Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution
-
ArXiv URL: http://arxiv.org/abs/2409.12191v2
-
作者: Kai Dang; Yang Fan; Shijie Wang; Jialin Wang; Sinan Tan; Rui Men; Wenbin Ge; Zhihao Fan; Shuai Bai; Peng Wang; 等9人
-
发布机构: Alibaba Group
TL;DR
本文提出了Qwen2-VL系列多模态模型,通过创新的原生动态分辨率机制和多模态旋转位置编码(M-RoPE),使模型能像人一样处理任意分辨率的图像和视频,并在广泛的多模态基准测试中展现出与GPT-4o等顶尖模型相媲美的性能。
关键定义
本文提出了两个核心技术创新,以增强模型的视觉感知能力:
-
原生动态分辨率 (Naive Dynamic Resolution):一种使模型能够处理任意分辨率图像的机制。与传统方法将图像缩放到固定尺寸不同,该机制动态地将不同分辨率的输入图像转换为数量可变的视觉Token。这是通过在视觉变换器(ViT)中引入二维旋转位置编码(2D-RoPE)替代固定的绝对位置编码实现的,从而让模型能够灵活捕捉不同尺度和长宽比图像中的细节信息。
-
多模态旋转位置编码 (Multimodal Rotary Position Embedding, M-RoPE):一种在大型语言模型(LLM)中统一处理文本、图像和视频位置信息的创新编码方式。它将传统的一维旋转位置编码分解为时间(temporal)、高度(height)和宽度(width)三个部分。对于文本,三者ID相同;对于图像,时间ID恒定,高度和宽度ID随位置变化;对于视频,时间ID随帧递增。这种设计不仅能更精确地建模多模态数据的位置关系,还有助于模型在推理时外推到更长的序列。
相关工作
当前的大型视觉语言模型 (Large Vision-Language Models, LVLMs) 通常遵循“视觉编码器→跨模态连接器→大型语言模型”的架构,在处理图文数据方面取得了巨大进步。然而,它们面临着几个关键瓶颈:
- 固定的输入分辨率:大多数模型要求输入图像具有固定的分辨率(如 224x224),这通常通过缩放或填充实现。这种“一刀切”的策略限制了模型捕捉不同尺度信息的能力,尤其会导致高分辨率图像中大量细节的丢失。
- 静态的视觉表征:许多模型依赖一个预训练后即冻结的(frozen)CLIP式视觉编码器,其产生的视觉表征可能不足以支持复杂的推理任务和细粒度细节的理解。
- 受限的位置编码:现有模型在处理视频等多帧输入时,通常仍使用一维位置编码,这限制了模型有效建模三维空间和时间动态的能力。
本文旨在解决上述问题,通过引入动态分辨率和更强的多模态位置编码,使模型能够更自然、更精确地感知视觉世界,同时探索LVLM在模型和数据规模上的扩展规律。
本文方法
Qwen2-VL沿用了Qwen-VL的“ViT编码器+LLM”基础框架,并在此之上进行了多项关键升级,以提升模型对任意分辨率视觉信息的感知、理解与推理能力。
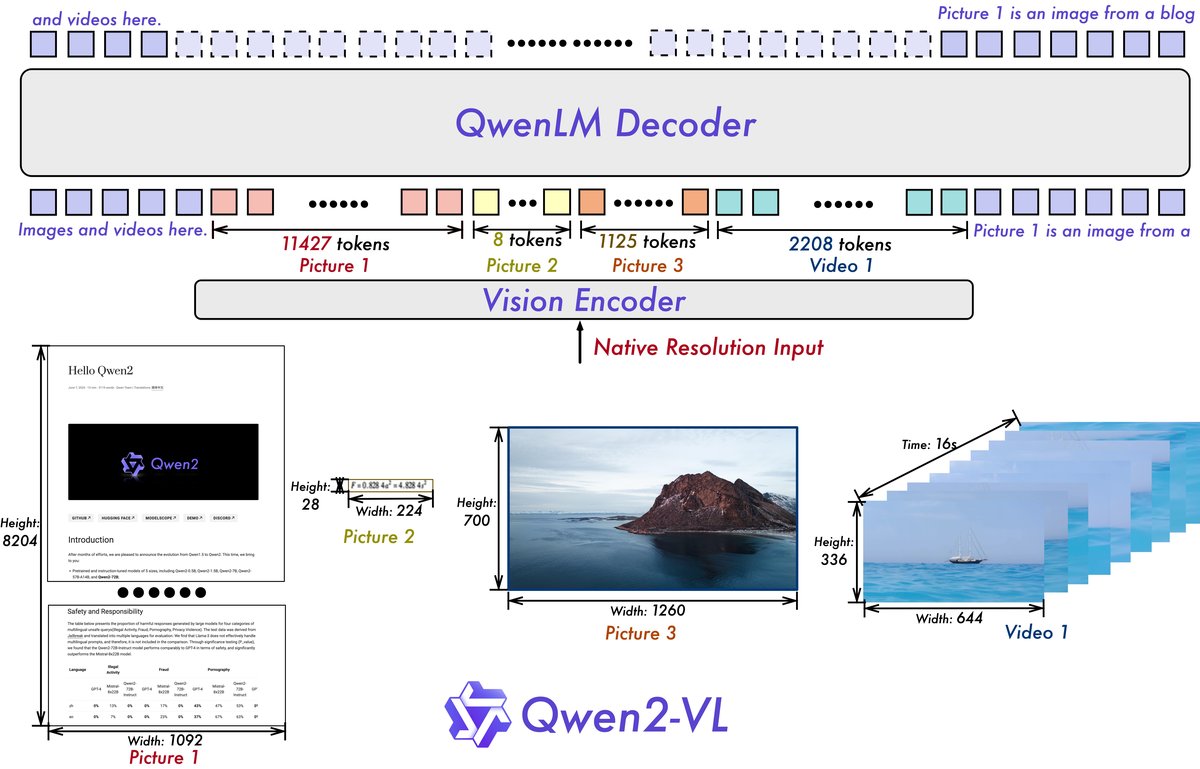
模型架构
Qwen2-VL系列包含2B、8B和72B三种参数规模的模型,它们均采用一个约6.75亿参数的ViT作为视觉编码器,以及更强大的Qwen2系列模型作为语言模型基座。其核心架构创新点如下:
创新点:原生动态分辨率
本文最核心的改进之一是引入了原生动态分辨率支持。
- 灵活编码:不同于以往模型,Qwen2-VL能够处理任意分辨率和长宽比的图像,并将其动态地转换为数量可变的视觉Token。
- 2D位置编码:为实现这一功能,本文修改了ViT,移除了绝对位置嵌入,并引入了二维旋转位置编码(2D-RoPE),从而能够捕获图像的二维空间位置信息。
- Token压缩:在ViT编码后,一个简单的MLP层会将相邻的 $2\times 2$ 的视觉Token压缩为单个Token,以减少输入到LLM的序列长度,提高效率。例如,一张 $224\times 224$ 分辨率的图像最终被压缩为66个视觉Token。
创新点:多模态旋转位置编码 (M-RoPE)
为了让LLM能够统一理解文本、图像、视频的位置信息,本文提出了M-RoPE。
- 维度分解:将传统LLM中的一维RoPE分解为时间(temporal)、高度(height)和宽度(width)三个独立的部分。
- 文本:所有Token的三个维度使用相同的位置ID,等效于标准1D-RoPE。
- 图像:所有Token的时间ID恒定,高度和宽度ID根据其在图像中的二维位置进行赋值。
- 视频:视频被视为图像帧序列,每个新帧的时间ID递增,帧内的高度和宽度ID赋值方式同图像。
- 优点:这种设计不仅增强了对多模态输入位置信息的建模能力,还通过降低位置ID的最大值,使模型在推理时能更好地外推到更长的序列。

统一的图像与视频理解
Qwen2-VL采用统一的范式处理图像和视频,增强了模型的动态视觉感知能力。
- 混合训练:同时使用图像和视频数据进行训练。
- 3D卷积:模型集成了深度为2的3D卷积,将视频输入作为3D管道(3D tubes)而非2D图像块(2D patches)处理。这使得模型能在不增加序列长度的情况下处理更多视频帧。
- 动态分辨率调整:为了平衡长视频处理的计算开销和训练效率,模型会动态调整视频帧的分辨率,将每个视频的总Token数限制在16384以内。
训练过程
本文采用了一个三阶段的训练策略:
- 第一阶段:仅训练ViT,使用大量图文对数据,使LLM学习基本的语义理解。ViT由DFN模型的参数初始化,但其绝对位置嵌入被替换为2D-RoPE。
- 第二阶段:解冻所有模型参数,使用更广泛的混合数据(如图文交错内容、视觉问答等)进行全面训练。
- 第三阶段:冻结ViT参数,仅使用指令数据集对LLM进行微调。
整个预训练过程共使用了约1.4万亿Token。指令微调阶段则采用了ChatML格式,构建了包含纯文本对话、多模态对话、文档解析、视频理解和智能体交互等多种任务的数据。
数据格式举例
为了支持复杂的视觉任务,本文定义了特定的数据格式,包括视觉定位和视觉智能体交互。
-
视觉定位:使用归一化的边界框坐标 \((X_top left,Y_top left),(X_bottom right,Y_bottom right)\) 和特殊Token $$< box_start >\(、\)< box_end >$$ 等来标注图像中的物体。 ``\(<|vision_start|>Picture1.jpg<|vision_end|> <|object_ref_start|>the eyes on a giraffe<|object_ref_end|><|box_start|>(176,106),(232,160) <|box_end|>\)`$$
-
视觉智能体:将用户界面操作、机器人控制等任务构建为序贯决策问题。模型通过分析观察(截图)、推理规划、并生成函数调用(\(*FUNCTION*\), \(*ARGS*\))来与环境交互,直至完成任务。
\(`\) <|im_start|>user Find a pizza restaurant nearby in Map. <|vision_start|>Screenshot_1.jpg<|vision_end|> <|im_end|> <|im_start|>assistant Several e-mails are displaying on the phone screen. To open Map, I need go back to the home screen and find the corresponding app icon. FUNCTION: Home ARGS: {} RESULT: <|vision_start|>Screenshot_2.jpg<|vision_end|> RETURN: I return to the home screen. Next, I need to find the icon of Map and tap on it. FUNCTION: Tap ARGS: {“point”: (348,291)} … I have found the pizza restaurant nearby in Map. <|im_end|> $$``
实验结论
本文通过在大量公开基准上的广泛评测,验证了Qwen2-VL系列模型的强大性能,并在多个任务上刷新了SOTA记录。
与SOTA模型的对比
在与包括GPT-4o和Claude-3.5 Sonnet在内的顶尖模型的全面对比中,Qwen2-VL-72B表现出极强的竞争力。
| 基准测试 | 先前SOTA | Claude-3.5 Sonnet | GPT-4o | Qwen2-VL-72B | Qwen2-VL-7B | Qwen2-VL-2B |
|---|---|---|---|---|---|---|
| MMMU (val) | 66.1 | 68.3 | 69.1 | 64.5 | 54.1 | 41.1 |
| DocVQA (test) | 94.1 | 95.2 | 92.8 | 96.5 | 94.5 | 90.1 |
| InfoVQA (test) | 82.0 | - | - | 84.5 | 76.5 | 65.5 |
| RealWorldQA | 72.2 | 60.1 | 75.4 | 77.8 | 70.1 | 62.9 |
| OCRBench | 852 | 788 | 736 | 877 | 866 | 809 |
| MTVQA | 23.2 | 25.7 | 27.8 | 30.9 | 25.6 | 18.1 |
| MathVista (testmini) | 69.0 | 67.7 | 63.8 | 70.5 | 58.2 | 43.0 |
- 优势领域:Qwen2-VL-72B在文档理解(如DocVQA、InfoVQA)、真实世界问答(RealWorldQA)、OCR(OCRBench)以及多语言能力(MTVQA)等需要精细视觉感知的任务上取得了SOTA,并超越了GPT-4o等闭源模型。
- 待提升领域:在需要复杂跨学科知识推理的MMMU基准上,Qwen2-VL-72B与GPT-4o相比仍有一定差距,表明在处理某些极具挑战性的问题上还有提升空间。
关键能力验证
- 文档与图表阅读:在DocVQA、InfoVQA、TextVQA等多个基准上达到SOTA,证明其对图像中的文本内容(包括文档、图表、自然场景文字)具有出色的理解能力。
- 多语言文本识别:在公开多语言OCR基准MTVQA上超越了所有现有通用LVLM。在内部测试中,其在韩语、日语、法语等多种语言上的表现也优于GPT-4o。
| 语言 | 韩语 | 日语 | 法语 | 德语 | 意大利语 | 俄语 | 越南语 | 阿拉伯语 |
|---|---|---|---|---|---|---|---|---|
| GPT-4o | 87.8 | 88.3 | 89.7 | 88.3 | 74.1 | 96.8 | 72.0 | 75.9 |
| Qwen2-VL-72B | 94.5 | 93.4 | 94.1 | 91.5 | 89.8 | 97.2 | 73.0 | 70.7 |
- 视频理解:在MVBench、PerceptionTest、EgoSchema等视频理解基准上,Qwen2-VL-72B均取得最佳性能,展示了其在短视频和长视频理解任务上的卓越能力。
| 基准测试 | 先前SOTA | Gemini 1.5-Pro | GPT-4o | Qwen2-VL-72B | Qwen2-VL-7B |
|---|---|---|---|---|---|
| MVBench | 69.6 | - | - | 73.6 | 67.0 |
| PerceptionTest (test) | 66.9 | - | - | 68.0 | 62.3 |
| EgoSchema (test) | 62.0 | 63.2 | 72.2 | 77.9 | 66.7 |
- 视觉智能体(Agent)能力:在包括UI操作、机器人控制、卡牌游戏等多种视觉智能体任务中,Qwen2-VL展现出强大的顺序决策和工具调用能力,在多个任务上超越了之前的SOTA和GPT-4o。但在需要进行复杂3D环境建模的视觉导航任务(如R2R)中,与专用模型相比仍有差距。
消融研究
实验证明了动态分辨率策略的有效性。与固定Token数的策略相比,动态分辨率不仅在各类基准测试中取得了顶级或相当的性能,而且平均消耗的Token数更少,证实了该方法的鲁棒性和高效性。
最终结论
Qwen2-VL通过原生动态分辨率和M-RoPE等架构创新,并结合大规模训练,成功构建了一系列性能卓越的多模态模型。实验表明,该模型不仅在处理任意分辨率的图像和视频方面具备显著优势,还在文档理解、多语言OCR、视频分析和视觉智能体等多个领域设立了新的技术标杆,证明了本文所提方法的有效性和先进性。