QLoRA: Efficient Finetuning of Quantized LLMs
-
ArXiv URL: http://arxiv.org/abs/2305.14314v1
-
作者: Ari Holtzman; Tim Dettmers; Artidoro Pagnoni; Luke Zettlemoyer
-
发布机构: University of Washington
TL;DR
本文提出了一种名为QLoRA的高效微调方法,通过将梯度反向传播到冻结的4-bit量化模型中的低秩适配器(LoRA),首次实现了在单个48GB GPU上微调65B参数的大型语言模型,同时保持了与16-bit全量微调相当的性能。
关键定义
本文提出或使用了以下几个核心概念:
-
QLoRA (Quantized Low-Rank Adaptation): 一种高效的微调技术。其核心思想是:将预训练模型的权重冻结并量化为4-bit精度,然后通过这些量化权重反向传播梯度,来仅更新一小组可训练的低秩适配器(LoRA)参数。这种方法在大幅降低显存占用的同时,保留了模型的完整性能。
-
4-bit NormalFloat (NF4): 一种新提出的4-bit数据类型。理论上,对于呈正态分布的数据(如神经网络的权重),NF4是信息论最优的数据类型。它通过预先计算标准正态分布的分位数来构建,确保每个量化区间内有相同数量的数值,从而比传统的4-bit整数(Int4)或浮点数(FP4)量化有更高的精度。
-
双重量化 (Double Quantization, DQ): 一种进一步压缩模型内存占用的技术。它对第一次量化操作产生的“量化常数”(quantization constants)本身进行再量化。具体来说,用一个内存开销更低的8-bit浮点数来表示原本是32-bit的量化常数,从而平均每个参数可节省约0.37比特。
-
分页优化器 (Paged Optimizers): 一种利用NVIDIA统一内存(Unified Memory)特性来防止内存峰值导致训练中断的技术。当GPU显存不足时,该技术能自动地将优化器状态(optimizer states)从GPU显存“分页”到CPU内存,并在需要时再调回GPU,从而使大模型在处理长序列时也能稳定训练。
相关工作
-
研究现状与瓶颈: 微调大型语言模型(LLMs)是提升其性能和特定能力的有效途径。然而,标准的16-bit全精度微调对硬件要求极高,例如,微调一个65B的LLaMA模型需要超过780GB的GPU显存,这对于绝大多数研究者和开发者来说是无法承受的。虽然现有的量化方法可以显著降低模型在推理(inference)时的内存占用,但这些方法在训练(training)过程中会导致性能严重下降,无法直接应用。
-
本文旨在解决的问题: 本文旨在解决大模型微调过程中巨大的显存消耗问题,使得在单张消费级或专业级GPU上微调超大规模的语言模型(如65B)成为可能,并且在效率提升的同时不牺牲模型最终的性能。
本文方法
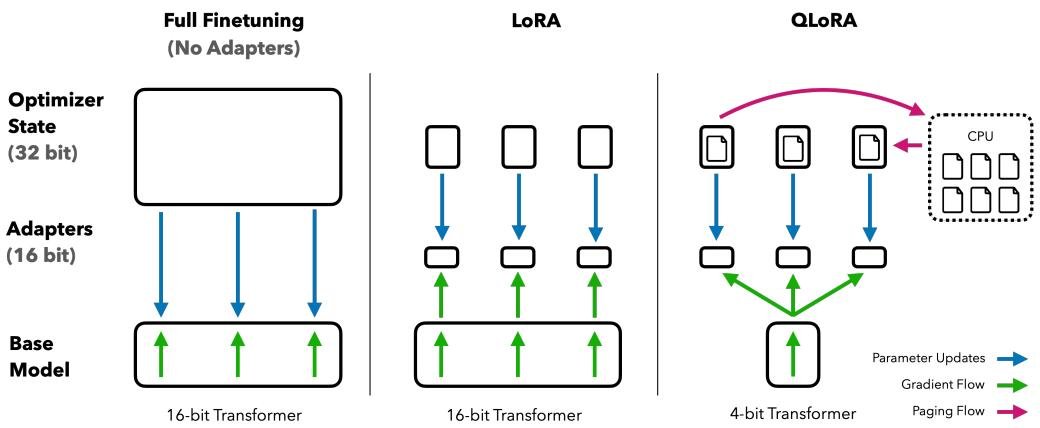
QLoRA的核心思想是将一个预训练的LLM冻结并量化到4-bit,然后通过反向传播梯度到一组外加的、小规模的低秩适配器(LoRA)来进行微调。QLoRA只有一个低精度存储数据类型(通常是4-bit NF4)和一个计算数据类型(通常是BFloat16)。当使用权重时,模型会动态地将4-bit权重反量化到16-bit进行前向和后向传播计算,但梯度只用于更新16-bit的LoRA参数,而冻结的4-bit基础模型权重保持不变。
QLoRA的完整计算过程可以表示为:
\[\mathbf{Y}^{\text{BF16}} = \mathbf{X}^{\text{BF16}} \text{doubleDequant}(c_1^{\text{FP32}}, c_2^{\text{k-bit}}, \mathbf{W}^{\text{NF4}}) + \mathbf{X}^{\text{BF16}} \mathbf{L}_1^{\text{BF16}} \mathbf{L}_2^{\text{BF16}}\]其中,\(doubleDequant\)代表双重反量化过程,它将4-bit的基础模型权重 \(W\) 恢复为\(BFloat16\)格式参与计算,而 \(L1\) 和 \(L2\) 是可训练的LoRA适配器权重。
创新点
4-bit NormalFloat (NF4)
标准的量化方法对权重中的异常值非常敏感,而信息论上更优的分位数分箱(Quantile Quantization)方法计算成本高昂。NF4利用了神经网络权重通常呈零中心正态分布的先验知识。 它通过以下步骤构建:
- 为一个理论上的标准正态分布\(N(0, 1)\)估算\(2^k + 1\)个分位数点。
- 将这些分位数点归一化到\([-1, 1]\)的范围内,形成一个k-bit的数据类型。
- 在量化时,通过绝对值最大缩放(absolute maximum rescaling)将输入权重张量也归一化到 \([-1, 1]\) 范围,然后进行量化。 这种方法避免了在运行时估计分位数的昂贵开销,并为正态分布数据提供了最优的量化精度。为了保证0可以被精确表示,NF4被设计为非对称的,从而充分利用了所有\(2^k\)个比特位。
双重量化 (Double Quantization)
块状量化虽然提高了精度,但也带来了额外的内存开销,因为每个块都需要一个量化常数(通常是32-bit)。例如,对于64的块大小,量化常数会带来\(32/64 = 0.5\)比特/参数的额外开销。 双重量化通过对量化常数本身进行二次量化来解决这个问题:
- 第一次量化: 正常量化模型权重,得到4-bit权重和一系列32-bit的量化常数\(c_2^{FP32}\)。
- 第二次量化: 将这组\(c_2^{FP32}\)作为输入,再次进行量化,得到8-bit的量化常数\(c_2^{FP8}\)和一个新的、更小尺寸的32-bit量化常数\(c_1^{FP32}\)。 通过这种方式,平均每个参数的内存开销从0.5比特降低到约0.127比特,对于65B模型,可节省大约3GB显存。
分页优化器 (Paged Optimizers)
梯度检查点(gradient checkpointing)技术虽然能节省显存,但在处理包含长序列的小批量数据时,仍可能出现临时的内存峰值,导致训练因显存溢出(OOM)而中断。 分页优化器利用NVIDIA的统一内存特性,将优化器状态(如Adam中的动量和方差)分配在“可分页”的CPU内存中。当GPU显存紧张时,这些数据会自动被交换到CPU RAM;当优化器更新步骤需要它们时,再被加载回GPU。这套机制像操作系统中的虚拟内存一样工作,有效避免了因内存峰值导致的训练失败。
实验结论
本文通过广泛的实验证明了QLoRA的有效性和优越性。
QLoRA与全精度微调的性能对比
- 性能匹配: 实验结果一致表明,4-bit QLoRA(使用NF4数据类型)在多个学术基准(GLUE, Super-NaturalInstructions, MMLU)上,能够完全匹配16-bit全量微调和16-bit LoRA微调的性能。无论是在RoBERTa、T5等中小型模型还是在7B到65B的LLaMA系列大模型上,这一结论都成立。
| 数据集 | GLUE (Acc.) | Super-NaturalInstructions (RougeL) | ||||
|---|---|---|---|---|---|---|
| 模型 | RoBERTa-large | T5-80M | T5-250M | T5-780M | T5-3B | T5-11B |
| BF16 (全量微调) | 88.6 | 40.1 | 42.1 | 48.0 | 54.3 | 62.0 |
| LoRA BF16 | 88.8 | 40.5 | 42.6 | 47.1 | 55.4 | 60.7 |
| QLORA NF4 + DQ | - | 40.4 | 42.7 | 47.7 | 55.3 | 60.9 |
| LLaMA Size | 7B | 13B | 33B | 65B | 平均 | ||||
|---|---|---|---|---|---|---|---|---|---|
| 数据集 | Alpaca | FLAN v2 | Alpaca | FLAN v2 | Alpaca | FLAN v2 | Alpaca | FLAN v2 | |
| BFloat16 | 38.4 | 45.6 | 47.2 | 50.6 | 57.7 | 60.5 | 61.8 | 62.5 | 53.0 |
| NFloat4 + DQ | 39.0 | 44.5 | 47.5 | 50.7 | 57.3 | 59.2 | 61.8 | 63.9 | 53.1 |
- 关键组件的有效性:
- NF4优于FP4: 实验证明,NF4数据类型显著优于标准的4-bit浮点数(FP4),在各项评估中都取得了更好的结果。
- 双重量化无损: 双重量化在不降低模型性能的前提下,有效减少了内存占用。
- LoRA应用范围: 实验发现,将LoRA应用到Transformer模型中的所有线性层是匹配全量微调性能的关键,而不仅仅是像传统做法那样只应用在注意力机制的查询(query)和值(value)矩阵上。

Guanaco:基于QLoRA的SOTA聊天机器人
- 顶尖性能: 本文使用QLoRA在OASST1(一个高质量、开源的指令数据集)上训练了一系列名为Guanaco的模型。其中,Guanaco 65B在Vicuna基准测试中达到了ChatGPT 99.3%的性能水平,成为当时表现最好的开源聊天模型。Guanaco 33B仅需21GB显存,性能却优于需要26GB显存的Vicuna-13B。
| 模型 | 大小 | Elo评分 |
|---|---|---|
| GPT-4 | - | 1348 ± 1 |
| Guanaco 65B | 41 GB | 1022 ± 1 |
| Guanaco 33B | 21 GB | 992 ± 1 |
| Vicuna 13B | 26 GB | 974 ± 1 |
| ChatGPT | - | 966 ± 1 |
| Guanaco 7B | 6 GB | 879 ± 1 |
- 训练效率: Guanaco 33B模型可以在一块24GB的消费级GPU上于12小时内完成训练,极大地降低了SOTA级别模型研究和开发的门槛。
- 数据集与评估的启示:
- 数据质量 > 数量: 一个小规模但高质量的数据集(如9k样本的OASST1)训练出的模型,其聊天性能远超基于大规模数据集(如450k样本的FLAN v2)训练的模型。
- 评测基准的局限性: MMLU基准上的高分不代表在聊天对话基准(如Vicuna)上的高分,反之亦然。这表明不同基准测试的是模型不同的能力维度。
- 模型评估方法: GPT-4作为裁判是一种廉价且合理的评估选项,但与人类偏好存在一定差异。相比绝对评分,基于两两对比的Elo评分系统是更可靠的排名方法。
最终结论
QLoRA是一种极其高效且不牺牲性能的微调方法,它使得在单个GPU上微调超大规模语言模型成为现实。实验证明,4-bit的QLoRA微调可以完全复现16-bit全量微调的性能。基于QLoRA训练的Guanaco模型系列,在仅使用开源数据的情况下,达到了与顶尖商业模型(如ChatGPT)相媲美的SOTA性能,这为未来在特定领域通过高质量开源数据训练专用模型开辟了广阔前景。