 混合了过滤更严格的网络数据(阶段一的子集)和旨在教授逻辑推理等高级技能的合成数据。
3. 训练后对齐
预训练完成后,模型经过两个阶段的训练后对齐:
- 监督微调 (Supervised Finetuning, SFT): 使用覆盖数学、编码、推理、对话、模型身份和安全等领域的高质量数据进行微调。
- 直接偏好优化 (Direct Preference Optimization, DPO): 利用偏好数据(特别是将不希望的输出作为“拒绝”响应)来引导模型远离不良行为,提升其作为AI助手的交互效率和安全性。
模型架构
phi-3-mini (3.8B)
- 架构: 标准的Transformer解码器架构,与Llama-2结构相似,以便社区复用现有生态工具。
- 参数: 32层,32个注意力头,隐藏层维度为3072。
- 上下文长度: 默认为4K,通过LongRope可扩展至128K(phi-3-mini-128K版本)。
- Tokenizer: 使用与Llama-2相同的tokenizer,词汇表大小为32064。
- 部署: 可被量化至4-bit,内存占用约1.8GB,能够在iPhone 14上以超过12 tokens/秒的速度本地运行。


phi-3-small (7B)
- 架构: 32层,32个注意力头,隐藏层维度4096。采用GEGLU激活函数和muP进行超参数调优。
- Tokenizer: 使用tiktoken tokenizer,以获得更好的多语言分词效果。
- 创新点:
- 分组查询注意力 (Grouped-Query Attention): 4个查询共享1个键,以提升效率。
- 块稀疏注意力 (Blocksparse Attention): 这是本文的一个关键架构创新。它将密集注意力层和块稀疏注意力层交替使用,通过在不同注意力头上应用不同的稀疏模式来关注KV缓存的不同块,显著减少了KV缓存大小,同时通过高效的Triton内核实现训练和推理加速。

phi-3.5-MoE (16x3.8B)
- 架构: 采用混合专家 (Mixture-of-Experts, MoE) 架构,总参数42B,激活参数6.6B。
- 机制: 在16个专家网络中采用Top-2路由,每个token会激活其中的2个专家。使用SparseMixer方法训练稀疏路由器。
phi-3.5-Vision (4.2B)
- 架构: 一个多模态模型,由图像编码器(CLIP ViT-L/14)和文本解码器(phi-3.5-mini)组成。
- 图像处理: 使用动态裁剪策略处理高分辨率和不同宽高比的图像,将图像分割成块,并将这些块的token拼接起来。
- 训练: 预训练数据包含图文交错文档、图文对、OCR处理的PDF、图表数据和纯文本数据。训练后阶段同样经过SFT和DPO,以增强其在自然图像理解、图表推理、多图比较等多方面的能力。
实验结论
实验结果表明,Phi-3系列模型在保持小尺寸的同时,在多个标准基准测试中展现出与更大模型相当甚至更优的性能。
核心实验结果
- phi-3-mini (3.8B) 在MMLU上取得69%,MT-bench上得分8.38,性能与Mixtral 8x7B和GPT-3.5不相上下。在GSM-8K(数学推理)和HumanEval(代码生成)等任务上甚至超过了这些大得多的模型。
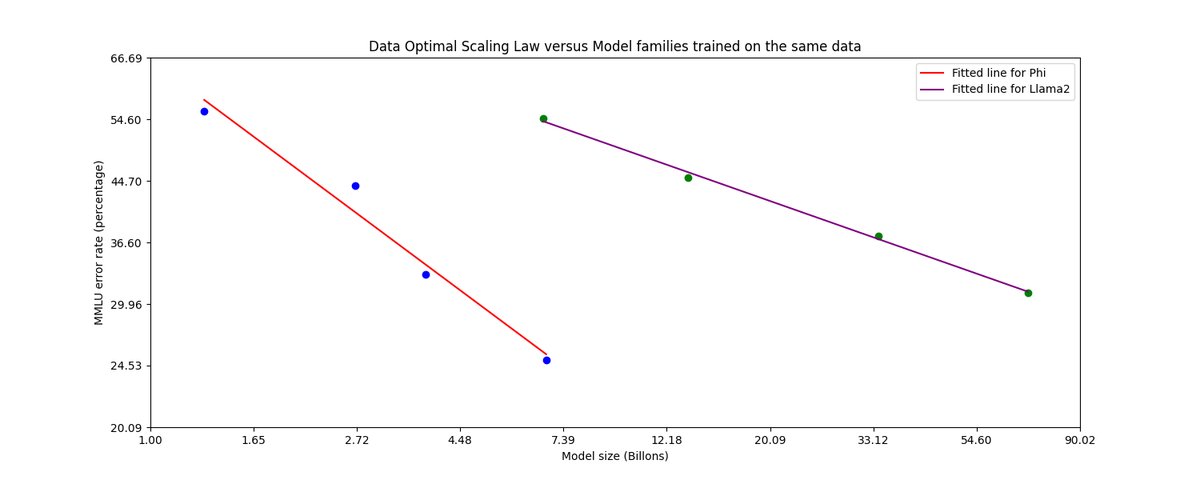
- 模型规模扩展后,phi-3-small (7B) 和 phi-3-medium (14B) 的性能持续提升,MMLU得分分别达到75.7%和78.0%,验证了数据策略在更大模型上的有效性。下图展示了Phi系列在“数据最优机制”下的扩展性能优于在固定数据上训练的Llama-2系列。
- phi-3.5-MoE 在各项基准测试中显著优于其他同规模开源模型,性能与Gemini-1.5 Flash相当,达到了GPT-4o-mini平均性能的90%以上。
- phi-3.5-Vision 在多项单图和多图基准测试中表现出色,其性能在同等规模的模型中极具竞争力,甚至在多个基准上超越了更大的模型。
- 长上下文与多语言:\(phi-3.5-mini\)和\(phi-3.5-MoE\)在多语言MMLU基准上相较\(phi-3-mini\)有显著提升。在长上下文任务RepoQA和RULER上,它们的表现也优于或持平于Llama-3.1-8B等模型。
方法优势与不足
- 优势: 实验充分验证了本文以数据为核心的策略的成功。通过精心构建训练数据,小模型可以在推理和语言理解等复杂任务上达到SOTA水平,这使得在手机等边缘设备上部署高性能AI成为可能。
- 表现平平或不佳的场景:
- 事实知识: 由于模型容量限制,phi-3-mini在需要大量事实记忆的任务上表现较差(如TriviaQA)。但此弱点可通过与搜索引擎结合(RAG)来弥补。
- 长上下文: 在128K上下文长度的RULER任务上,模型性能出现显著下降,表明当前的长上下文训练数据质量有待提高。
- 多语言: 尽管\(phi-3.5\)系列有所改进,但基础模型仍以英语为主。
- 固有局限: 与所有LLM一样,模型仍存在事实不准确(幻觉)、偏见、生成不当内容等风险,尽管通过安全对齐已大大缓解。
最终结论
Phi-3系列模型,特别是phi-3-mini,成功地证明了通过优化训练数据,可以构建出性能强大但参数量极小的语言模型。这一成果不仅挑战了“越大越好”的传统观念,也为在资源受限设备上实现高级AI能力开辟了新的道路,展示了“数据最优”范式的巨大潜力。
| 模型 | 参数 | MMLU (5-shot) | GSM-8K (8-shot) | HumanEval (0-shot) | MT Bench |
|---|---|---|---|---|---|
| phi-3-mini | 3.8B | 68.8 | 82.5 | 58.5 | 8.38 |
| phi-3-small | 7B | 75.7 | 89.6 | 61.0 | 8.70 |
| phi-3-medium | 14B | 78.0 | 91.0 | 62.2 | 8.91 |
| Mixtral | 8x7B | 70.5 | 64.7 | 37.8 | - |
| GPT-3.5 | - | 71.4 | 78.1 | 62.2 | 8.35 |
| Llama-3-In | 8B | 66.5 | 77.4 | 60.4 | - |