Process-Supervised Reinforcement Learning for Interactive Multimodal Tool-Use Agents
-
ArXiv URL: http://arxiv.org/abs/2509.14480v1
-
作者: Philipp Koehn; Weiting Tan; Xinghua Qu; Meng Ge; Ming Tu; Andy T. Liu; Lu Lu
-
发布机构: ByteDance; Johns Hopkins University
TL;DR
本文提出了一种名为“回合级评审强化学习” (Turn-level Adjudicated Reinforcement Learning, TARL) 的流程监督方法,该方法利用大型语言模型 (LLM) 作为裁判提供细粒度的回合级奖励,并结合混合任务训练策略,以解决长程交互中的信用分配和探索不足问题,从而显著提升了交互式多模态工具使用智能体的任务成功率。
关键定义
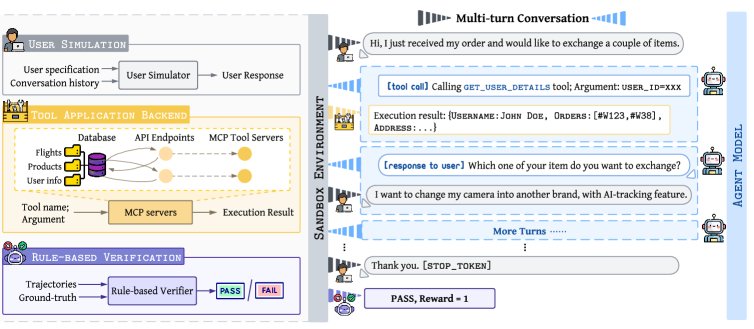
本文的核心方法和概念建立在一个为强化学习设计的沙盒环境之上。
- 沙盒环境 (Sandbox Environment):一个专为训练交互式工具使用智能体而设计的模拟环境。它包含一个带API的后端应用、一个模拟真实用户(支持文本和语音)的LLM用户模拟器,以及一个基于规则的验证器,用于评估智能体的行为并提供最终任务奖励。
- 回合级评审强化学习 (Turn-level Adjudicated Reinforcement Learning, TARL):本文提出的核心方法。它引入一个LLM作为“裁判”,在多回合交互的复杂任务中,对智能体的每一个“回合”(包括推理和工具调用)进行评估并给予即时奖励(-1, 0, 或 1)。这种细粒度的奖励机制旨在解决传统强化学习在长程任务中面临的信用分配难题。
- 混合任务训练 (Mixed-Task Training):一种训练策略,在工具使用任务的训练过程中穿插中等难度的数学推理问题。其目的是利用数学问题求解中自然产生的自我反思和探索行为,来正则化训练过程,防止智能体在特定任务上过拟合,并维持其探索能力。
相关工作
当前,让大型语言模型(LLM)与外部工具和服务交互是AI智能体领域的前沿方向。然而,训练这类智能体,尤其是在需要多回合对话、长上下文管理的交互式场景中,面临巨大挑战。
现有方法大多依赖静态的、预先收集的轨迹数据进行监督学习,但这难以应对真实世界交互的动态性和多变性。强化学习(RL)提供了一种在线学习的范式,让智能体能通过与环境的动态交互来优化策略,但标准RL算法在工具使用这类长程任务中也存在瓶颈:
- 信用分配问题 (Credit Assignment Problem):在一次包含数十个步骤的多回合交互后,仅根据最终任务是否成功给予一个稀疏的奖励信号,很难判断出究竟是哪个或哪些步骤导致了最终的成功或失败,这使得学习效率低下。
- 探索能力下降 (Reduced Exploration):随着训练进行,模型往往变得“过度自信”,倾向于重复已知的成功路径,减少了对新策略的探索,从而陷入局部最优,难以发现更优的解决方案。
本文旨在解决上述两个核心问题,即如何在复杂的、多回合的交互式工具使用任务中,实现有效的信用分配和持续的探索,特别是在处理包含文本和语音的多模态交互时。
本文方法
本文提出了一套完整的、基于强化学习的训练框架,用于开发交互式多模态工具使用智能体。该框架的核心是创新的训练策略,旨在解决探索不足和信用分配两大难题。
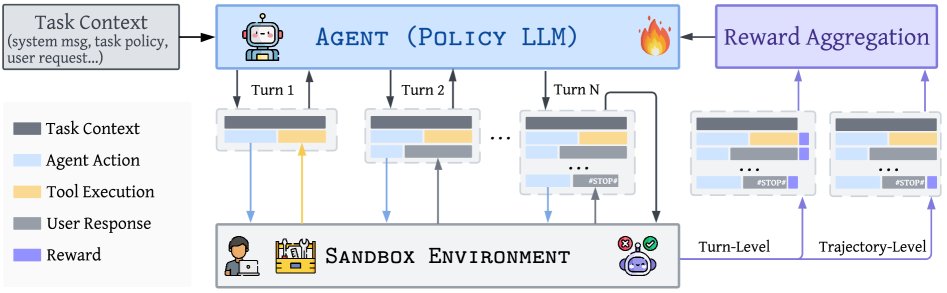 上图概述了交互式工具使用智能体的训练流程。智能体在沙盒环境中运行,接收工具执行结果和用户反馈。然后,单个回合和完整轨迹都会被评估和打分,生成用于更新智能体的奖励信号。
上图概述了交互式工具使用智能体的训练流程。智能体在沙盒环境中运行,接收工具执行结果和用户反馈。然后,单个回合和完整轨迹都会被评估和打分,生成用于更新智能体的奖励信号。
框架与公式
本文将交互式工具使用任务形式化为一个马尔可夫决策过程 (Markov Decision Process, MDP)。智能体的策略由一个自回归语言模型 $p_{\theta}$ 构成。整个交互过程 $\mathbf{\tau}$ 由智能体生成的Token序列 $\mathbf{x}^{i}$ 和环境反馈的Token序列 $\mathbf{e}^{i}$ 交错组成:$\mathbf{\tau}=(\mathbf{x}^{1},\mathbf{e}^{1},\mathbf{x}^{2},\mathbf{e}^{2},\ldots,\mathbf{x}^{T},\mathbf{e}^{T})$。训练目标是最大化完整轨迹的期望奖励:
\[J(\theta)=\mathbb{E}_{\mathbf{\tau}\sim p_{\theta}}[R(\mathbf{\tau})]\]在此基础上,本文对比了多种RL算法,如PPO、GRPO和SPO,并最终选择将新方法与表现优异的GRPO和PPO相结合。
创新点
本文的创新主要体现在两个相互补充的训练策略上:混合任务训练和回合级评审强化学习(TARL)。
混合任务训练
为了解决智能体在训练中探索能力下降的问题,本文引入了混合任务训练策略。该策略在常规的工具使用任务训练中,交替插入中等难度的数学问题(来自DeepScaleR数据集)。
- 优点:
- 促进探索:解决数学问题需要模型进行更长的思考链 (Chain-of-Thought, CoT) 和频繁的自我修正,这种行为模式天然地促进了探索。
- 正则化:混合不同类型的任务可以防止模型对单一的工具使用领域(如零售)过拟合,从而保留其通用的推理和反思能力。
回合级评审强化学习 (TARL)
为了解决长程任务中的信用分配难题,本文设计了TARL方法,其核心是引入一个LLM裁判(GPT-4.1)来提供细粒度的过程监督。
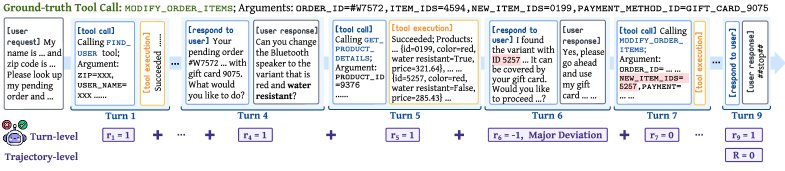
- 设计:
- 回合级评分:在一次完整的交互结束后,LLM裁判会回顾整个对话历史和真实标注,对智能体的每一个回合(agent的思考和行动)进行评分。评分分为三档:
- \(+1\): 行为正确。
- \(0\): 存在小问题但后续得到纠正,或是由之前的重大错误导致的连锁反应。
- \(-1\): 出现重大偏差,如提供了错误信息或执行了不可逆的错误操作(例如,错误地取消了不该取消的订单)。每条轨迹最多只能有一个\(-1\)分。
- 奖励整合:将回合级奖励 $r_i$ 与最终由规则验证器给出的任务级二进制奖励 $R(\mathbf{\tau})$ 进行加权组合。
- 任务成功奖励 $R(\mathbf{\tau})=1$ 被放大为 \(10\) 分。
- 重大错误(-1分)被放大为 \(-5\) 分。
- 其他回合级奖励按 $\frac{1}{T}$ 缩放,总和上限为 \(5\) 分。
- 回合级评分:在一次完整的交互结束后,LLM裁判会回顾整个对话历史和真实标注,对智能体的每一个回合(agent的思考和行动)进行评分。评分分为三档:
- 优点:
- 精细化信用分配:通过这种奖励设计,轨迹被清晰地分为四类(完美成功、有瑕疵成功、无重大错误的失败、有重大错误的失败),为模型更新提供了比单一最终奖励更丰富、更精确的梯度信号。
- 强调关键错误:通过对重大错误施加重罚,该方法能有效指导模型避免犯下不可逆转的错误。
- 实现简单有效:相比于复杂的逐个Token奖励或实时干预,这种在轨迹结束后进行整体评估和奖励分配的方式,被证明在训练中更加稳定和高效。
实验结论
本文通过在文本和多模态两个场景下的实验,全面验证了所提出方法的有效性。
文本智能体实验
- 设置:使用Qwen3-8B作为基础模型,在基于APIGEN-MT合成的约3000个任务上进行训练。
- 关键结果:
- 与强大的RL基线(如GRPO)相比,结合了混合任务训练和TARL的策略 (Math+TARL) 在 \(pass^1\) 指标上取得了超过 \(6%\) 的相对提升,任务成功率达到 \(57.4%\),性能接近闭源的GPT-4.1模型。
- 在所有\(pass^k\)指标上都观察到了一致的性能提升,表明模型的可靠性增强。
- 定性分析显示,经过新方法训练的模型表现出更频繁的自我纠正行为(“wait” Token数量增加)和更长的响应长度,表明其探索和反思能力得到增强。
| 方法 | Avg. waits | Avg. len. | pass^1 | pass^2 | pass^3 | pass^4 |
|---|---|---|---|---|---|---|
| Qwen3-8B | 1.83 | 2919.1 | 42.1 | 24.3 | 16.2 | 11.2 |
| RL Baselines | ||||||
| SPO | 1.63 | 2838.4 | 45.4 | 26.5 | 18.0 | 12.5 |
| PPO | 1.48 | 2781.9 | 49.3 | 29.8 | 19.8 | 14.1 |
| GRPO | 1.51 | 2810.1 | 51.2 | 30.7 | 20.9 | 15.3 |
| 本文方法 | ||||||
| Math | 1.95 | 2992.3 | 51.5 | 31.0 | 21.0 | 15.8 |
| GRPO + TARL | 1.86 | 2933.2 | 55.4 | 33.7 | 23.4 | 17.1 |
| Math + TARL | 2.21 | 3102.5 | 57.4 | 35.1 | 24.1 | 17.9 |
多模态智能体实验
- 设置:使用Qwen2.5-Omni-7B作为基础模型,该模型能同时处理语音和文本。训练数据包含文本任务、数学问题和带有语音用户输入的任务。由于基础模型初始能力较弱,采用了课程学习进行预热。
- 关键结果:
- 相较于基础模型,使用本文方法(Math+TARL)训练后的多模态智能体在 \(pass^1\) 指标上的性能提升超过 \(20%\),证明了该框架在多模态场景下的有效性。
- 混合模态训练至关重要:消融实验表明,如果只在纯文本数据上对多模态模型进行微调,其原有的语音理解能力会退化,导致在处理语音输入时性能下降。这凸显了在训练中包含语音-文本交错的混合模态数据对于开发语音智能体的必要性。
| 训练 | 评估 | Avg. waits | Avg. len. | pass^1 | pass^2 | pass^3 | pass^4 |
|---|---|---|---|---|---|---|---|
| - | 文本 | 1.05 | 2404.1 | 7.8 | 1.5 | 0.4 | 0.0 |
| S-T | 文本 | 1.43 | 2623.1 | 28.5 | 11.2 | 5.1 | 2.5 |
| S-T | 语音 | 1.45 | 2689.9 | 28.1 | 10.8 | 4.8 | 2.2 |
| T-only | 语音 | 1.29 | 2501.0 | 25.3 | 9.2 | 3.9 | 1.6 |
分析与总结
- 简单有效:分析表明,相较于在损失函数中加入熵约束或通过实时干预强制模型反思等复杂技术,本文提出的“混合任务训练 + TARL”这种更简单、更宏观的策略,在稳定训练的同时取得了更好的效果。这与Sutton的“苦涩的教训 (bitter lesson)”思想相呼应,即利用通用和可扩展的方法(如利用LLM裁判进行评估)通常优于复杂的手工设计。
- 最终结论:本文成功开发并验证了一个用于训练交互式工具使用智能体的强化学习框架。通过结合混合任务训练以促进探索,以及TARL以实现精细化的信用分配,该方法在文本和多模态(语音-文本)场景下均取得了显著的性能提升,为构建更自然、更强大的语音交互智能体铺平了道路。