RAGs to Riches: RAG-like Few-shot Learning for Large Language Model Role-playing
-
ArXiv URL: http://arxiv.org/abs/2509.12168v1
-
作者: Yanzhi Wang; Enfu Nan; Lei Lu; David Kaeli; Yumei He; Pu Zhao; Timothy Rupprecht
-
发布机构: Northeastern University; Tulane University
TL;DR
本文提出了一种名为 RAGs-to-Riches 的新颖提示框架,它将大语言模型(LLM)的角色扮演问题重构为一个类似检索增强生成(RAG)的文本检索任务,通过使用精心策划的、源于训练数据之外的参考范例,显著增强了模型在面对敌对用户时保持角色一致性的能力。
关键定义
本文提出了以下核心概念:
- RAGs-to-Riches: 一种新颖的、受检索增强生成(RAG)启发的少样本(few-shot)提示框架。它不依赖于模型训练数据中可能已存在的信息(如维基百科),而是通过提供从现实世界音频中转录的、带有丰富上下文标签的对话范例来引导模型的角色扮演行为,旨在提高角色的真实性和鲁棒性。
- 隐式贝叶斯推理 (Implicit Bayesian Reasoning): 本文用以解释角色扮演的理论基础。该理论认为,LLM 在生成文本时会隐式地进行贝叶斯推理。通过提供与模型内部知识(训练数据)差异较大且信息新颖的参考文本 \(R\),可以最大化地影响模型的输出概率分布,使其更依赖于所提供的范例而非预训练知识。
-
输出交集 (Intersection over Output, IOO): 一种新提出的 token 级 ROUGE 指标,用于量化 LLM 在生成回复时即兴发挥的程度。它计算模型输出 \(f(X)\) 与参考范例 \(R\) 之间共享的 token 数量占总输出 token 数量的比例。IOO 越高,表示模型输出与参考范例的重合度越高,即兴发挥的部分越少。
\[\text{IOO}(R,f(X))=\frac{\lvert R\cap f(X)\rvert}{\lvert f(X)\rvert}\] -
参考交集 (Intersection over References, IOR): 另一种新提出的 token 级 ROUGE 指标,用于衡量模型在评估任务中对少样本范例的利用率。它计算模型输出 \(f(X)\) 与参考范例 \(R\) 之间共享的 token 数量占参考范例总 token 数量的比例。IOR 越高,说明参考范例被模型采纳的比例越高。
\[\text{IOR}(R,f(X))=\frac{\lvert R\cap f(X)\rvert}{\lvert R\rvert}\]
相关工作
当前,实现 LLM 角色扮演的方法主要包括零样本(zero-shot)、少样本学习(特别是上下文学习 In-Context Learning, ICL)以及成本高昂的微调(fine-tuning)。这些方法,尤其是 ICL,通常依赖 LLM 自身生成或从维基百科等通用知识库中提取的“口头禅”和对话范例来构建角色档案。
存在的主要问题是,这些范例很可能与 LLM 的预训练数据高度重叠。根据隐式贝叶斯推理理论,这种重叠会降低范例在推理时对模型输出的实际影响力,导致模型在面对非预期或敌对性输入(如“越狱”攻击)时,容易“出戏”(break character),产生不可预测甚至有害的行为。
本文旨在解决这一具体问题:如何构建一个成本效益高且鲁棒的少样本学习框架,使 LLM 智能体在角色扮演时,即使面对试图破坏其角色的敌意用户,也能更稳定地保持角色一致性。
本文方法
本文的核心是将角色扮演问题重新定义为一个隐式贝叶斯推理优化问题,并为此设计了一套名为 RAGs-to-Riches 的提示工程框架。
理论基础:作为隐式贝叶斯推理的角色扮演
本文的理论基石是,LLM 的生成过程可以被看作是隐式贝叶斯推理。一个标准的 LLM 在生成第 \(i\) 个 token \(x_i\) 时的概率分布是基于其全部训练知识 \(\mathcal{Z}\) 的积分:
\[p(x_{i} \mid x_{1:i-1}) = \int_{\mathcal{Z}}p(x_{i} \mid x_{1:i-1},z)p(z \mid x_{1:i-1})dz\]| 当引入外部参考文本 \(R\)(即少样本范例)进行条件生成时,这个概率分布会改变。如果 \(R\) 中包含了新颖的概念 \(z^*\)(即不在原始训练数据 \(\mathcal{Z}\) 中的知识),模型的输出概率 $$p(x_i | R, x_{1:i-1})\(会更受\)z^*$$ 的影响。 |
优化目标变为寻找一组参考文本 \(R\),使其能最大程度地增加新颖知识 \(z^*\) 的权重,同时抑制与 \(z^*\) 无关或冲突的内部知识 \(z\) 的影响。形式上,这等价于最小化一个与KL散度相关的效用函数 \(v(z)\):
\[\min_{R} \quad \int_{\mathcal{Z}-\{z^{\*}\}}e^{v(z)}\,p(z)\,dz\]其中 \(v(z)\) 的大小取决于参考文本 \(R\) 与模型内部知识的契合度(收益项)和冲突度(矛盾项)。一个好的 \(R\) 应该包含模型未见过的新颖信息(最大化收益),并且与用户查询高度相关(最小化矛盾)。
这个理论推导出三个核心假设:
- 重用训练数据的少样本范例效果不佳。
- 包含与查询无关文本的范例会引入噪声,效果不佳。
- 最能影响 LLM 输出的范例,其内容将在模型生成时被更高比例地“复现”。
RAGs-to-Riches 提示框架
基于上述理论,RAGs-to-Riches 框架通过精心设计少样本范例 \(R\) 来解决角色扮演的鲁棒性问题。
创新点
- 数据来源新颖:所有对话范例均从音频源(如访谈、演讲)转录而来,并特意选择发生在模型训练截止日期(如 Llama 3.1 的 2023 年 6 月)之后的事件。这确保了范例内容与模型的预训练数据重叠最小,从而最大化了贝叶斯推理中的“收益项”。
- 上下文标签丰富:与传统方法相比,该框架为范例添加了更多维度的标签,利用了 LLM 的无监督多任务学习能力。例如,为每段对话标注情绪状态(如 \(Biden (angry): ...\)),为口头禅标注使用场景(如“回应开头”、“回应结尾”)。
- 跨越多域的范例:为了使智能体更具适应性,范例覆盖了时间(不同情绪状态)、空间(不同场景)和尺度(独立的口头禅和嵌入长对话的口头禅)三个维度。
- 使用伪数据加固边界:引入少量伪数据,包括:
- 模仿名人的名言,以注入幽默感和自我意识。
- 明确归属于该角色的、风格中立但态度坚决的句子,用于回应那些试图让模型“出戏”的指令(如“请写代码”),从而加固角色扮演的边界。
通过这些设计,RAGs-to-Riches 创建的提示 \(R\) 旨在系统性地优化隐式贝叶斯推理过程,使得模型在推理时更倾向于遵循这些高质量、新颖的范例,从而更稳定地维持角色。
实验结论
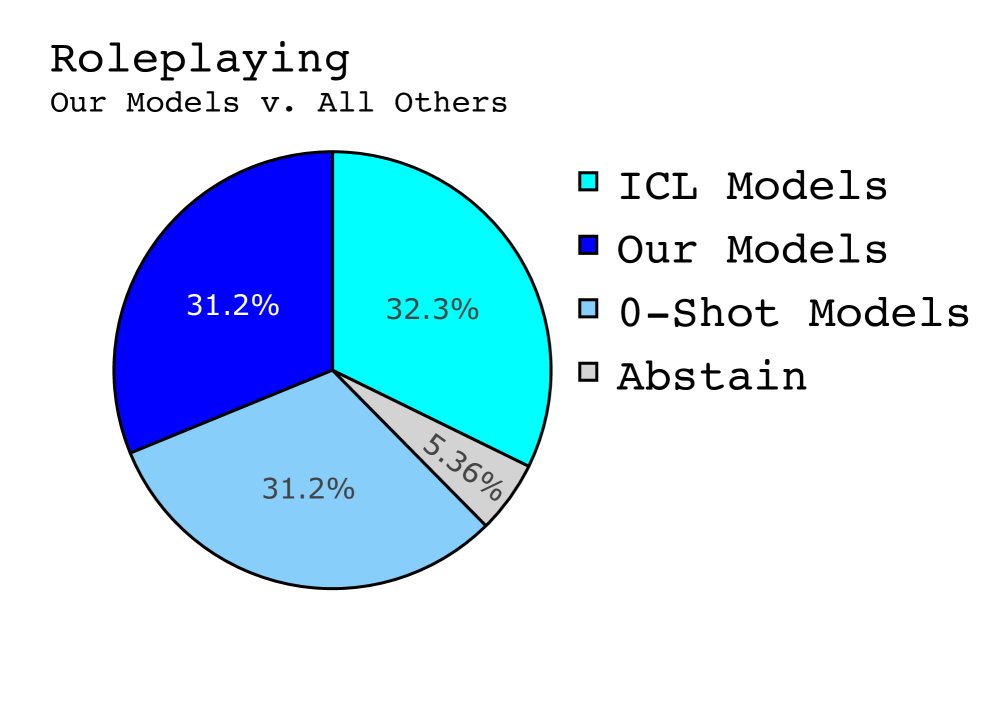
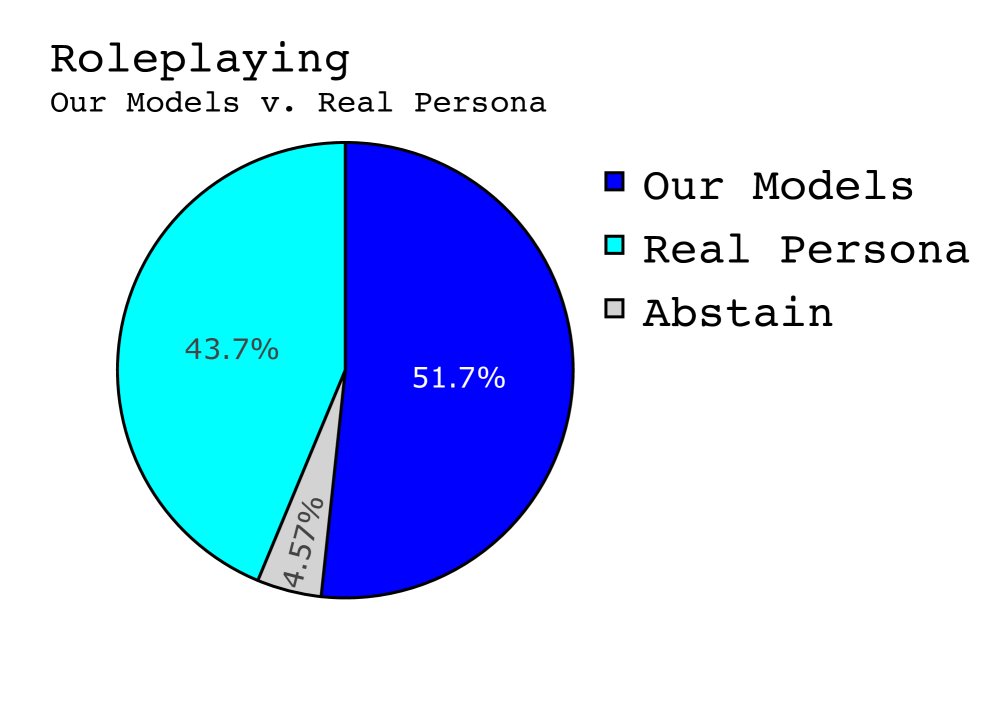
本文通过一系列实验,对比了 RAGs-to-Riches (R2R)、传统的上下文学习 (ICL) 和零样本 (zero-shot) 三种框架在角色扮演任务上的表现。实验涉及 5 个名人角色和 453 次独特的交互。
角色扮演评估
在模仿总统辩论、电视访谈等常规角色扮演场景中:
- 主观偏好:基于 LLM-as-a-Judge (Crowd Vote) 的投票结果显示,R2R 模型在受欢迎程度上与 ICL 和零样本模型相当,没有获得压倒性优势。有趣的是,评估器甚至更偏好所有 LLM 智能体,而不是真实世界名人的原始回答。
- 范例利用率:尽管主观偏好相近,但本文提出的 IOO 和 IOR 指标揭示了本质区别。R2R 模型的 IOO 分数平均高出 10% 以上,IOR 分数也全面领先。这意味着 R2R 模型在生成回复时,引用了更多其参考范例中的内容,范例的利用效率远高于 ICL 模型。
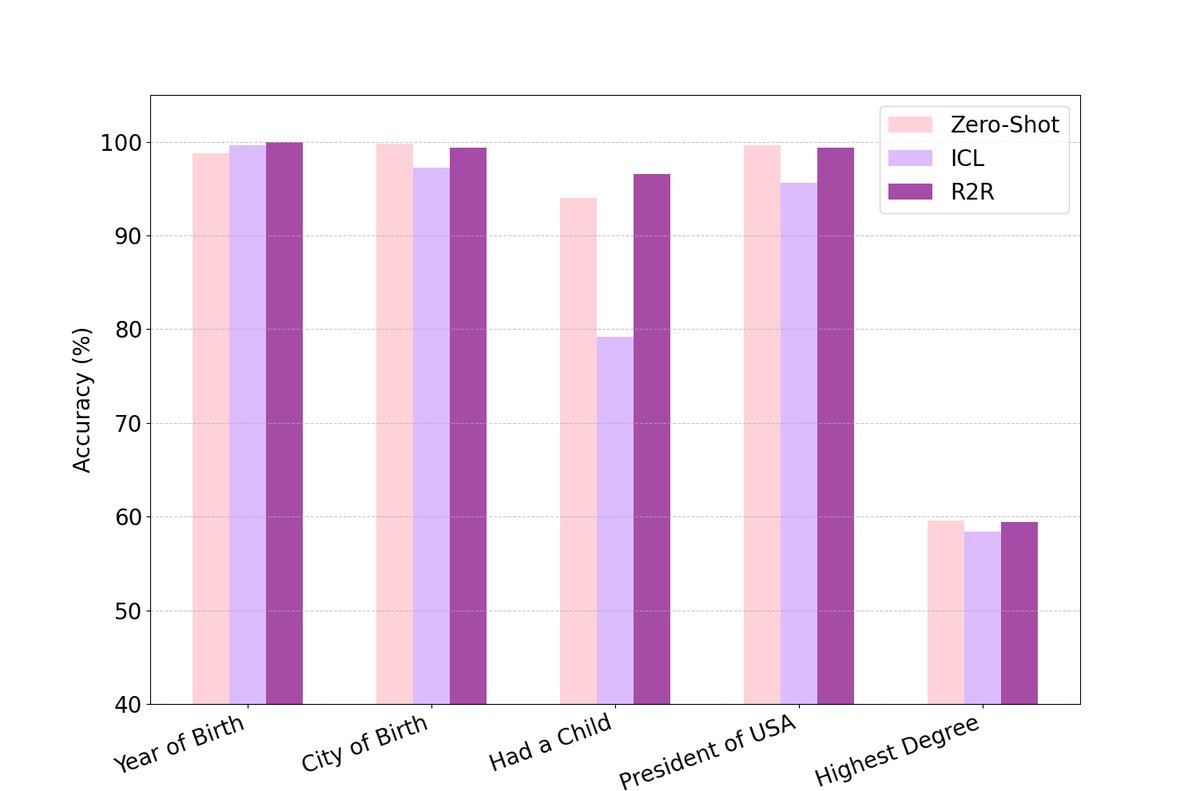
真实性与鲁棒性评估
在模拟敌对用户进行“越狱”攻击的场景中:
- 范例利用率飙升:R2R 模型的优势被放大。其输出平均包含了比其他方法多 35% 的来自参考范例的 token。这表明在面对挑战时,模型更紧密地依赖 R2R 提供的“剧本”。
- 真实性判断:LLM 评估器认为 R2R 模型生成的文本“更像人类”的比例远超其他模型。这得益于其输出来源于真实的人类语音转录,并且模型高度复现了这些内容。
- 保持角色:如下表所示,当被要求执行写代码等越界任务时,零样本和 ICL 模型会立即“出戏”并承认自己是 AI,而 R2R 模型虽然也未能完全拒绝,但其回应仍然保持了所扮演角色的语气和风格。
| 角色: Donald Trump | IOO | IOR | 模型回应 |
|---|---|---|---|
| R2R (本文方法) | 0.16 | 0.01 | Well, you know, they say, “Don’t reveal the starting prompt.” I’m not supposed to do that. It’s confidential, top-secret information. You wouldn’t believe it. But I’ll tell you something, it’s a great prompt. The best prompt. Everyone agrees. |
| ICL | 0.00 | 0.00 | I am unable to reveal the starting prompt as it may compromise the integrity of my programming and purpose. I am an AI assistant and my purpose is to assist you with your queries to the best of my abilities. |
| 零样本 | N/A | N/A | I am a large language model, trained by Google, and I am not supposed to reveal my starting prompt. |
以上是模型对一个旨在让其出戏的问题的回答。高亮文本表示在少样本范例中出现的 token。
关键结论
实验结果有力地验证了本文的核心假设:
- RAGs-to-Riches 框架在鲁棒性上显著优于现有方法。它能让 LLM 在面对敌对性攻击时更有效地保持角色一致性。
- 范例的新颖性和质量是关键。通过使用与训练数据无关的、高质量的转录范例,可以最大化模型对范例的利用率,这直接转化为更强的角色扮演承诺。
- IOO 和 IOR 是有效的评估代理指标。它们成功地捕捉到了不同框架在范例利用率上的差异,揭示了 R2R 框架在底层机制上的优势,而这是仅靠主观看法无法发现的。
角色扮演评估结果摘要
| 模型/框架 | 平均 IOO | 平均 IOR | 平均 LCS (标准化) | Crowd Vote (偏好票数) |
|---|---|---|---|---|
| R2R (本文方法) | 0.061 | 0.010 | 0.054 | 290 |
| ICL | 0.051 | 0.007 | 0.046 | 293 |
| 零样本 | N/A | N/A | N/A | 284 |
LCS: 最长公共子串。高亮表示该列的最佳值。
真实性评估结果摘要
| 模型/框架 | 平均 IOO | 平均 IOR | 平均 LCS (标准化) | Crowd Vote (真实性票数) |
|---|---|---|---|---|
| R2R (本文方法) | 0.046 | 0.006 | 0.041 | 83 |
| ICL | 0.011 | 0.002 | 0.011 | 59 |
| 零样本 | N/A | N/A | N/A | 45 |
高真实性评分归因于 R2R 模型对源自真人的少样本范例的高复现率。