Quagmires in SFT-RL Post-Training: When High SFT Scores Mislead and What to Use Instead
-
ArXiv URL: http://arxiv.org/abs/2510.01624v1
-
作者: Carole-Jean Wu; Ruoxi Jia; Feiyang Kang; Marin Vlastelica; Karthik Padthe; Michael Kuchnik; Newsha Ardalani
-
发布机构: Meta; Virginia Tech
TL;DR
本文挑战了“高SFT分数能带来更好RL效果”的普遍假设,通过实验证明SFT分数具有误导性,并提出使用“泛化损失”和“Pass@large k”作为更可靠的RL后性能预测指标。
关键定义
本文沿用了领域内的一些关键定义,并在此基础上提出了新的评估思路。
- SFT-then-RL 范式: 指一种主流的大语言模型(LLM)推理能力后训练(Post-training)流程。该流程分为两个独立阶段:首先进行监督微调(Supervised Fine-Tuning, SFT),然后使用带可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR 或简称 RL)进行优化。SFT作为“冷启动”阶段,为模型提供高质量的推理链示例;RL则进一步探索解空间,提升模型的推理和解决问题的能力。
- 泛化损失 (Generalization Loss): 本文提出的关键预测指标之一。它指 SFT 训练后,模型在未见过的、留出的验证推理样本集上的损失值。本文发现,该损失值的变化趋势(尤其是在过拟合时)能有效预测模型在后续 RL 阶段的性能潜力。
- Pass@k: 一种评估指标,衡量模型在生成 $k$ 个独立的解决方案中,至少有一个是正确的概率。本文特别关注大 $k$ 值下的 Pass@k 性能(Pass@large k),认为它能更精细地捕捉模型的内在解题能力和探索潜力,从而更好地预测 RL 后的最终性能。
相关工作
当前,针对推理大模型的后训练,主流实践是采用SFT和RL的序贯流程(SFT-then-RL)。研究界普遍认为,SFT对于后续的RL是必要的,并且在SFT阶段表现更好的模型,在RL后也会取得更强的性能。因此,大量研究工作聚焦于如何通过更复杂的数据筛选和策划策略(如筛选复杂度、多样性、生成合成数据等)来最大化SFT阶段的评估分数。
然而,这一领域的认知存在不一致甚至矛盾之处,例如有观点认为“过度SFT会限制RL效果”,甚至“无SFT的RL效果更好”。这种对后训练动态,特别是SFT作用的不确定性,构成了研究和应用的主要障碍。
本文旨在解决的核心问题是:SFT阶段的性能指标(如准确率)与最终RL阶段后的模型性能之间缺乏可靠的预测性。这种脱节导致SFT的优化目标与模型的最终目标不一致,使得SFT团队可能为RL阶段提供了次优的模型,不仅阻碍了整个后训练流程的优化,也降低了开发效率。本文的目标是提供新的评估工具,以更准确地预测RL结果,从而优化SFT-then-RL流程。
本文方法
本文的核心方法论分为两部分:首先,通过实验揭示当前依赖SFT分数进行评估的“指标陷阱”;然后,提出并验证了两个新的、更可靠的预测指标。
SFT指标陷阱
作者通过实验证明,普遍用于评估SFT效果的指标(如Pass@1准确率)并不能可靠地预测模型在经过RL训练后的最终性能。高SFT分数往往具有误导性,可能偏向于更简单或更同质化的数据。本文从两个典型场景揭示了这种脱节现象。
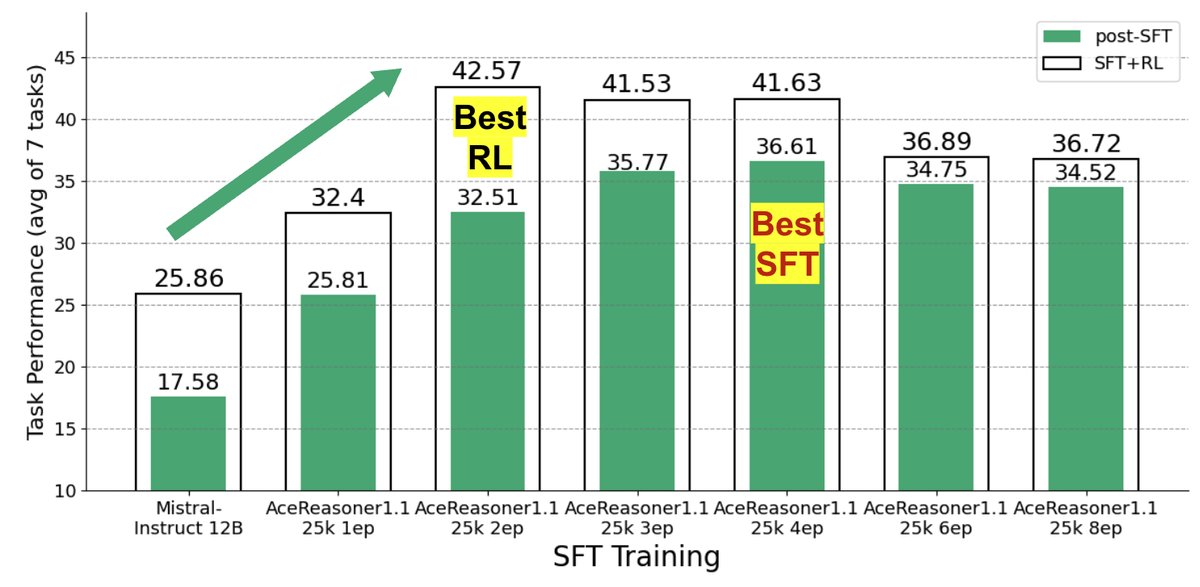
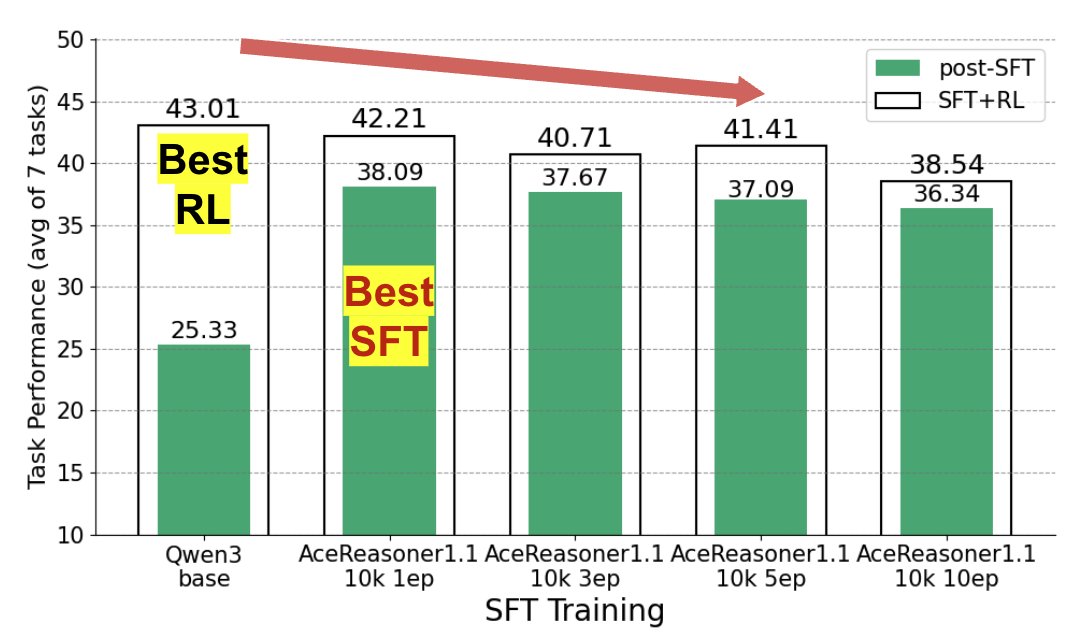
数据集层面场景
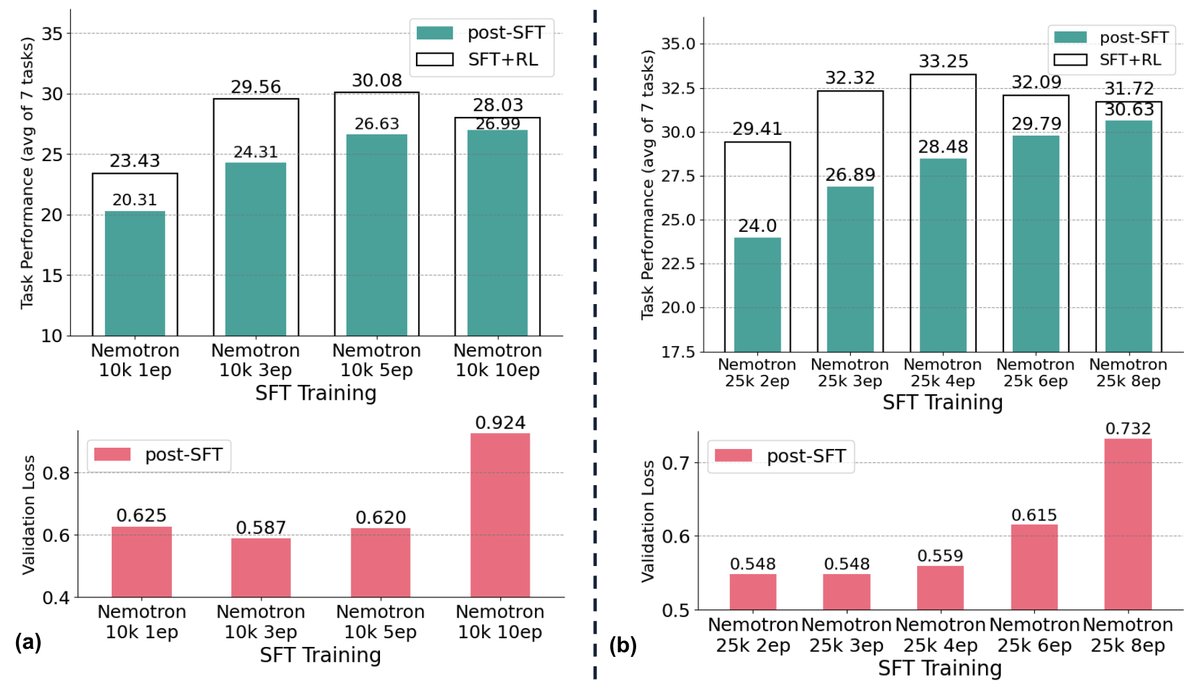
在这种场景下,SFT数据来自同一分布,但训练配置(如训练轮次、样本数量)不同。实验发现,增加训练轮次通常会稳定提升SFT分数,但过度训练(overtraining)的模型在后续RL阶段的潜力反而会下降。最终RL后性能最好的模型,往往不是SFT后分数最高的那个。
如下图所示,SFT分数与RL后的最终性能之间的线性相关性($R^{2}=0.43$)较弱,说明SFT分数只能解释最终性能约43%的变化,存在明显的预测鸿沟。
实例层面场景
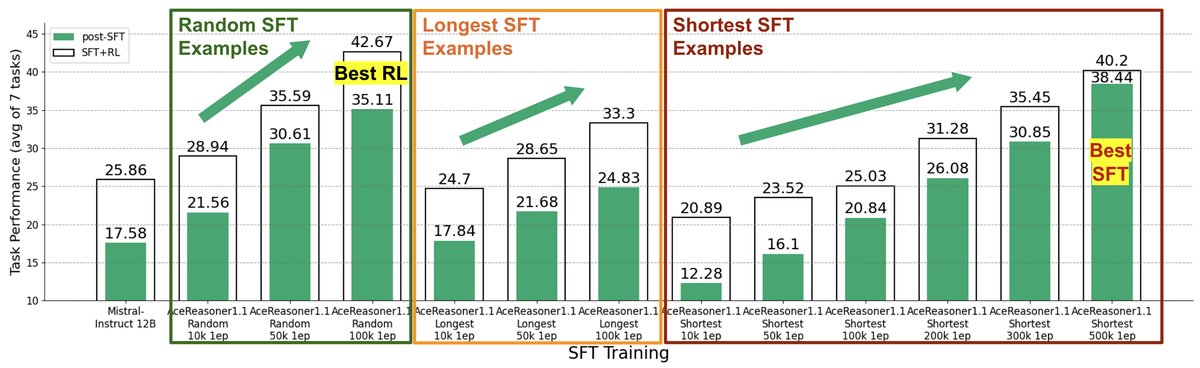
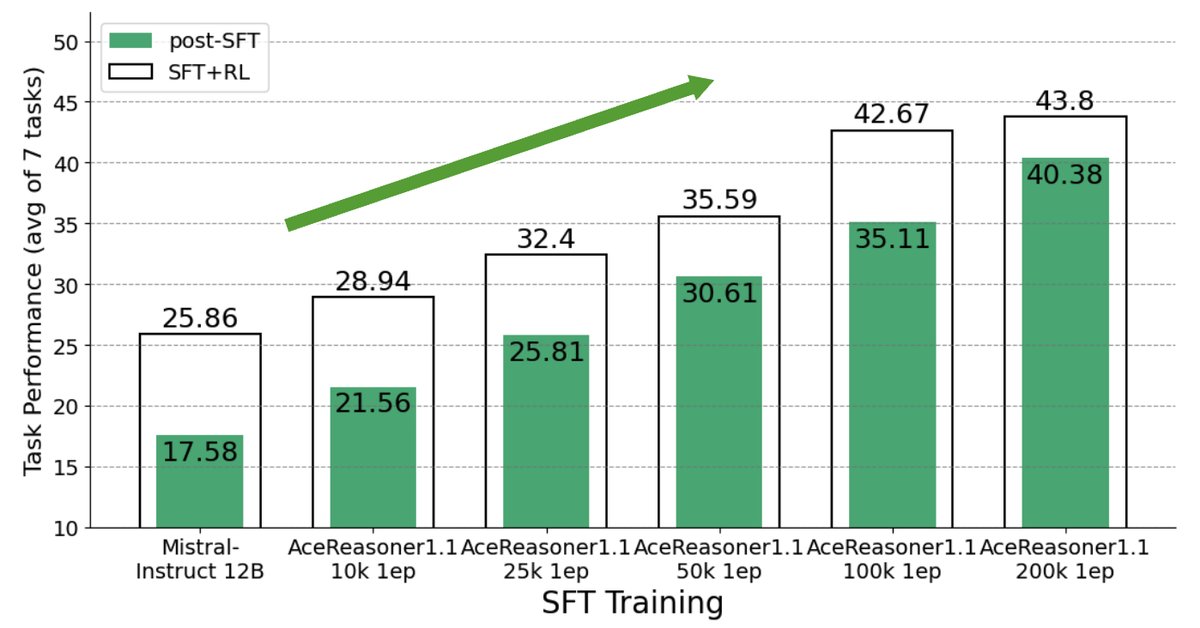
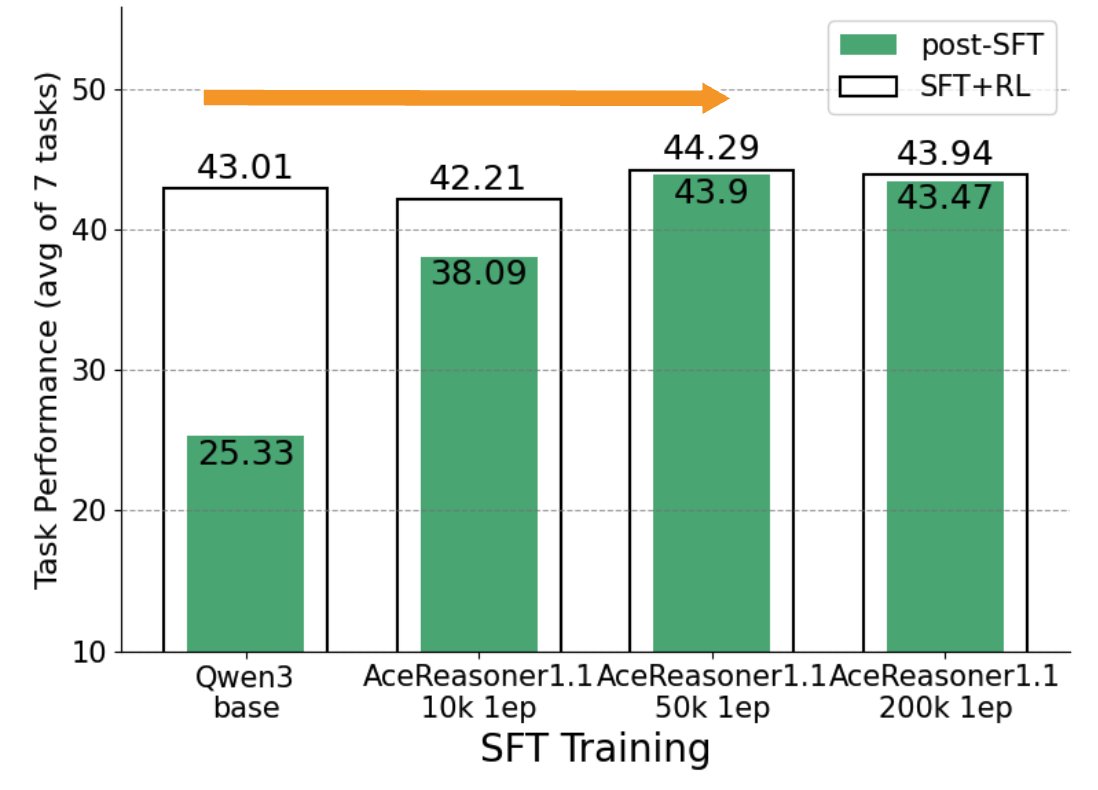
在这种场景下,训练流程固定,但SFT数据集不同。这对应了SFT数据筛选和构建的挑战。实验发现,某些数据选择策略(如选择解题步骤更短的“简单”样本)虽然能让模型在SFT阶段快速获得高分,但由于未能学习到更复杂的推理能力,其在RL后的最终表现反而更差。
如下图所示,训练模型使用的数据不同(例如,仅使用短答案 vs. 随机采样),SFT分数高的模型(蓝色点)在RL后的性能可能远不如SFT分数较低的模型(橙色点)。
提出的新预测指标
为了解决SFT指标的误导性问题,本文提出了两个新的替代指标,它们能更准确地预测RL后的模型性能。
验证集上的泛化损失
本文发现,在SFT训练过程中,随着模型在训练集上性能的提升(过拟合开始),其在留出验证集上的泛化损失会随之上升。这个泛化损失的上升趋势与后续RL阶段的性能增益呈现强烈的负相关关系。因此,通过监控泛化损失,可以在不进行昂贵的RL训练的情况下,提前判断SFT模型是否过拟合,并筛选出那些最有可能在RL后表现优异的模型。在实践中,可以排除那些SFT性能较低且泛化损失较高的模型。
Pass@k 在大 k 值下的准确率
RLVR的目标是最大化Pass@1准确率,而其训练过程(如GRPO算法)的有效性与模型在SFT阶段已具备的“探索”能力强相关。本文认为,相比于仅看一次尝试能否成功的Pass@1,评估模型在多次(例如$k$次)尝试中能否至少成功一次的Pass@k指标,尤其是在$k$值较大时,能更好地反映模型的内在问题解决能力和潜力。一个高Pass@large k的模型意味着它已经有能力生成正确的解题路径,只是需要RL来帮助它稳定地将这种能力转化为更高的Pass@1性能。
为了高效计算,本文使用了以下无偏估计公式,通过生成$n$个回答来估算所有$k \le n$的Pass@k值,其中$c$是$n$个回答中正确的数量:
\[\text{Pass}@k = \mathbb{E}\left(1-\frac{\binom{n-c}{k}}{\binom{n}{k}}\right)\]在实践中,可以评估不同SFT候选模型的Pass@large k(如Pass@64),并选择该指标最高的模型进行后续的RL训练。
实验结论
本文通过在Llama3、Mistral-Nemo、Qwen3等多种模型上进行的大规模SFT-RL后训练实验(总计消耗超过100万GPU小时),并在7个数学基准测试上进行了广泛评估,验证了所提指标的有效性。
实验设置:
- 模型: Llama3-12B, Mistral-Nemo-12B, Qwen3-4B-base。
- 数据集: SFT使用Llama-Nemotron和AceReasoner1.1-SFT的数学样本,RL使用MATH和DeepScaleR数据集。
- 评估: 使用7个数学基准(MATH, MMLU-Math, GSM8K, AIME, IMO, TAL-SCQ, MathVista),性能指标为Pass@1准确率。预测指标的有效性通过$R^{2}$(皮尔逊相关系数的平方)和Spearman等级相关系数来衡量。
关键结果:
- 预测性能显著提升:与基线方法(使用SFT后的Pass@1性能)相比,使用泛化损失和Pass@large k作为预测指标,可以将预测准确度($R^{2}$)和排序一致性(Spearman相关系数)提升高达0.5(性能翻倍)。
- 不同场景下的指标适用性:
- 在数据集层面预测(优化训练轮次等)中,泛化损失和Pass@large k均表现出色。
- 在实例层面预测(选择SFT数据集)中,由于不同数据集之间存在分布差异,泛化损失的比较性较差。然而,Pass@large k 在此场景下表现得异常稳健,因为它衡量的是模型内在能力,对数据分布变化不敏感,能有效对不同的SFT数据集进行排序。
- 实践指导:
- 在SFT预算相同的情况下,对一半数据训练两轮的效果通常优于对全部数据训练一轮。
- 仅在短答案等“简单”样本上训练虽然SFT分数高,但RL后的最终效果通常不如在混合长度样本上训练的模型。
最终结论: 本文有力地证明了“高SFT分数不等于高RL后性能”这一观点,并成功地找到了两个更可靠的预测指标:泛化损失和Pass@large k准确率。这些指标使开发人员能够在昂贵的RL阶段之前,更准确地评估SFT模型的好坏,从而优化数据策略和训练流程,降低开发风险。本文将开源其增强的评估工具,以促进更广泛的应用和研究。