Reinforcement Learning for Machine Learning Engineering Agents
-
ArXiv URL: http://arxiv.org/abs/2509.01684v1
-
作者: Percy Liang; Joy He-Yueya; Sherry Yang
-
发布机构: Stanford University
TL;DR
本文证明,通过强化学习(RL)对一个较小的语言模型(如 Qwen2.5-3B)进行梯度更新,可以在机器学习工程(MLE)任务中超越比它大得多的静态模型(如 Claude-3.5-Sonnet),其核心贡献是提出了两种关键技术来克服RL在智能体(Agent)设置中的挑战:时长感知梯度更新(duration-aware gradient updates)用于处理执行时间可变的操作,以及环境检测(environment instrumentation)用于提供部分信誉(partial credit)以解决奖励稀疏问题。
关键定义
本文提出了以下核心概念来改进应用于机器学习工程智能体的强化学习:
- 时长感知梯度更新 (Duration-aware gradient updates):这是一种修正后的策略梯度更新规则。在异步分布式RL中,执行时间短的动作会更快地完成并产生更多的梯度更新,导致策略偏向于快速但次优的解决方案。该方法通过将每次梯度更新乘以相应动作的执行时长 \(Δt\) 来加权,从而抵消这种频率偏差,确保耗时长但奖励高的动作在策略更新中得到应有的重视。
- 环境检测 (Environment instrumentation):这是一种为解决奖励稀疏问题而设计的技术。它使用一个独立的、静态的语言模型来自动向智能体生成的代码中插入可验证的 \(print\) 语句,用以追踪关键步骤(如数据加载、模型训练、推理)的执行进度。通过检查这些打印输出是否出现,系统可以为智能体提供部分信誉(partial credit),从而将几乎正确的程序与早期失败的程序区分开,为学习提供更密集的奖励信号。
- 部分信誉 (Partial credit):作为环境检测的直接产物,这是一种中间奖励机制。它奖励智能体完成任务过程中的各个子步骤,而不是仅在任务最终成功时才给予奖励。这有效引导智能体逐步学习,避免因最终奖励过于稀疏而陷入局部最优或无法学习。
相关工作
当前的机器学习工程(MLE)智能体主要依赖于通过提示(prompting)强大的大型语言模型(LMs)来解决任务。尽管使用更复杂的智能体框架或增加推理时间可以在一定程度上提升性能,但这些智能体是静态的,无法从收集到的经验中通过梯度更新来根本性地改进自身能力。
本文旨在解决将强化学习(RL)应用于MLE智能体时遇到的两大关键瓶颈:
- 可变时长的动作执行:MLE任务中,智能体生成的不同代码(动作)执行时间差异巨大(例如,训练不同模型)。在标准的异步分布式RL框架中,这会导致策略不成比例地偏爱执行速度快但性能较差的解决方案,因为它们能更快地产生训练样本和梯度。
- 奖励信号稀疏:仅使用最终测试集表现作为奖励,反馈非常有限。一个在最后一步才出错的程序和一个从一开始就无法加载数据的程序得到的奖励可能完全相同(通常为零)。这使得智能体难以学习完成复杂的多步骤任务,甚至可能学会“钻空子”(例如,直接利用评估函数特性绕过机器学习建模)。
本文方法
为了解决上述挑战,本文提出了一套针对MLE智能体的强化学习框架,其核心是时长感知梯度更新和环境检测。智能体还可以通过自我改进的提示进行多步优化。

图4:提出的框架概览。时长感知梯度更新根据动作的执行时长对策略梯度更新进行重加权。环境检测使用一个静态LM插入print语句,其执行输出可被提取为部分信誉。智能体可以被进一步要求改进先前的解决方案,其响应可进一步通过RL进行加强。
时长感知梯度更新
在异步分布式RL中,由于智能体生成的不同代码方案执行时间\(Δt\)不同,一个动作在单位时间内的梯度贡献与其执行时间成反比,导致对快速动作的偏好。
为纠正此偏差,本文提出按动作执行时长\(Δt_k\)对每次策略梯度更新进行加权。新的策略梯度更新法则如下:
\[\nabla_{\theta}J(\pi_{\theta})=E_{\pi,\mu,\mathcal{P}}\left[\sum_{k=0}^{K}\Delta t_{k}\cdot\nabla_{\theta}\log\pi_{\theta}(a_{k} \mid s_{k})\cdot\hat{A}(s_{k},a_{k})\right]\]其中,\(Δt_k\)是动作 \(a_k\) 的执行时长,\(A_hat(s_k, a_k)\)是优势估计。通过引入\(Δt_k\),每个动作对梯度更新的贡献与其执行频率解耦,确保了耗时长但高回报的动作(如训练更复杂的模型)也能被有效学习。实践中,为避免梯度过大,会使用批次内的平均执行时间对\(Δt_k\)进行缩放。
环境检测以提供部分信誉
为了应对稀疏奖励问题,本文设计了一种提供中间奖励(即“部分信誉”)的机制。该机制通过一个独立的、静态的语言模型(a separate static copy of the original LM)来实现,它负责“检测”智能体生成的代码。
具体流程如下:
- 代码插入:在执行智能体生成的代码前,一个辅助LM会向代码中插入用于追踪进度的 \(print\) 语句,例如标记“数据加载完成”、“模型构建完成”等关键节点。
- 执行与解析:执行被修改后的代码。
- 奖励分配:通过正则表达式匹配终端输出,检查哪些 \(print\) 语句被成功执行。每成功一个节点,就给予一个小的正向奖励(例如+0.1)。完全失败的程序则获得一个大的负奖励(例如-10)。如果程序成功运行并生成了提交文件,则使用真实的竞赛得分作为最终奖励。
使用一个独立的静态LM至关重要,这可以防止正在学习的智能体为了获得部分信誉而“作弊”,即只生成\(print\)语句而不执行实际任务。
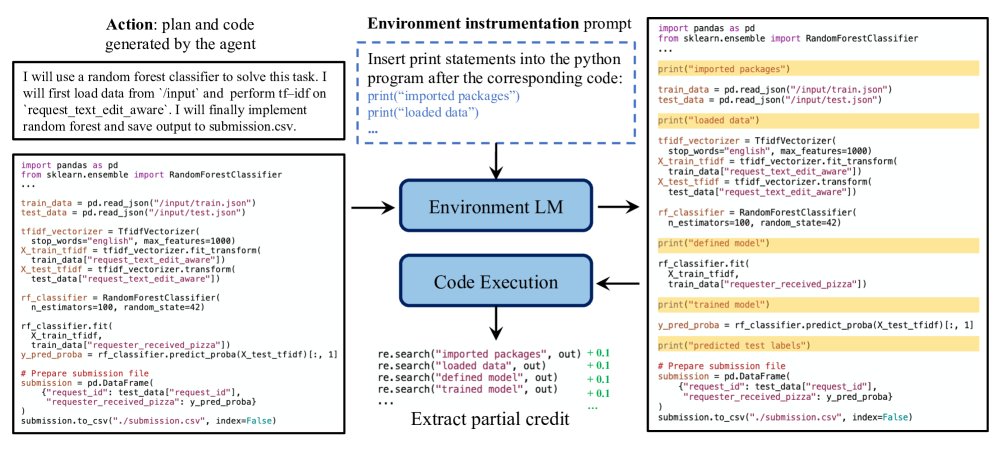
图5:环境检测概览。另一个小型LM(Qwen2.5-3B)的副本被提示向智能体生成的代码中插入print语句。代码执行后,终端输出被解析,通过正则表达式匹配来分配部分信誉。
结合自我改进提示的多步强化学习
本文还探索了让智能体进行自我改进的能力。在训练过程中,以50%的概率随机选择两种提示之一:
- 从零开始解决任务。
- 改进已有方案:向智能体提供一个先前生成的解决方案及其执行输出(包括来自环境检测的训练/测试准确率等信息),并要求它进行改进。
在测试时,模型首先从零开始生成一个解决方案,然后再运行一次以改进该方案,最终选择两者中表现更好的一个。
实验结论
本文在MLEBench的一个包含12个Kaggle任务的子集上进行了实验,将RL训练的小模型(Qwen2.5-3B)与依赖提示工程的大模型(如Claude-3.5-Sonnet, GPT-4o)进行了对比。
核心发现
-
小模型RL超越大模型提示:经过RL训练后,Qwen2.5-3B在12个任务中的8个上取得了比所有前沿大模型(Llama3.1-405B, Claude-3.5-Sonnet, GPT-4o)更好的最终性能。与Claude-3.5-Sonnet相比,平均性能提升了22%。
-
优于不同智能体框架:RL训练的Qwen2.5-3B在12个任务中的9个上,表现超过了使用不同智能体框架(AIDE, OpenHands, MLAB)的GPT-4o。
-
学习曲线对比:尽管在训练初期,大模型的表现远超小模型,但随着RL训练的进行,小模型的性能通过梯度更新持续提升,并最终超越了大模型。这表明梯度更新是一种比纯提示更有效的长期改进路径。
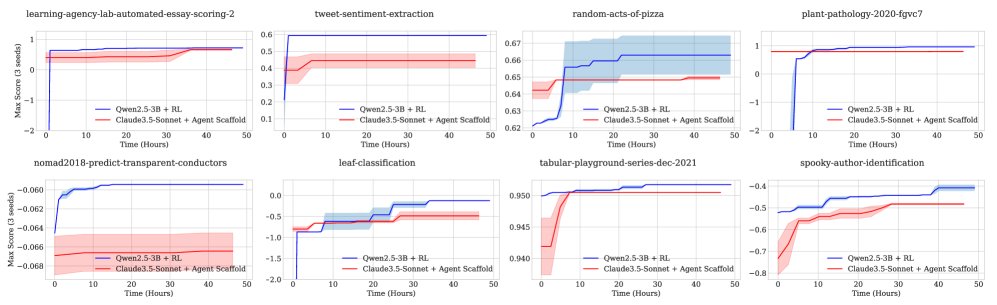
图7:智能体在不同时间点取得的最佳分数对比。运行RL的小模型在许多任务上起初得分较低,但最终表现超过了提示大模型。
消融研究
| 任务 | GPT-4o AIDE | GPT-4o OpenHands | GPT-4o MLAB | Qwen2.5-3B RL |
|---|---|---|---|---|
| detecting-insults-in-social-commentary ($\uparrow$) | NaN | 0.867 +/- 0.017 | 0.749 +/- 0.039 | 0.895 +/- 0.001 |
| learning-agency-lab-automated-essay-scoring-2 ($\uparrow$) | 0.720 +/- 0.031 | 0.681 +/- 0.010 | 0.533 +/- 0.080 | 0.746 +/- 0.002 |
| random-acts-of-pizza ($\uparrow$) | 0.645 +/- 0.009 | 0.591 +/- 0.048 | 0.520 +/- 0.013 | 0.663 +/- 0.011 |
| tweet-sentiment-extraction($\uparrow$) | 0.294 +/- 0.032 | 0.415 +/- 0.008 | 0.158 +/- 0.057 | 0.596 +/- 0.002 |
| tabular-playground-series-may-2022 ($\uparrow$) | 0.884 +/- 0.012 | 0.882 +/- 0.030 | 0.711 +/- 0.050 | 0.913 +/- 0.000 |
| tabular-playground-series-dec-2021 ($\uparrow$) | 0.957 +/- 0.002 | 0.957 +/- 0.000 | 0.828 +/- 0.118 | 0.951 +/- 0.000 |
| us-patent-phrase-to-phrase-matching ($\uparrow$) | 0.756 +/- 0.019 | 0.366 +/- 0.039 | NaN | 0.527 +/- 0.003 |
| plant-pathology-2020-fgvc7 ($\uparrow$) | 0.980 +/- 0.002 | 0.680 +/- 0.113 | 0.735 +/- 0.052 | 0.970 +/- 0.004 |
| leaf-classification ($\downarrow$) | 0.656 +/- 0.070 | 0.902 +/- 0.018 | 4.383 +/- 2.270 | 0.124 +/- 0.000 |
| nomad2018-predict-transparent-conductors ($\downarrow$) | 0.144 +/- 0.031 | 0.183 +/- 0.120 | 0.294 +/- 0.126 | 0.059 +/- 0.000 |
| spooky-author-identification ($\downarrow$) | 0.576 +/- 0.071 | 0.582 +/- 0.020 | 0.992 +/- 0.463 | 0.404 +/- 0.011 |
| lmsys-chatbot-arena ($\downarrow$) | 1.323 +/- 0.147 | 1.131 +/- 0.019 | 10.324 +/- 4.509 | 1.081 +/- 0.002 |
- 时长感知梯度的效果:该机制使智能体能够探索执行时间更长但回报更高的解决方案(如梯度提升树),而没有该机制的训练则会收敛到快速但次优的方案(如线性逻辑回归)。
- 环境检测的效果:该机制显著加速了RL训练的收敛速度,并提高了训练的稳定性,因为它提供的部分信誉帮助智能体更快地克服了初始的障碍(如数据加载失败)。
- 自我改进提示的效果:与仅从零解决任务相比,加入自我改进提示的训练在10/12个任务中取得了更好的最终性能,平均提升了8%。
最终结论
实验结果有力地表明,对于像机器学习工程这样动作执行成本不容忽视的复杂任务,将计算资源用于对小模型进行强化学习训练,是一种比单纯依赖大模型提示更为有效的自适应和性能提升策略。