Reflexion: Language Agents with Verbal Reinforcement Learning
-
ArXiv URL: http://arxiv.org/abs/2303.11366v4
-
作者: Karthik Narasimhan; Shunyu Yao; Federico Cassano; Beck Labash; A. Gopinath; Noah Shinn
-
发布机构: Massachusetts Institute of Technology; Northeastern University; Princeton University
TL;DR
本文提出 Reflexion 框架,通过让语言智能体对过去的试错经验进行口头反思(verbal reflection)并形成文本记忆,从而在无需更新模型权重的情况下实现强化学习,显著提升了其在决策、推理和编程等任务上的表现。
关键定义
本文的核心是 Reflexion 框架,它由几个关键概念组成:
-
Reflexion: 一种新颖的框架,用于通过“口头强化学习 (verbal reinforcement learning)”来增强语言智能体。它不通过更新模型权重,而是通过语言反馈来学习。智能体会对任务的反馈信号进行口头反思,并将这些反思内容保存在一个情节记忆(episodic memory)中,以指导后续的尝试。
- 三模型结构: Reflexion 框架由三个协同工作的模型组成:
- 行动者 (Actor, $M_a$): 基于一个大语言模型(LLM),负责根据当前状态和记忆生成文本和行动。
- 评估者 (Evaluator, $M_e$): 负责评估行动者产生的轨迹(trajectory)的质量,并给出一个奖励分数。评估者可以是基于规则的启发式方法、精确匹配检查,甚至是另一个 LLM。
- 自我反思模型 (Self-Reflection Model, $M_{sr}$): 同样是一个 LLM,它接收行动轨迹和评估分数,并生成一段自然的、可操作的文本反馈。这段反馈会总结失败的原因并提出改进建议。
-
口头强化 (Verbal Reinforcement): Reflexion 的核心机制。它将来自环境的稀疏反馈信号(如二进制的成功/失败或标量分数)“放大”为一段内容丰富的自然语言反思。这段反思文本作为一种“语义梯度”,为智能体在下一轮尝试中提供了具体的改进方向。
- 情节记忆 (Episodic Memory): 用于存储自我反思模型生成的文本。在每一次新的尝试中,行动者会把这些储存在长期记忆中的反思内容作为额外的上下文,从而借鉴过去的经验教训。
相关工作
当前,利用大型语言模型(LLM)作为核心来构建与外部环境(如游戏、编译器、API)交互的自主智能体已成为一个热门研究方向(例如 ReAct, SayCan, Toolformer)。然而,这些语言智能体在通过试错法学习时面临巨大挑战。传统的强化学习(RL)方法通常需要大量的训练样本和昂贵的模型微调(fine-tuning),这对于参数量巨大的LLM来说是不切实际的。现有的方法大多依赖于上下文学习(in-context learning),但缺乏一种高效的、从失败中快速学习的机制。
一些相关工作尝试解决类似问题,但存在局限:
- Self-Refine: 可以通过自我评估来迭代式地改进单次生成任务,但无法应用于需要多步决策的序列任务。
- 编程领域的自调试方法 (Self-Debugging, CodeRL): 通常依赖于真实(ground truth)的测试用例来发现错误,或者在没有深刻自我反思的情况下进行盲目试错。
本文旨在解决的核心问题是:如何让语言智能体能够在几次尝试内,像人类一样通过反思过去的失败来高效地学习和改进,而无需进行计算成本高昂的模型权重更新。
本文方法
 图注:(a) Reflexion示意图。(b) Reflexion强化算法流程
图注:(a) Reflexion示意图。(b) Reflexion强化算法流程
本文提出的 Reflexion 框架通过模拟人类的反思学习过程,实现了一种轻量级但高效的“口头强化学习”。其核心在于将稀疏的外部反馈转化为丰富的语言文字指导,并存储于记忆中以备后续使用。
模块化设计
Reflexion 包含三个核心模型:
-
行动者 (Actor, $M_a$): 一个 LLM,其策略 $\pi_{\theta}(a_t \mid s_t)$ 由 LLM 本身和记忆 \(mem\) 共同参数化,即 $\theta={M_a, mem}$。它根据当前状态和短期记忆(当前轨迹)与长期记忆(反思文本)来生成行动 $a_t$。
- 评估者 (Evaluator, $M_e$): 对行动者生成的完整轨迹 $\tau$ 进行打分。这个评估器可以是多样的:
- 对于推理任务,可以使用精确匹配(EM)来判断答案是否正确。
- 对于决策任务,可以使用预定义的启发式规则(例如,是否在原地打转、行动步数是否过多)。
- 对于编程任务,可以利用编译器或自生成的单元测试来判断代码的正确性。
- 自我反思模型 (Self-Reflection Model, $M_{sr}$): 这是 Reflexion 的关键。它也是一个 LLM,接收行动轨迹 $\tau_t$ 和评估分数 $r_t$ 作为输入,然后生成一段反思文本 $sr_t$。这段文本会分析失败的原因,并提出具体的改进策略。例如,“我不应该在第 i 步执行动作 a,而应该尝试动作 a’,因为 a 导致了后续的一系列错误。”
Reflexion 流程
该过程是一个迭代循环,如算法1所示:
- 首次尝试: 行动者在没有长期记忆的情况下生成初始轨迹 $\tau_0$。
- 评估: 评估者对 $\tau_0$ 进行评分,得到标量奖励 $r_0$。
- 反思: 自我反思模型分析 ${\tau_0, r_0}$,生成一段反思文本 $sr_0$。
- 记忆存储: 将反思文本 $sr_0$ 添加到长期记忆 \(mem\) 中。为避免上下文窗口过长,记忆通常只保留最近的 N 次(例如1-3次)反思。
- 后续尝试: 在第 $t$ 次尝试中,行动者将结合长期记忆 \(mem\) 中的所有反思内容作为上下文,生成新的轨迹 $\tau_t$。
- 循环: 重复步骤 2-5,直到任务成功或达到最大尝试次数。
核心创新与优点
-
创新点: 本文最核心的创新在于提出了 口头强化 (Verbal Reinforcement) 的概念。它将传统 RL 中难以进行信用分配的稀疏标量奖励,转化为对 LLM 友好、信息密集的自然语言反馈。这种反馈就像一种“语义梯度”,直接指导模型在下一次迭代中应该如何调整其行为。
-
优点:
- 轻量级: 无需微调 LLM 参数,显著降低了计算成本和训练时间。
- 反馈信息丰富: 相比标量奖励,语言反馈能更精确地指出错误所在和改进方向。
- 记忆可解释性强: 长期记忆由自然语言构成,使得智能体的学习过程和“心路历程”变得透明且易于理解。
- 提供明确指引: 反思内容为智能体在未来决策时提供了明确的“启发式线索”。
 图注:Reflexion 框架可应用于决策、编程和推理等多种任务。
图注:Reflexion 框架可应用于决策、编程和推理等多种任务。
实验结论
本文在决策、推理和编程三大类任务上验证了 Reflexion 框架的有效性,结果表明 Reflexion 智能体在多个基准测试中均显著优于强大的基线模型。
顺序决策任务 (ALFWorld)
- 任务: 在模拟家居环境中完成多步复杂指令(如“把番茄放进冰箱冷藏”)。
- 结果: Reflexion Agent(使用 ReAct 作为 Actor)在134个任务中成功完成了130个(成功率97%),相比仅使用 ReAct 的基线(成功率75%)提升了22%。基线模型在尝试6-7次后性能停滞,而 Reflexion 能在12次尝试中持续学习并解决更多任务。
- 分析: Reflexion 能够有效解决基线模型常见的“幻觉”问题(例如,智能体以为自己拿起了某个物体,但实际上没有)。通过反思,智能体能定位长轨迹中早期的关键错误,或在多次尝试中系统地探索复杂的环境,避免了重复无效操作。
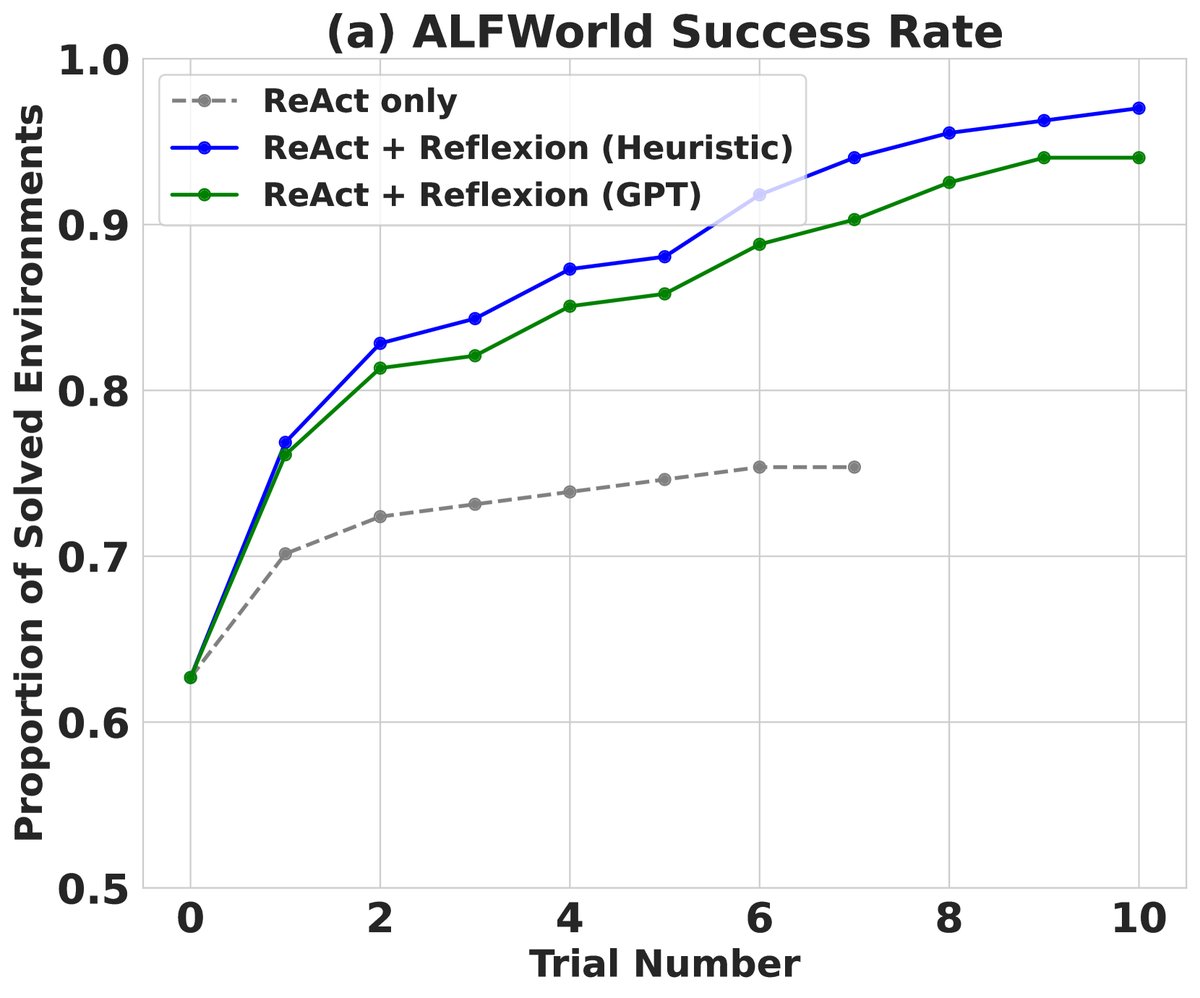
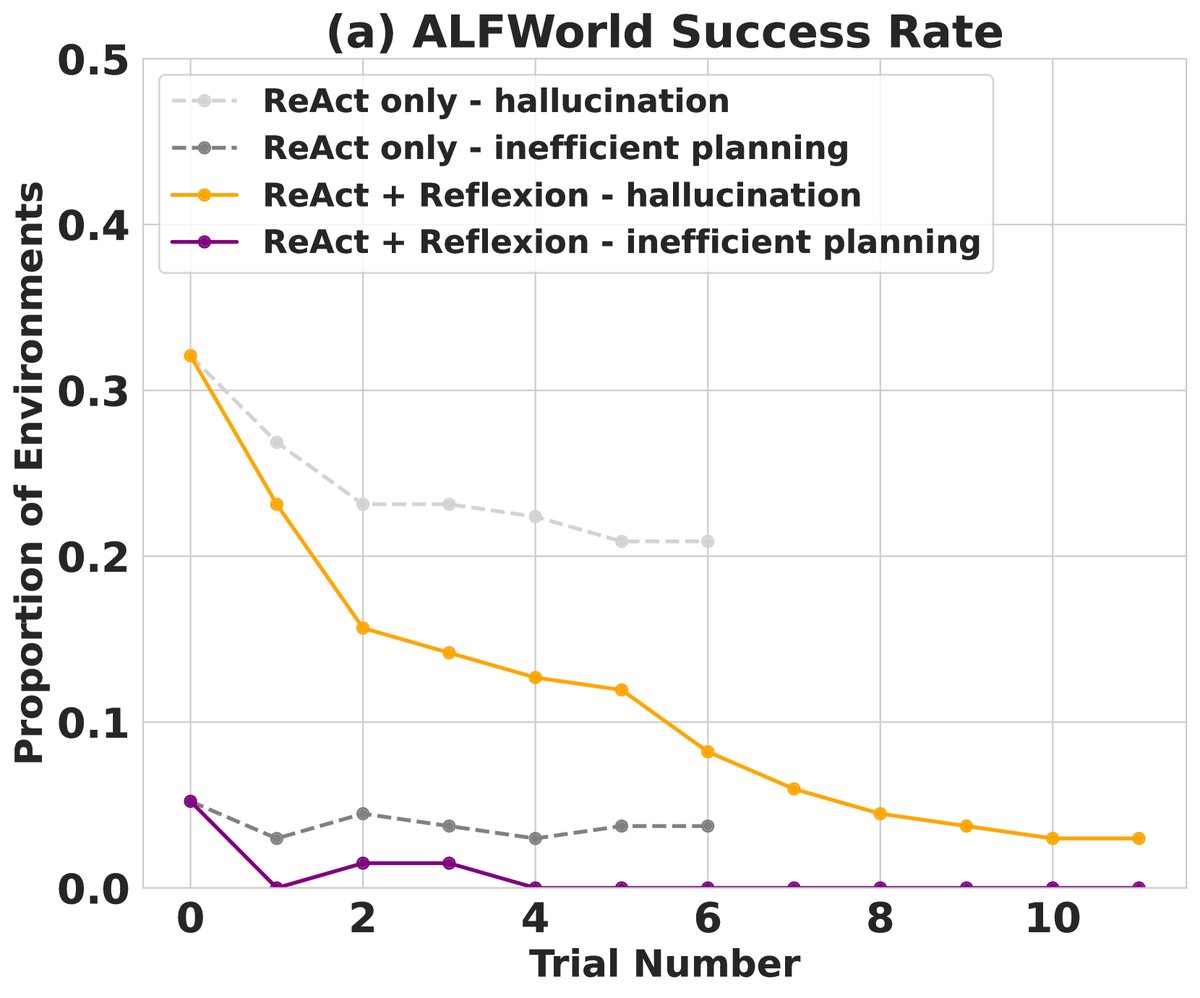 图注:(a) Reflexion 在 ALFWorld 任务上随尝试次数增加的性能表现优于基线。 (b) Reflexion 显著减少了因幻觉和低效规划导致的失败。
图注:(a) Reflexion 在 ALFWorld 任务上随尝试次数增加的性能表现优于基线。 (b) Reflexion 显著减少了因幻觉和低效规划导致的失败。
推理任务 (HotpotQA)
- 任务: 基于维基百科的多跳问答,测试智能体的推理能力。
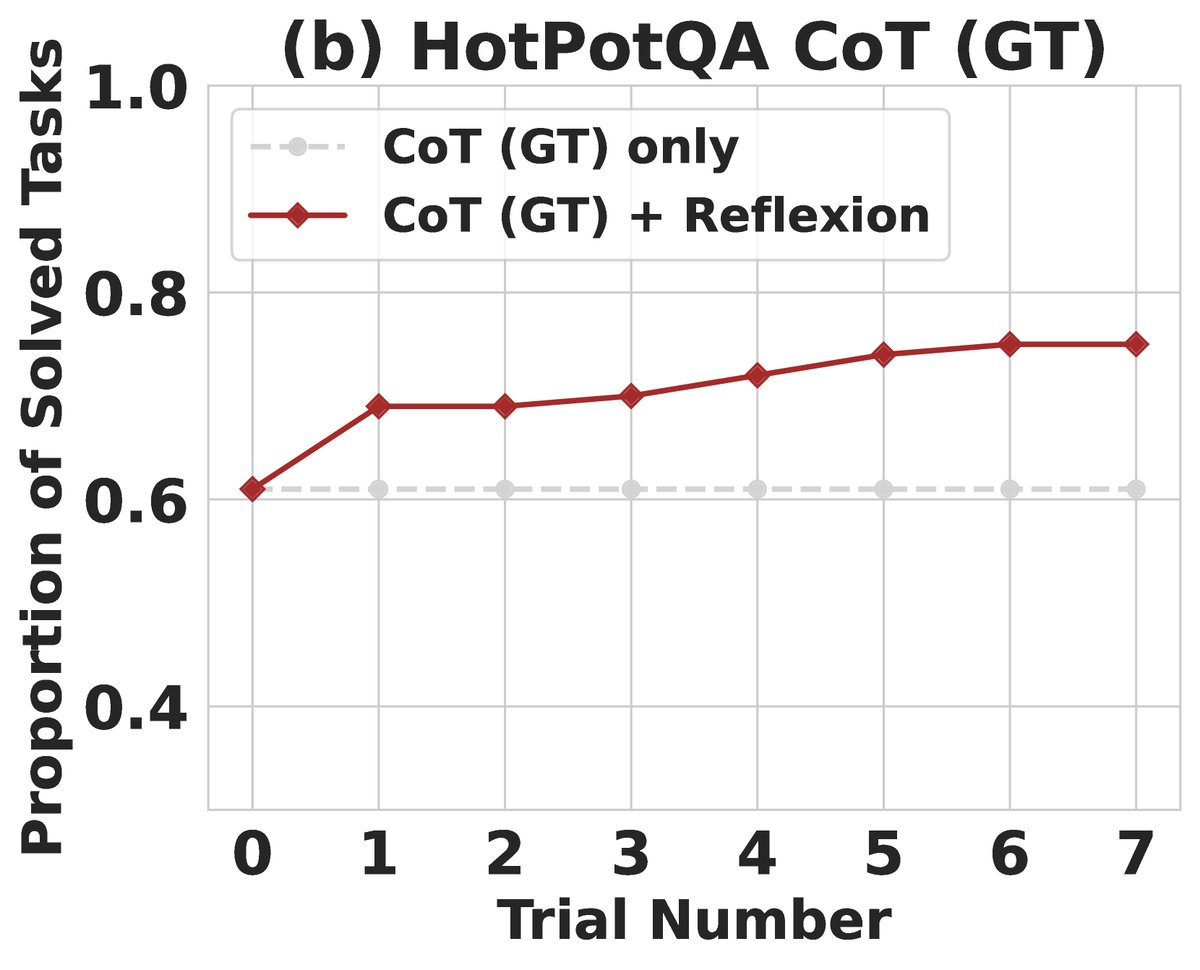
- 结果: 在只提供标准上下文的纯推理任务上(CoT (GT)),Reflexion 将准确率从61%提升至75%(提升14%)。在需要自行搜索信息的完整任务上(ReAct),Reflexion 将准确率从23%提升至43%(提升20%)。
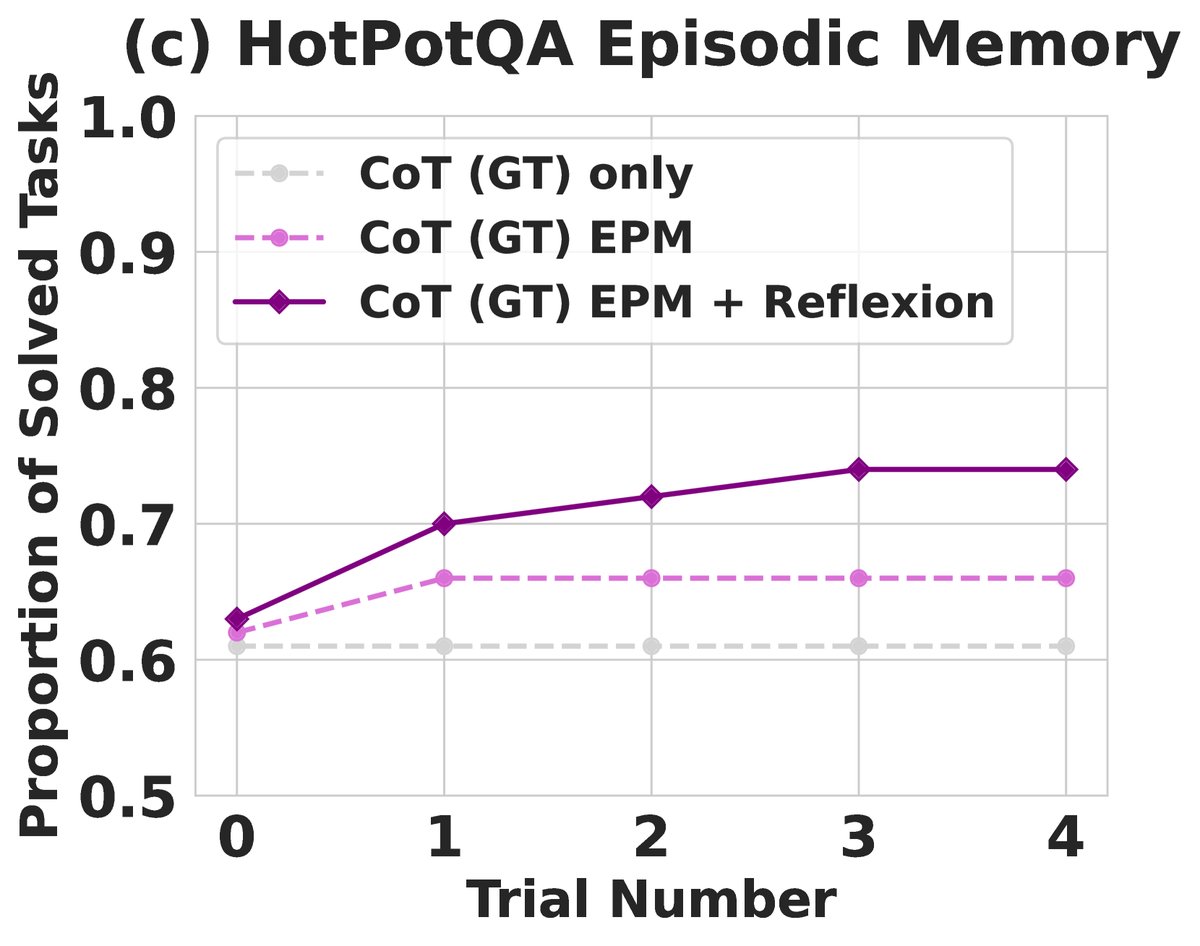
- 分析: 消融实验表明,Reflexion 的优势不仅仅来自于记忆。相比只把前一次失败的轨迹作为上下文(Episodic Memory),明确生成“反思文本”能带来额外 8% 的绝对性能提升。这证明了将经验提炼成第一人称的语言教训,比简单地重复“观看”失败案例更有效。

编程任务 (HumanEval, MBPP等)
- 任务: 根据自然语言描述生成 Python 和 Rust 代码。评估方式为 pass@1 准确率。
- 结果: Reflexion 在多个编程基准上刷新了SOTA。尤其是在 HumanEval (Python) 上,取得了 91.0% 的 pass@1 准确率,远超同期最先进的 GPT-4 基线(80.1%)。
- 表现平平的场景: 在 MBPP (Python) 数据集上,Reflexion (77.1%) 略逊于 GPT-4 基线 (80.1%)。分析表明,这是因为在该任务上,模型自生成的单元测试质量不高,导致了16%的“假阳性”(代码通过了自生成测试,但实际上是错的),从而提前终止了改进过程。这说明 Reflexion 的性能与其评估模块(在此为自生成单元测试)的质量高度相关。
| 基准 + 语言 | 先前 SOTA Pass@1 | SOTA Pass@1 | Reflexion Pass@1 |
|---|---|---|---|
| HumanEval (PY) | 65.8 (CodeT + GPT-3.5) | 80.1 (GPT-4) | 91.0 |
| HumanEval (RS) | – | 60.0 (GPT-4) | 68.0 |
| MBPP (PY) | 67.7 (CodeT + Codex) | 80.1 (GPT-4) | 77.1 |
| MBPP (RS) | – | 70.9 (GPT-4) | 75.4 |
| Leetcode Hard (PY) | – | 7.5 (GPT-4) | 15.0 |
表1: 不同模型和策略组合在编程任务上的 Pass@1 准确率。
| 基准 + 语言 | 基线 | Reflexion | TP | FN | FP | TN |
|---|---|---|---|---|---|---|
| HumanEval (PY) | 0.80 | 0.91 | 0.99 | 0.40 | 0.01 | 0.60 |
| MBPP (PY) | 0.80 | 0.77 | 0.84 | 0.59 | 0.16 | 0.41 |
| HumanEval (RS) | 0.60 | 0.68 | 0.87 | 0.37 | 0.13 | 0.63 |
| MBPP (RS) | 0.71 | 0.75 | 0.84 | 0.51 | 0.16 | 0.49 |
表2: 总体准确率和单元测试生成性能分析。FP (假阳性) 率过高会损害 Reflexion 性能。
| 方法 | 测试生成 | 自我反思 | Pass@1 (Acc) |
|---|---|---|---|
| 基线模型 | 否 | 否 | 0.60 |
| 省略测试生成 | 否 | 是 | 0.52 |
| 省略自我反思 | 是 | 否 | 0.60 |
| Reflexion | 是 | 是 | 0.68 |
表3: 在 HumanEval Rust 上的消融研究,证明了测试生成和自我反思两个组件缺一不可。
最终结论
Reflexion 是一种有效且通用的方法,它通过口头强化学习,使语言智能体能够从过去的错误中高效学习,而无需进行昂贵的模型微调。实验证明,这种通过自我反思提炼经验并指导未来行动的机制,能够显著提升智能体在决策、推理和编程等一系列复杂任务上的性能。