Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
-
ArXiv URL: http://arxiv.org/abs/2409.12122v1
-
作者: Jianhong Tu; Runji Lin; Mingfeng Xue; Bofei Gao; Chengpeng Li; Tianyu Liu; Beichen Zhang; Binyuan Hui; Dayiheng Liu; Xingzhang Ren; 等6人
-
发布机构: Alibaba Group
TL;DR
本文提出了一系列数学专用大语言模型 Qwen2.5-Math,其核心创新在于将“自我改进”(self-improvement)的理念贯穿于从预训练、后训练到推理的整个模型开发流程,从而在多个数学基准上实现了超越现有开源及闭源模型(如GPT-4o)的顶尖性能。
关键定义
-
自我改进 (Self-Improvement):本文的核心哲学,指利用模型自身(或其前代版本)的能力来迭代地增强其学习过程。具体体现在:(1) 在预训练阶段,利用已有模型生成大规模高质量的数学数据;(2) 在后训练阶段,用模型生成的数据训练奖励模型(Reward Model),再用奖励模型反过来指导监督微调(SFT)数据的迭代和强化学习(RL);(3) 在推理阶段,用奖励模型指导采样以优化输出。
-
工具集成推理 (Tool-Integrated Reasoning, TIR):一种推理模式,允许模型调用外部工具(本文特指 Python 解释器)来执行精确计算、符号操作或复杂的算法任务。这与完全依赖模型内部知识进行逐步推导的“思维链”(Chain-of-Thought, CoT)推理形成互补。
-
Qwen数学语料库v2 (Qwen Math Corpus v2):一个总量超过 1 万亿(1T)token的高质量数学预训练数据集。它是在 v1 版本(700B token)的基础上,利用 Qwen2-Math-Instruct 模型合成了更多高质量数学数据,并扩充了更多中文数学内容(网页、书籍、代码等)而构建的。
-
组相对策略优化 (Group Relative Policy Optimization, GRPO):一种用于大语言模型训练的强化学习算法。它通过计算一组采样输出的平均奖励作为基线,来估计每个输出的优势(advantage),从而进行策略优化,该方法无需像 PPO 那样需要一个额外的价值函数。
相关工作
当前,通用大语言模型由于在预训练阶段缺乏足够的数学相关数据,其数学推理能力普遍存在不足。尽管先前已有研究(如 Minerva、DeepSeekMath)证明,通过构建大规模的数学专业语料库进行持续预训练是提升模型数学能力的有效途径,但该领域仍面临两大关键瓶ăpadă颈:
- 高质量数据的稀缺性:如何自动且大规模地生成高质量、高可靠性且覆盖多种推理形式(如CoT和TIR)的训练数据,是提升模型能力的核心挑战。
- 对齐与优化的复杂性:如何高效地利用这些数据,通过监督微调和强化学习,使模型的推理过程与正确解题路径对齐,并持续优化其性能,仍是亟待解决的问题。
本文旨在解决上述问题,通过一套系统性的“自我改进”流程,不仅提升模型在英、中文数学问题上的推理能力,尤其是在高难度问题上的表现,同时也探索出一条不完全依赖模型参数规模扩张的性能提升路径。
本文方法
本文提出了一套从 Qwen2-Math 演进至 Qwen2.5-Math 的完整开发流程,其核心是“自我改进”理念在预训练和后训练阶段的系统性应用。
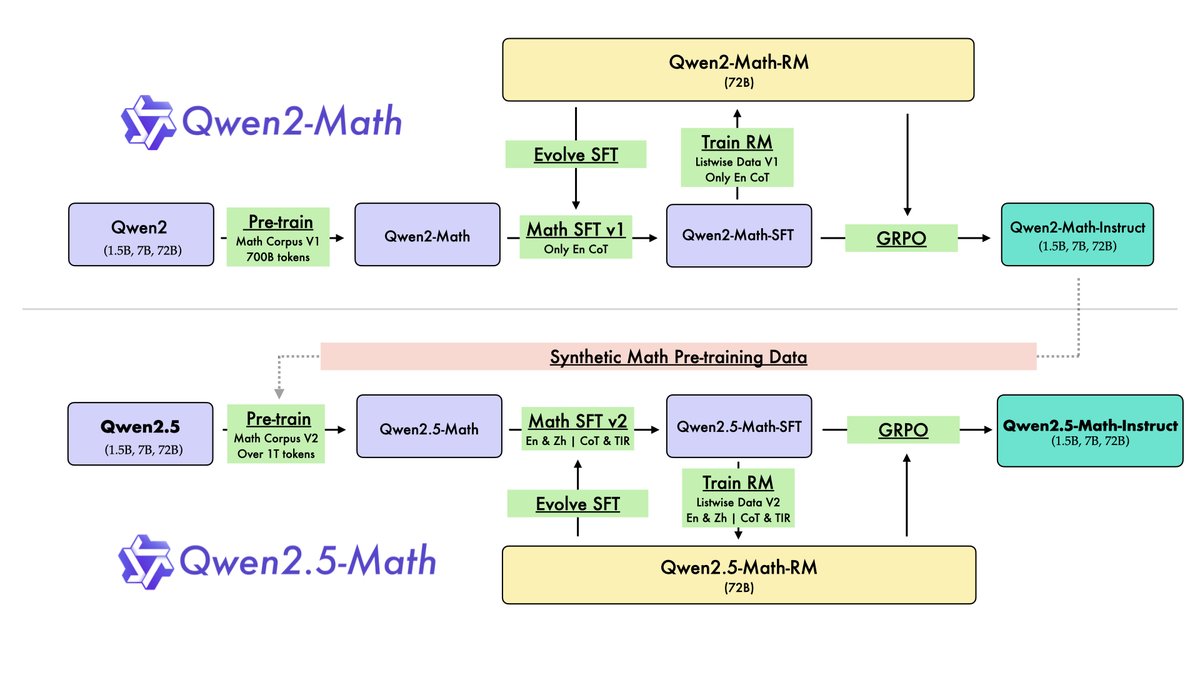 图注:Qwen2-Math 和 Qwen2.5-Math 的开发流程。
图注:Qwen2-Math 和 Qwen2.5-Math 的开发流程。
预训练阶段:基于自我改进的数据增强
预训练的目标是构建一个富含数学知识的高质量数据集。相比于 Qwen2-Math 使用的 Qwen Math Corpus v1 (700B token),Qwen2.5-Math 的预训练采用了升级版的 Qwen Math Corpus v2 (超过 1T token)。其增强主要来自三个方面:
- 自我数据合成:利用上一代性能最强的 Qwen2-Math-72B-Instruct 模型,大规模地合成新的高质量数学预训练数据。
- 数据源扩充:收集了更多高质量的数学数据,特别是来自网页、书籍和代码库的中文数学内容。
- 更强的基座模型:Qwen2.5-Math 的预训练不再从 Qwen2 系列初始化,而是从语言、代码和推理能力更强的 Qwen2.5 通用系列模型开始,再使用 Qwen Math Corpus v2 进行持续预训练。
通过在数据集和基座模型上的双重改进,Qwen2.5-Math 的基础数学能力得到了显著提升。
后训练阶段:SFT、RM与RL的迭代循环
后训练阶段旨在进一步增强模型在思维链(CoT)和工具集成推理(TIR)上的逻辑推理能力,该阶段包含监督微调、奖励模型训练和强化学习三个紧密相连的环节。
监督微调 (Supervised Fine-tuning, SFT)
本文为 CoT 和 TIR 两种模式分别构建了专用的 SFT 数据集。
- CoT数据合成:
- 问题构建:收集了约 58 万英文和 50 万中文数学问题,来源包括公开数据集(GSM8K, MATH)和独家的K-12题库,并使用 MuggleMath 方法进行问题演化,以增加多样性。
- 答案构建:采用迭代方法。首先,用当前最好的模型为每个问题生成多个推理路径。然后,对于有标准答案的问题,保留最终答案正确的路径;对于没有标准答案的合成问题,则通过加权多数投票来确定可能的正确路径。最后,利用奖励模型(RM)从这些正确路径中挑选得分最高的作为最终的训练样本。
- TIR数据合成:
- 问题构建:为克服 CoT 在精确计算和复杂算法上的弱点,本文构建了 TIR 数据集,包含 19 万有标注问题和 20.5 万合成问题。
- 答案构建:采用在线拒绝微调(Online Rejection Fine-Tuning)方法,迭代生成使用 Python 解释器且最终答案正确的推理路径。对合成问题则采用最优模型生成路径后,通过多数投票进行筛选。
奖励模型 (Reward Model, RM) 训练
为了在最终答案之外提供更细粒度的监督信号,本文训练了一个数学专用的奖励模型 Qwen2.5-Math-RM。
- 数据合成:为每个数学问题,从 SFT 模型中采样 6 个候选答案。根据这些答案的最终计算结果是否正确,将其标记为“正样本”或“负样本”。通过引入不同版本的模型和不同大小的模型进行采样,确保了数据的多样性和难度均衡。
- 训练策略:RM 从 SFT 模型初始化,将原有的语言模型头替换为一个输出标量值的线性层。训练时采用 listwise 排名损失函数,目标是让正样本的奖励得分高于负样本的得分。损失函数公式如下:
其中,$r_{\theta}(x,y)$ 是奖励模型的输出,$k$ 是正样本数量。
强化学习 (Reinforcement Learning, RL)
在 SFT 之后,本文采用 RL 进一步优化模型。
- 算法:使用 GRPO (Group Relative Policy Optimization) 算法,该算法无需额外的价值函数,简化了训练过程。其目标函数为:
- 奖励塑造 (Reward Shaping):结合了来自奖励模型(RM)的稠密奖励和来自规则验证器(检查最终答案是否正确)的稀疏奖励,形成最终的奖励信号。公式为:
其中 $r_m$ 是 RM 的分数,$r_v \in {0, 1}$ 是验证器结果,$\alpha=0.5$。这种设计确保了最终答案正确的回答总能获得更高的奖励。
数据去污
为保证评估的公正性,本文实施了严格的数据去污流程。使用 13-gram 匹配结合文本归一化来识别和过滤训练数据中与测试集重叠或高度相似的样本。特别地,本文还排除了那些与测试题在概念或结构上高度相似但非完全重复的问题,以避免“隐性”泄露。
| MATH 训练集中的问题 (已过滤) | MATH 测试集中的问题 |
|---|---|
| $1+2+3+4+\dots+9+10$ 除以 8 的余数是多少? | $1+2+3+4+\dots+9+10$ 除以 9 的余数是多少? |
| 在 1 到 1000(含)之间,有多少个整数 $n$ 使得 $\frac{n}{1400}$ 的小数表示是有限的? | 在 1 到 1000(含)之间,有多少个整数 $n$ 使得 $\frac{n}{1375}$ 的小数表示是有限的? |
| Krista 周日早上在新存钱罐里存了 1 分钱。周一存了 2 分,周二存了 4 分,并持续两周每天存入的钱翻倍。在哪一天,她存钱罐里的总金额首次超过 2 美元? | Krista 周日早上在新存钱罐里存了 1 分钱。周一存了 2 分,周二存了 4 分,并持续两周每天存入的钱翻倍。在哪一天,她存钱罐里的总金额首次超过 5 美元? |
表格 1:MATH 训练集中与测试集相似而被过滤的样本示例。
实验结论
基础模型评估
在少样本思维链(few-shot CoT)设置下,Qwen2.5-Math 的基础模型表现出色。
- Qwen2.5-Math-7B 在 GSM8K 和 MATH 上的得分(91.6, 55.4)甚至超越了体量远大于它的 Qwen2-72B(89.5, 51.1)和 Llama-3.1-405B(89.0, 53.8)。
- Qwen2.5-Math-72B 在 MATH、CMATH 等多个基准上创下了新的 SOTA 记录,其中 MATH 得分达到 66.8。 这证明了 Qwen Math Corpus v2 和持续预训练策略的有效性。
 图注:Qwen2.5-Math-1.5/7/72B-Instruct 在 MATH 数据集上使用 CoT 的性能,与其他同尺寸模型对比。
图注:Qwen2.5-Math-1.5/7/72B-Instruct 在 MATH 数据集上使用 CoT 的性能,与其他同尺寸模型对比。
指令微调模型评估
Qwen2.5-Math-Instruct 在英语和中文数学基准上均取得了 SOTA 性能。
英语基准表现 (如 GSM8K, MATH, OlympiadBench 等):
- 跨尺寸的性能提升:Qwen2.5-Math-Instruct 模型实现了显著的“以小博大”。例如,7B 模型在使用 CoT 时的性能(MATH 83.6)接近 Qwen2-Math-72B-Instruct 的水平(MATH 84.0),证明了数据和训练策略的优化可以弥补参数规模的差距。
- 超越最强闭源模型:旗舰模型 Qwen2.5-Math-72B-Instruct 在 CoT 模式下的平均分(68.2)超过了 GPT-4o(62.0)。
- TIR 模式效果显著:在 TIR 模式下,模型性能得到进一步飞跃。72B 模型在 MATH 上的得分高达 88.1。值得注意的是,Qwen2.5-Math-7B-Instruct 启用 TIR 后,其性能(Avg. 67.4)已能与 72B 模型在 CoT 模式下的性能(Avg. 68.2)相媲美,突显了外部工具在辅助推理中的巨大价值。
- 奖励模型的有效性:在几乎所有测试中,使用奖励模型进行最优选择(RM@8)的得分均显著高于多数投票(Maj@8),证明了 RM 能够更可靠地识别出高质量的解题路径。
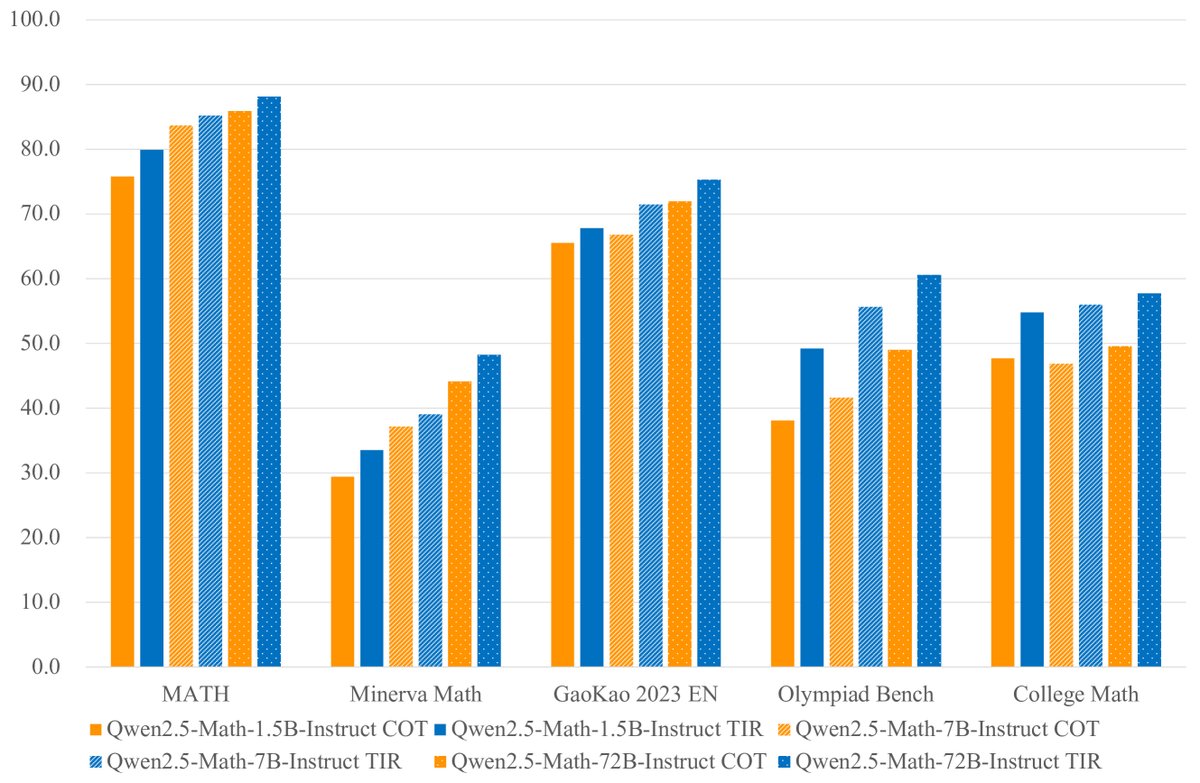 图注:Qwen2.5-Math-Instruct 使用 TIR(蓝色)和 CoT(橙色)的性能对比。可以看出 TIR 带来了显著的性能提升。
图注:Qwen2.5-Math-Instruct 使用 TIR(蓝色)和 CoT(橙色)的性能对比。可以看出 TIR 带来了显著的性能提升。
中文基准表现 (如 GaoKao, CMATH 等):
- 中文能力大幅增强:由于在 Qwen2.5-Math 开发中有意识地加入了中文数学数据,模型的中文能力获得了巨大提升。Qwen2.5-Math-72B-Instruct 在中文基准上的平均分(82.7)比 GPT-4o(65.2)高出 17.5 分。
- TIR 模式的差异:与在英语上的表现不同,TIR 模式在中文基准上并未展现出超越 CoT 的显著优势,这一点被作者列为未来研究的方向。
高难度竞赛级问题表现: 在 AIME 2024 和 AMC 2023 等极具挑战性的数学竞赛基准上,Qwen2.5-Math-Instruct 相比前代模型表现出显著的性能提升,证明其在解决复杂数学问题上的强大能力。
最终结论:本文通过系统性地应用“自我改进”方法论,结合高质量的 CoT 和 TIR 数据合成,以及“SFT-RM-RL”的先进训练流程,成功打造了 Qwen2.5-Math 这一数学专家模型系列。该系列模型不仅在多项英、中文数学基准上树立了新的 SOTA,还证明了通过改进数据和训练策略是提升模型能力的一条与扩大模型规模同样重要、甚至更高效的路径。