PLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations
-
ArXiv URL: http://arxiv.org/abs/2510.07784v1
-
作者: Lexi Baugher; Lichan Hong; Cristos Goodrow; Xinyang Yi; Su-Lin Wu; Nikhil Mehta; Ningren Han; Yilin Zheng; Ruining He; Yueqi Wang; 等14人
-
发布机构: Google DeepMind; YouTube
TL;DR
本文提出了一个名为 PLUM 的框架,旨在将预训练语言模型(LLM)应用于工业级生成式推荐任务,该框架通过语义ID(Semantic IDs)、领域持续预训练(CPT)和生成式微调三个阶段,实现了超越传统大规模嵌入模型的推荐效果和样本效率。
关键定义
- PLUM框架: 一个为工业级推荐系统设计的三阶段框架,用于适配预训练语言模型。它包括:1) 将物品转化为离散Token序列的语义ID(Semantic IDs);2) 在领域特定数据上进行持续预训练(Continued Pre-training, CPT);3) 针对推荐任务进行微调,尤其是生成式检索。
- 语义ID (Semantic IDs, SIDs): 将每个推荐物品(如视频)表示为一串离散的、分层的Token序列。与传统的单一ID嵌入不同,SIDs能够捕捉物品的多维度语义信息,使推荐模型能像处理语言一样处理物品。本文在已有方法基础上提出了SID-v2,融合了多模态特征和用户行为信号。
- 持续预训练 (Continued Pre-training, CPT): 在获得SID词表后,将一个通用的预训练LLM在包含SID和文本的领域特定数据(如用户观看历史、视频元数据)上继续进行预训练。此阶段旨在让模型理解SID与自然语言之间的关联,弥合通用LLM与推荐领域之间的知识鸿沟。
- 生成式检索 (Generative Retrieval): 一种新的推荐范式,将推荐任务重构为序列到序列的生成问题。模型被训练成根据用户上下文,自回归地直接生成推荐物品的SIDs序列,从而绕开了传统的基于点积相似度的检索方式。
相关工作
当前工业界主流的推荐系统严重依赖大规模嵌入模型(Large Embedding Models, LEMs),这些模型将绝大多数参数用于存储物品ID等高基数类别特征的嵌入表。这种架构虽然在记忆用户-物品交互方面很有效,但阻碍了更深、更复杂神经网络的应用,其扩展方式(增大嵌入表)与大语言模型(LLM)通过增加网络参数来学习紧凑输入Token组合的扩展路径截然不同。
LLM的成功启发了推荐系统领域的新范式,但直接应用通用LLM面临两大挑战:
- 领域鸿沟:LLM未在特定领域的用户行为数据和物品语料上预训练,难以理解用户偏好和物品的细微差别。
- 扩展瓶颈:传统的LEMs依赖巨大的嵌入表,训练成本高昂,难以支持大规模Transformer架构的训练。
本文旨在解决上述问题,提出PLUM框架,探索如何有效地将预训练LLM的能力迁移到工业级推荐任务中,并摆脱对大规模嵌入表的依赖。
本文方法
PLUM框架是一个包含三个核心阶段的系统,旨在将预训练LLM高效地适配于大规模生成式推荐。
语义ID (Semantic IDs)
本文方法的基础是将每个物品表示为一个称为语义ID(SID)的离散码字(codeword)元组。这基于一种改进的残差量化变分自编码器(Residual-Quantized Variational AutoEncoder, RQ-VAE)。相较于先前的工作,本文提出了SID-v2,包含以下几项关键创新:
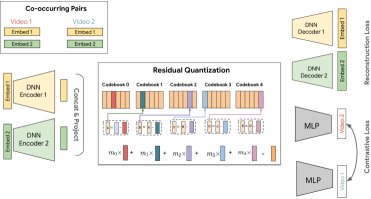
- 融合多模态内容表示: 为了全面理解物品,该模型并非依赖单一的内容表征,而是将来自不同模态(如文本元数据、视觉、音频)的多个嵌入向量${x_m}$融合。这些向量经过各自的编码器后被拼接并投影成一个统一的特征向量$z$,作为RQ-VAE的输入。
- 分层量化精炼:
- 多分辨率码本: 采用可变分辨率的码本结构,即SID的初始层级具有高分辨率(更多码字)以实现最大区分度,而后续层级则用较低分辨率编码残差信息。这使得SID表示更紧凑高效。
- 渐进式掩码 (Progressive Masking): 在训练中,通过一个随机掩码$m_l$随机选择SID的前$r$个层级进行训练,这强制模型学习到一个更严格、更有意义的层次结构。
-
基于共现的对比正则化: 为了让SID能反映用户感知的相似性,本文在RQ-VAE的训练目标中加入了一项共现对比损失$\mathcal{L}_{con}$。该损失函数鼓励在用户观看序列中频繁共同出现的视频产生相似的SID表示,从而将协同过滤信号注入到SID的生成过程中。损失函数定义如下:
\[\mathcal{L}_{con}=-\sum_{i=1}^{2N_{b}}\frac{\exp(\text{sim}(p_{i},p_{i}^{+}))}{\sum_{j=1}^{2N_{b}}\exp(\text{sim}(p_{i},p_{j}))}\]其中$p_i$是批次中的一个视频表示,$p_i^+$是与视频$i$共现的视频表示。
-
SID总体训练损失: 最终的SID模型训练损失为重建损失、量化损失和对比损失之和:
\[\mathcal{L}=\mathcal{L}_{recon}+\mathcal{L}_{rq}+\mathcal{L}_{con}\]
持续预训练 (Continued Pre-training)
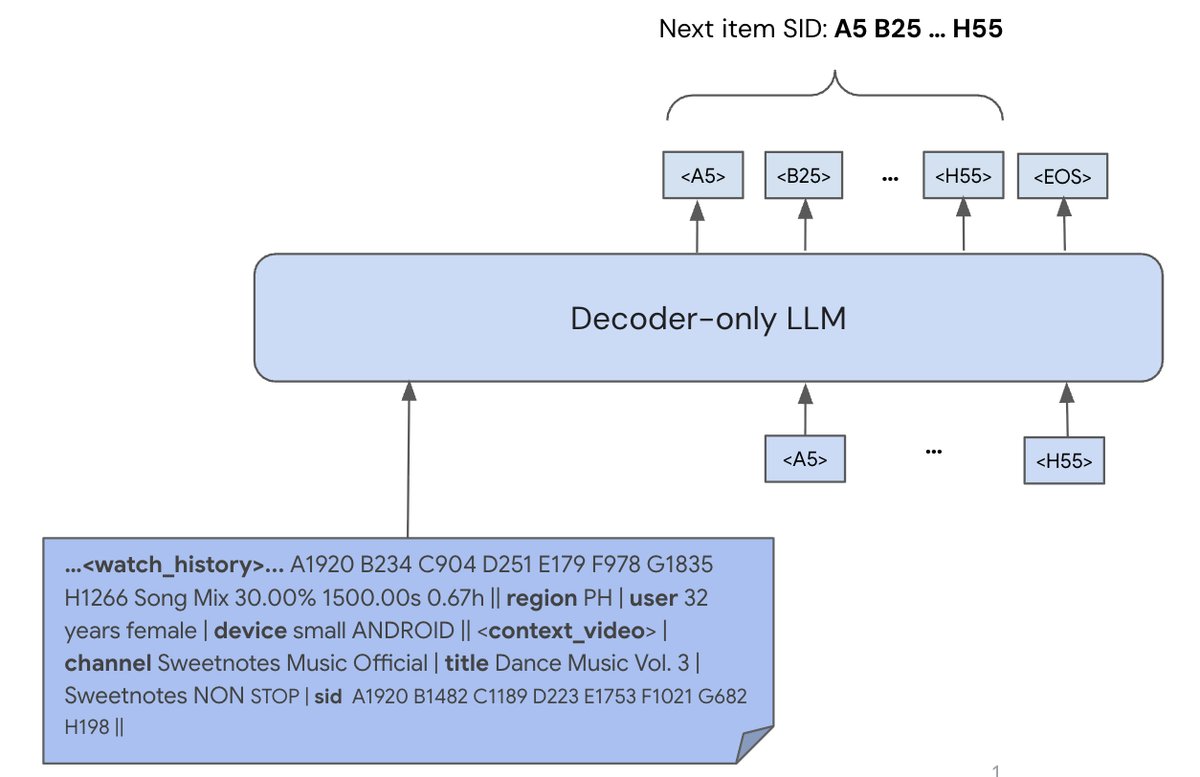
在生成SID词表后,CPT阶段的目标是将SID作为一种新的模态与LLM已有的文本知识对齐。为此,模型在一个混合语料库上进行下一Token预测的训练。该语料库由两部分构成,各占50%:
- 用户行为序列: 包含用户观看历史和相关特征,用于模型学习个性化和序列模式。
- 视频元数据: 包含视频的SID及其对应的文本信息(标题、描述、字幕等),旨在建立SID和其文本含义之间的强关联。
通过CPT,模型不仅学会了根据用户历史生成SID,还保留了生成自由格式文本的能力,并展现出了一定的上下文少样本学习(in-context few-shot learning)能力。
生成式检索 (Generative Retrieval)
CPT之后的模型需要通过监督微调(Supervised Fine-Tuning, SFT)来针对具体的检索任务进行优化。此阶段模型会学习结合更丰富的实时上下文特征,并直接针对与用户体验相关的奖励信号进行优化。
微调采用标准的自回归最大似然目标,模型学习预测用户点击视频的SID。损失函数如下:
\[\mathcal{L}_{\text{SFT}}=-\sum_{t=1}^{L}r(\text{user},v_{click})\cdot\log P(\text{sid}_{t} \mid \text{Context}_{\text{user}},\text{History}_{\text{user}},\text{sid}_{<t})\]其中$[sid_1,..,sid_L]$是被点击视频$v_{click}$的SID序列,$r(\text{user}, v_{click})$是根据点击行为设计的奖励信号。在推理阶段,使用束搜索(beam search)解码生成多个候选SID序列,这些SID最终映射到视频库中成为推荐结果。
实验结论
本文通过一系列离线和在线实验,验证了PLUM框架的有效性。
- 与生产模型的对比:
- 与YouTube生产环境中高度优化的Transformer基大规模嵌入模型(LEM)相比,PLUM模型(900M MoE)在长视频和短视频推荐上均取得了显著更大的有效词汇量(分别为2.60倍和13.24倍),这意味着它能推荐更多样化和新颖的内容。
- 在线A/B实验表明,将PLUM模型加入候选池后,关键指标如活跃用户数、面板点击率、观看量和满意度均有显著提升(例如,在短视频上,面板CTR提升了+4.96%)。
LEM与PLUM模型线下指标对比 (900M MoE模型/LEM模型)
指标 长视频 (LFV) 短视频 (Shorts) 有效词汇量 $2.60\text{x}$ $13.24\text{x}$ 点击率 (CTR) $1.42\text{x}$ $1.33\text{x}$ 平均观看时长 (WT/View) $0.72\text{x}$ $1.13\text{x}$ 平均观看比例 (WF/View) $1.32\text{x}$ $1.03\text{x}$ 在线实验指标提升 (相较于LEM+基线)
指标 长视频 (LFV) 短视频 (Shorts) 活跃用户数 $+0.07\%$ $+0.28\%$ 面板点击率 $+0.76\%$ $+4.96\%$ 观看量 $+0.80\%$ $+0.39\%$ 满意度 $+0.06\%$ $+0.39\%$ -
样本效率:PLUM模型表现出极高的样本效率。900M MoE模型每天仅需约2.5亿样本进行训练,而LEM需要数十亿样本。由于收敛速度更快,PLUM模型的总训练成本(FLOPs)不到LEM的0.55倍。
-
SID消融研究:对SIDv2的各项改进进行的消融实验表明,融合多模态特征、多分辨率码本、渐进式掩码和共现对比损失等所有改进均能提升SID的唯一性和下游生成式检索的召回率。其中,共现对齐任务的引入对性能提升尤为显著。
SIDv2改进消融实验
模型 索引唯一性 (%) 视频召回率@10 SIDv1 82.5% 1.83% + 多分辨率码本 82.6% 1.94% + 渐进式掩码 82.6% 2.05% + 多模态融合 82.7% 2.50% + 部分共现对齐 90.7% 3.65% SIDv2 (完整) 91.8% 4.14% - 持续预训练 (CPT) 的影响:
- CPT至关重要:有CPT阶段的模型在最终的检索任务上表现远超没有CPT的模型,并且收敛速度快得多(如下图所示),证明了CPT在提升训练效率和最终性能上的巨大价值。
- 预训练LLM的价值:从预训练LLM(Gemini) checkpoint初始化的模型始终优于从随机权重开始训练的模型,这表明LLM通过大规模预训练学到的通用序列处理能力可以直接迁移并有益于推荐任务。
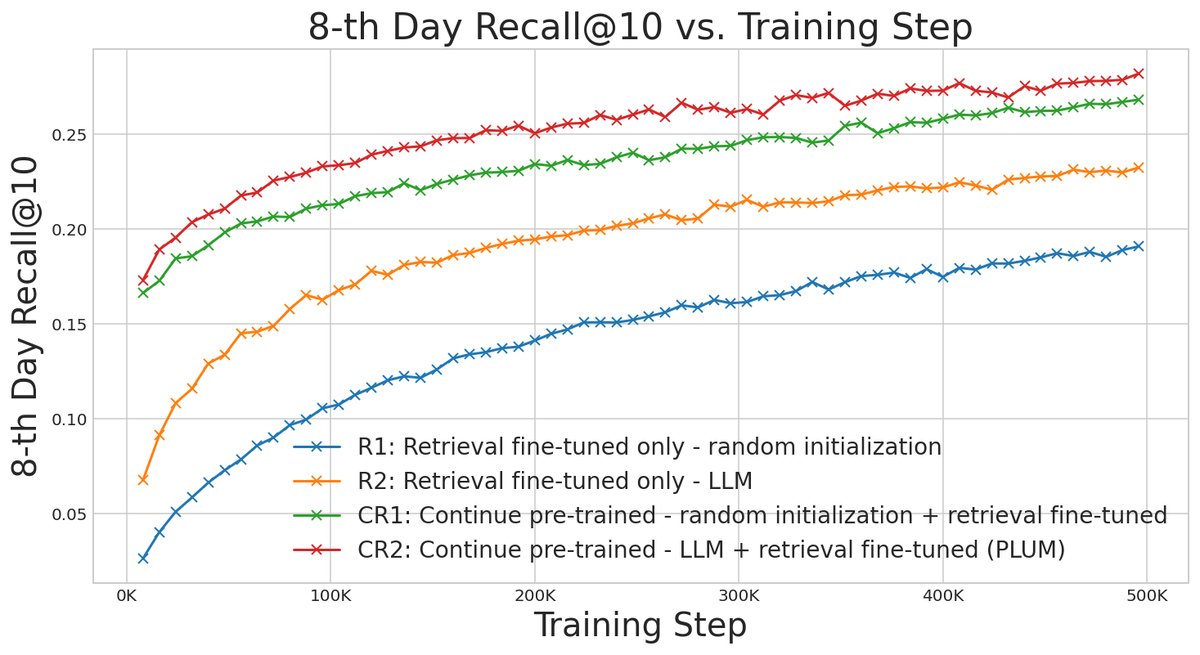
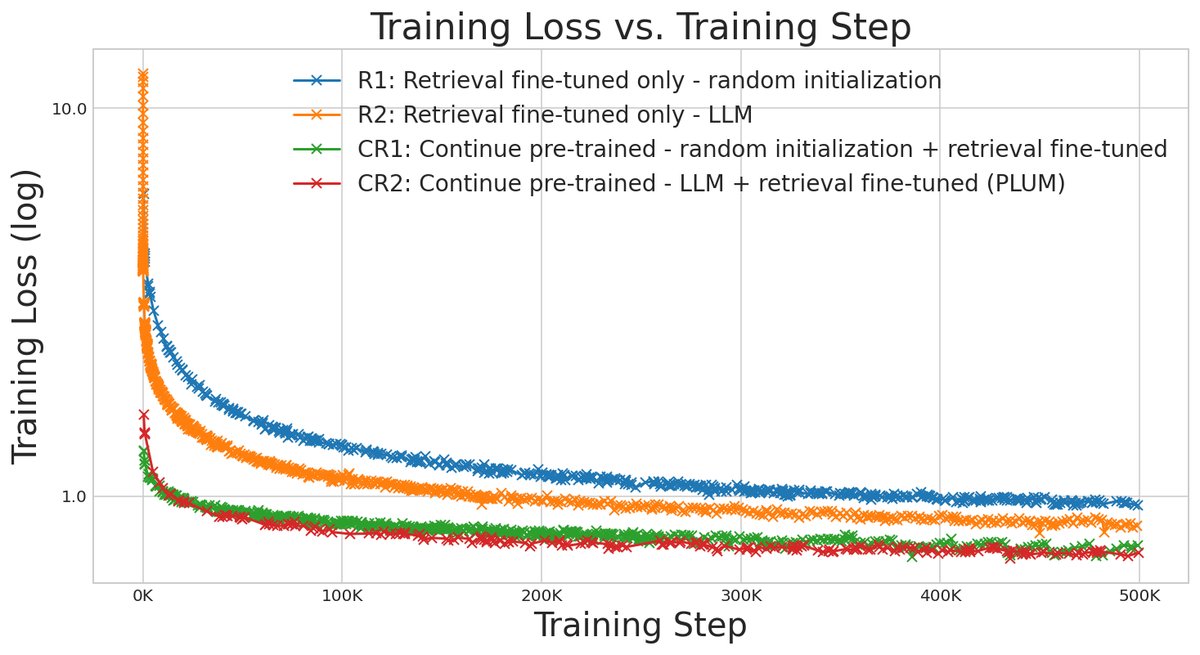
CPT消融实验主要结果 (Recall@10)
模型简称 模型配置 CPT? 预训练LLM? 性能 (相对值) R1 随机初始化 + Fine-tuning 否 否 1.00x R2 LLM初始化 + Fine-tuning 否 是 1.15x CR1 随机初始化 + CPT + Fine-tuning 是 否 1.25x CR2 (PLUM) LLM初始化 + CPT + Fine-tuning 是 是 1.35x - 最终结论:PLUM框架成功地将预训练LLM适配到工业级生成式推荐中,通过SID、CPT和生成式微调,不仅在推荐质量上超越了高度优化的基线系统,还大幅提升了训练的样本效率和计算效率,为构建下一代推荐系统提供了有效路径。