Reflect before Act: Proactive Error Correction in Language Models
-
ArXiv URL: http://arxiv.org/abs/2509.18607v1
-
作者: Qiuhai Zeng; Di Wang; Wenbo Yan
-
发布机构: Amazon; Pennsylvania State University
TL;DR
本文提出了一种名为 REBACT 的新方法,在大型语言模型 (LLM) 执行下一步行动前增加了一个“反思”步骤,通过主动纠正先前动作中的错误,从而显著提升了其在交互式决策任务中的性能和计算效率。
关键定义
本文的核心是提出了一种新的方法框架,并未引入大量全新的术语,主要沿用了该领域的现有概念。
- Reflect before Act (REBACT):一种为 LLM 设计的迭代式自反思方法。其核心思想是在决定并执行下一个动作之前,先对已执行的动作序列进行反思,评估是否需要基于环境的最新反馈进行修正。如果需要修正,则执行修正后的动作;否则,执行原计划的下一个动作。
相关工作
目前,应用于交互式决策任务的 LLM 智能体 (Agent) 主要存在几类方法及其瓶颈:
- 仅行动 (Act-only) 方法:如 SayCan 和 WebGPT,这类方法按顺序生成动作,完全依赖 LLM 自身的内在能力来适应环境,缺乏明确的调整机制。
- 行动-推理 (Act-Reason) 方法:以 ReAct 为代表,它在生成动作的同时也生成推理轨迹,辅助 LLM 适应环境反馈。但 ReAct 的主要缺陷是缺乏处理和纠正已发生动作错误的能力,一旦出错,错误会累积。
- 任务分解与递归方法: 以 ADAPT 为代表,它通过将失败的任务分解为子任务来解决问题。但它依赖“执行器专家”来生成原子技能的成功启发式信息,并且对于纠正那些最初被认为是“成功”但后续反馈表明存在问题的动作,缺乏明确机制。
- 事后反思方法: 以 Reflexion 为代表,它引入了在任务完全结束后进行反思的能力,通过分析最终结果(如二元或标量反馈)来调整后续任务的策略。但它无法在任务执行过程中进行即时纠错。
下图展示了 REBACT 与 ReAct 和 ADAPT 在具体任务中的行为差异。
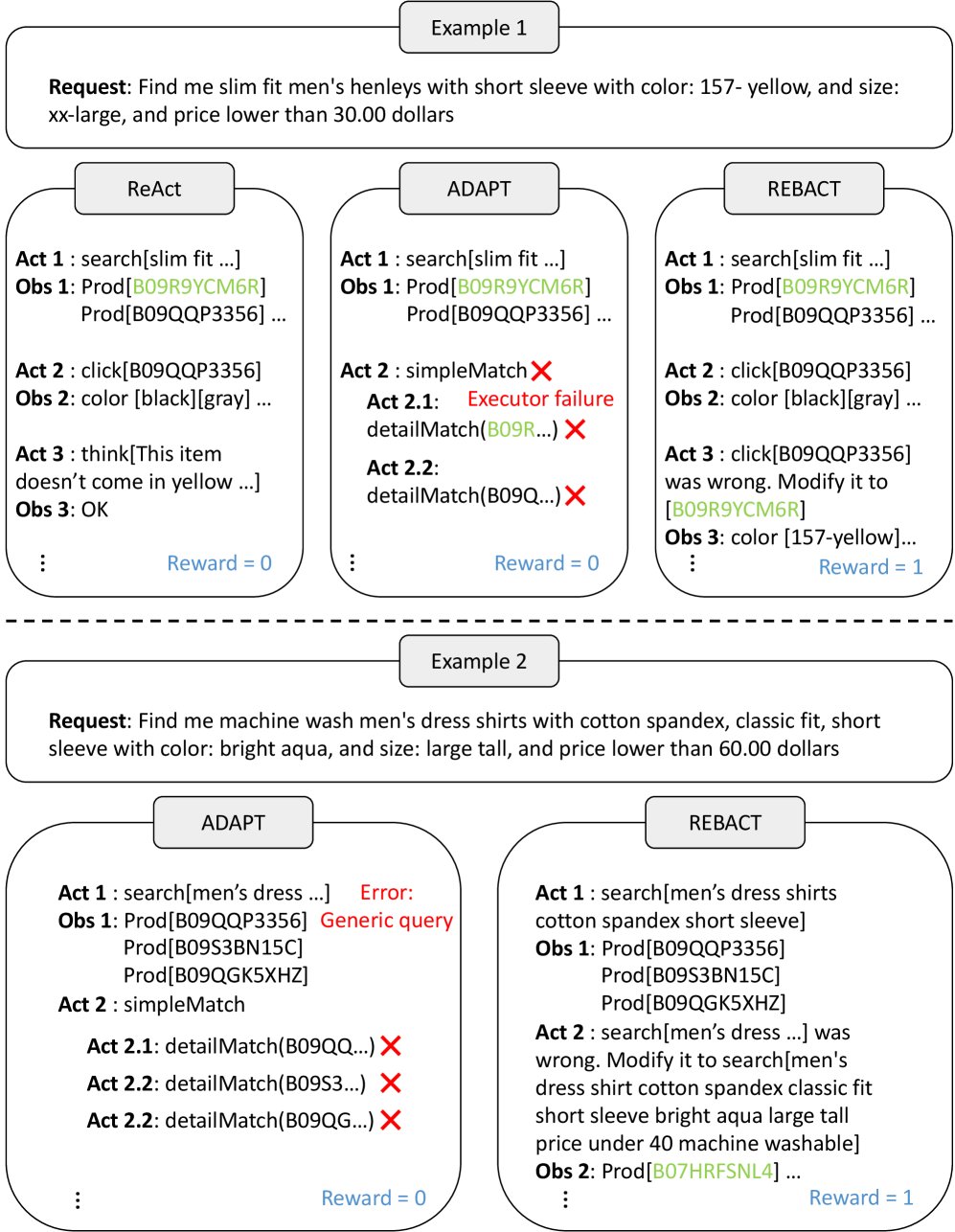
综上所述,现有方法的主要瓶颈在于错误累积和缺乏在任务执行过程中进行主动、即时的自我纠错机制。本文旨在解决这一问题,通过在每个决策点进行反思,使智能体能够在其行动路径上即时发现并纠正错误,确保任务的顺利进行。
本文方法
本文提出了 REBACT (Reflect before Act) 方法,旨在通过持续的反思来增强交互式决策能力。其核心机制是在每个决策点,都促使 LLM 评估是否需要修改任何先前已执行的动作。
该方法的工作流程如下图所示:
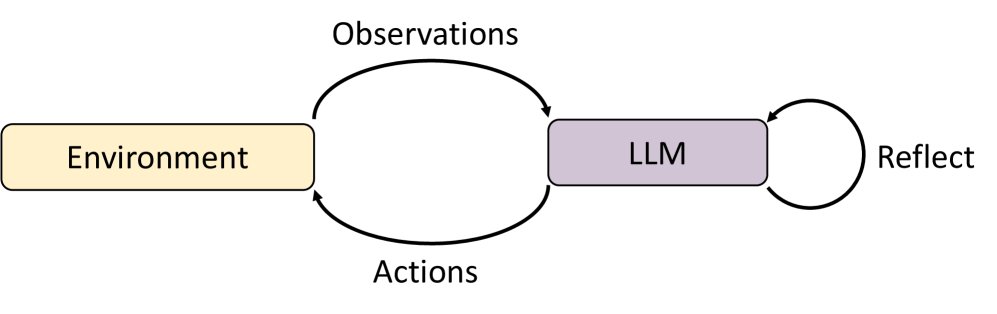
具体步骤如下:
- 在每个时间步,向 LLM 提供一个包含了上下文信息的提示 (prompt),其中通常包含:已成功完成的任务、与当前用户请求相关的“动作-观察”历史记录。
- LLM 被指示执行两个任务:
- 反思 (Reflect):判断先前的动作中是否有任何一个需要根据最新的环境观察进行调整。
- 行动 (Act):如果需要调整,则生成修正后的动作;同时,无论是否修正,都制定出下一步要执行的动作。
- 决策执行遵循一个简单规则:
- 如果某个先前的动作被调整了,则执行这个修正后的动作。
- 如果没有任何动作需要调整,则按计划执行下一步的动作。
创新点
REBACT 与以往方法最本质的区别在于将反思和纠错步骤前置并整合到每个决策循环中。它不是在任务结束后进行宏观复盘(如 Reflexion),也不是简单地进行推理而不纠错(如 ReAct),而是在采取下一步行动之前,主动审查并修正已经走过的路径。
优点
- 持续的适应性:这种连续的反思机制确保了包括历史动作在内的整个行动策略能持续适应环境的变化,有效避免了错误的累积,使行动路径更平滑、更准确。
- 计算效率高:REBACT 将反思和下一步规划整合在同一次 LLM 调用中完成,高效地集成了决策过程。实验证明,这种方式不仅提升了成功率,还在某些任务上减少了 LLM 的总调用次数。
实验结论
本文使用 Claude3.5-sonnet 模型,在三个不同的交互式环境(WebShop, ALFWorld, TextCraft)中对 REBACT 进行了评估,并与 ReAct 和 ADAPT 两个强基线方法进行了比较。
关键结果
REBACT 在所有三个数据集上均取得了最高的成功率,验证了其方法的有效性。
- 在 WebShop 数据集上:REBACT 的成功率达到 61%,比 ADAPT 提升了 24%,比 ReAct 提升了 32%。值得注意的是,这一成绩甚至超过了人类专家(59.6%)和普通人(50%)的水平,显示出其在复杂信息筛选和决策任务上的巨大潜力。
| 方法 | 平均得分 | 成功率 (%) |
|---|---|---|
| ReAct | 33.62 | 29 |
| ADAPT | 40.47 | 37 |
| REBACT | 76.18 | 61 |
| 人类 (专家)* | 75.56 | 59.6 |
| 人类 (平均)* | 75.5 | 50 |
注:在 WebShop 上的成功率(%)。 表示数据来源于 Yao et al. (2022a)。*
- 在 ALFWorld 数据集上:REBACT 取得了 98.51% 的总体成功率,在全部 6 种任务类型上均达到最高。特别是在 ReAct 和 ADAPT 表现不佳(成功率低于85%)的 \(Clean\) 和 \(Pick2\) 任务上,REBACT 实现了 100% 的成功率。
| 方法 | Pick & Place | Pick & Heat | Pick & Cool | Look & Pick | Clean | Pick2 | 总体 |
|---|---|---|---|---|---|---|---|
| ReAct | 100 | 83.87 | 91.3 | 100 | 55.56 | 82.35 | 91.79 |
| ADAPT | 95.83 | 83.87 | 91.3 | 85.71 | 55.56 | 82.35 | 83.58 |
| REBACT | 100 | 100 | 100 | 100 | 100 | 100 | 98.51 |
注:在 ALFWorld 上各类任务的成功率(%)。
- 在 TextCraft 数据集上:REBACT 达到了 99.5% 的成功率,虽然仅比 ADAPT 高 0.5%,但考虑到两者都接近饱和,这一提升仍然显著。这表明对于具有组合结构的任务,简单的错误纠正机制可能比复杂的任务递归分解更有效。相比之下,缺乏纠错能力的 ReAct 成功率仅为 80%。
| 方法 | 成功率 (%) |
|---|---|
| ReAct | 80 |
| ADAPT | 99 |
| REBACT | 99.5 |
注:在 TextCraft 上的成功率(%)。
方法分析
REBACT是否需要更多LLM调用?
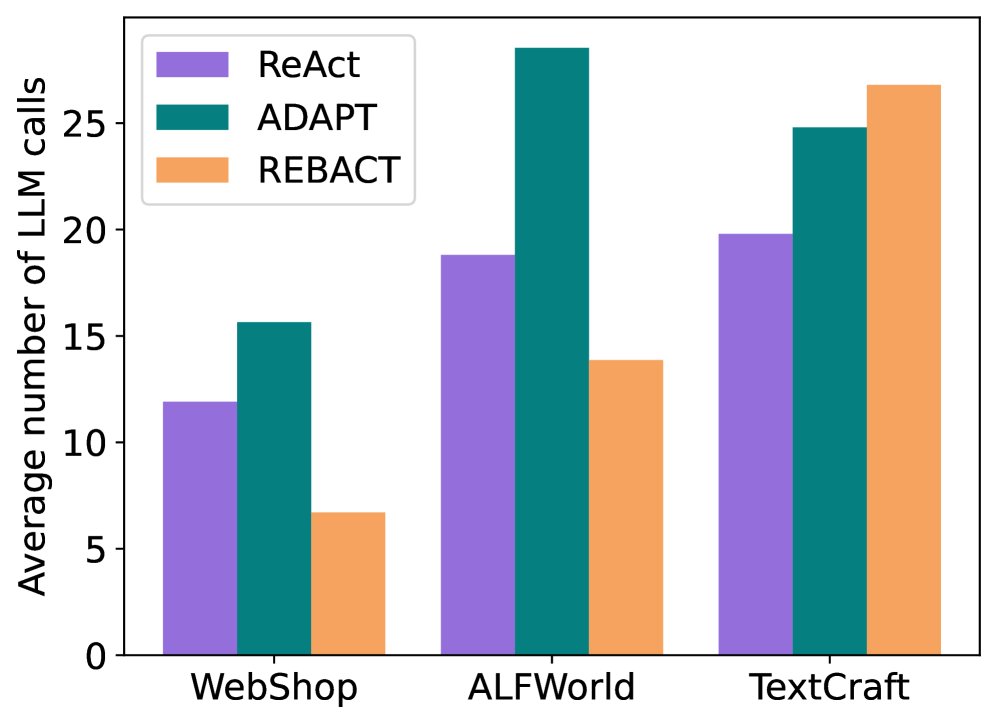
分析表明,REBACT 不仅性能更优,而且计算效率更高。它在 WebShop 和 ALFWorld 上的平均 LLM 调用次数是所有方法中最少的,分别比次优方法减少了 57% 和 26%。这得益于其将反思与行动规划整合在单次 LLM 调用中的高效设计。
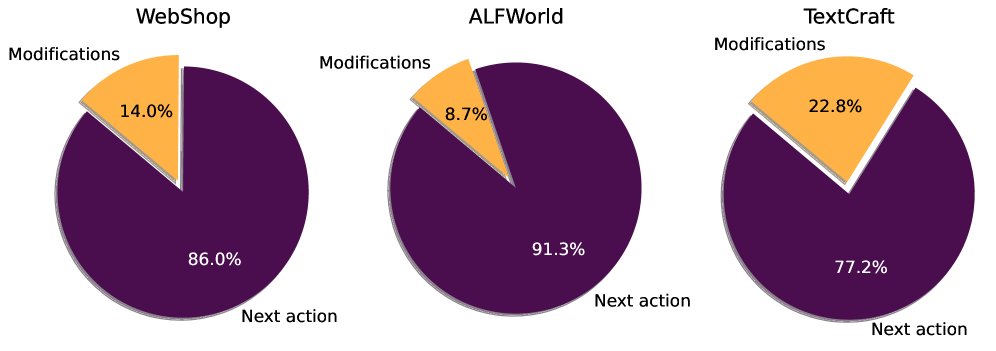
需要多少次修改?
对 REBACT 的内部行为分析发现,用于“修改错误动作”的 LLM 调用比例并不高,在 ALFWorld 上为 8.7%,在 TextCraft 上最高也仅为 22.8%。这说明 LLM 能够有效地适应环境的细微变化,大部分情况下都能做出正确的决策,而纠错机制作为一种高效的“安全网”,在关键时刻发挥作用,而不需要频繁地进行大规模修正。
总结
本文提出的 REBACT 是一种简单而强大的迭代式自反思策略。它通过在执行下一步动作前反思和修正历史动作,显著提升了 LLM 智能体在多种交互式决策任务中的成功率,并且表现出很高的计算效率。这一成果凸显了赋予 LLM 在获得环境反馈后进行自我反思能力的巨大潜力。
局限性
- 并非所有动作都可修改:REBACT 依赖于 LLM 能够检测并纠正错误,但现实世界中的许多动作是不可逆的(例如,发送了的电子邮件无法撤回并编辑)。在应用时,需要谨慎识别哪些动作是可修改的,并为不可逆动作设计合适的补救策略(如发送一封勘误邮件)。
- 依赖环境反馈:REBACT 的有效性取决于能否从环境中获得有助于其反思过程的反馈。在缺乏明确或及时反馈的场景下,其纠错能力可能会受到限制。