ReST-RL: Achieving Accurate Code Reasoning of LLMs with Optimized Self-Training and Decoding
-
ArXiv URL: http://arxiv.org/abs/2508.19576v1
-
作者: Dan Zhang; Jie Tang; Yuxiao Dong; Sining Zhoubian
-
发布机构: Tsinghua University
TL;DR
本文提出了一种名为 ReST-RL 的统一强化学习范式,通过将优化的自训练算法 (ReST-GRPO) 与基于价值模型 (Value Model) 的蒙特卡洛树搜索解码方法 (VM-MCTS) 相结合,显著提升了大型语言模型 (LLM) 在代码推理任务上的准确性。
关键定义
- ReST-RL: 本文提出的统一强化学习框架,由两个核心组件构成:ReST-GRPO 用于策略模型训练,VM-MCTS 用于测试时解码优化。
- ReST-GRPO (Reinforced Self-Training with Group Relative Policy Optimization): 一种新颖的 LLM 强化学习算法。它通过一种优化的 Reinforced Self-Training (ReST) 机制来筛选和组装高价值的训练数据,旨在解决传统 GRPO 算法中因奖励方差不足而导致的训练效果不佳问题。
- 价值模型 (Value Model, VM): 本文定义的一种奖励模型。与评估中间步骤正确与否的过程奖励模型 (Process Reward Model, PRM) 不同,VM 旨在预测从一个给定的中间状态(即部分生成的解)出发,遵循当前策略最终能获得的期望奖励值。
- VM-MCTS (Value Model based Monte-Carlo Tree Search): 一种在测试时使用的解码和验证方法。它首先利用 MCTS 搜集数据训练一个 VM,然后在解码时,利用这个 VM 指导 MCTS 的搜索过程,从而更高效地找到高质量的解,并对最终输出进行验证。
相关工作
当前提升 LLM 推理能力的方法主要分为两类:模型训练和解码优化。
在模型训练方面,在线强化学习算法如 Group Relative Policy Optimization (GRPO) 虽然被提出,但常因奖励信号的方差过小而导致训练效果不理想。自训练方法如 Reinforced Self-Training (ReST) 虽能缓解数据问题,但与 RL 的结合仍有探索空间。
在解码优化与验证方面,过程奖励模型 (Process Reward Models, PRM) 比结果奖励模型 (Outcome Reward Models, ORM) 更精确,但其训练需要大量高质量、高成本的人工标注过程数据。一些方法试图通过蒙特卡洛模拟来自动收集数据,但存在泛化能力不足和噪声较大的问题。
本文旨在解决这些问题,提出一个统一框架 ReST-RL,它能够在保证低成本、高效率和良好泛化性的同时,有效提升 LLM 的推理能力。
本文方法
本文提出的 ReST-RL 范式包含两个阶段:首先通过 ReST-GRPO 提升策略模型的基础推理能力,然后通过 VM-MCTS 在测试时进一步优化解码,提升最终答案的准确率。
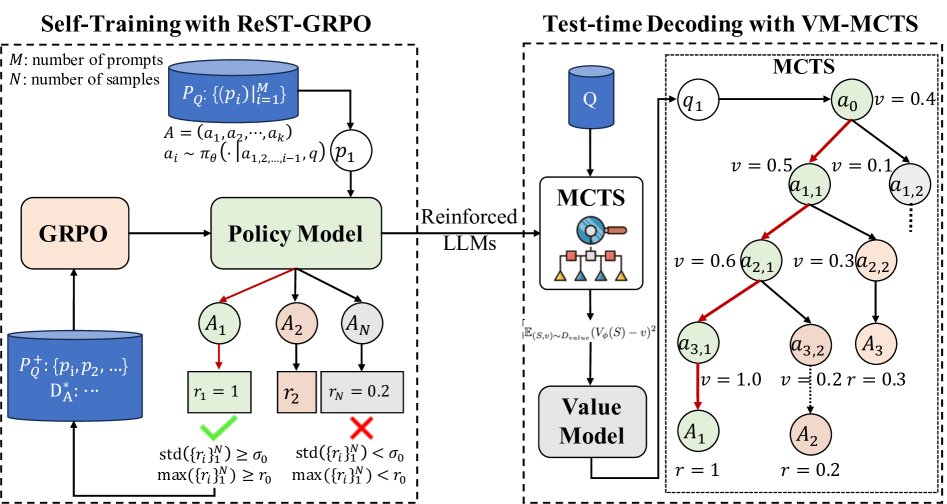
任务设定
本文将代码生成过程视为一个马尔可夫过程。LLM 策略 $\pi_{\theta}$ 根据问题 $q$ 和已生成的部分解 $a_{1,…,i-1}$ 来生成下一个动作 $a_i$(在这里一个动作定义为一行代码)。一个中间状态 $S_i$ 由问题和部分解构成,即 $S_i=(q, a_{1,…,i})$。奖励 $R$ 仅在生成完整解的终止状态 $S_{end}$ 时给出。一个状态的价值函数 $V^{\pi}(S_i)$ 定义为从该状态出发,遵循策略 $\pi$ 所能获得的期望奖励:
\[V^{\pi}(S_{i})=\mathbb{E}_{\pi}[R(S_{end}) \mid S_{i}].\]ReST-GRPO
ReST-GRPO 是一种迭代式的策略增强算法,通过巧妙的数据采样和过滤机制,解决了 GRPO 训练中的奖励方差过低问题,从而提升了训练的效率和效果。
创新点
其核心创新在于训练数据的筛选和组装过程:
-
基于奖励方差的过滤:对于每个训练问题,首先用当前策略采样 $N$ 个解并计算各自的奖励。如果这组奖励的标准差小于阈值 $\sigma_0$,说明模型在该问题上的表现区分度不大,难以提供有效的学习信号,因此将该问题从本轮训练中过滤掉。
-
基于高价值轨迹的数据组装:对于未被过滤的问题,如果其最高奖励超过阈值 $r_0$,则认为其最高分轨迹是“有价值的”。算法会从这个最高分轨迹中提取所有的部分解状态 (partial solution states)。然后,通过一个指数概率分布(公式3)对这些部分解进行采样,将它们与原问题拼接成新的训练实例。这种方法使得模型在训练时可以从更有希望的中间状态开始探索,从而更容易学习到通往高分答案的路径。
\[p(a_{1,2,\dots,j})=\frac{1-\alpha}{1-\alpha^{ \mid A \mid }}\alpha^{j-1},j=1,2,\dots, \mid A \mid\]
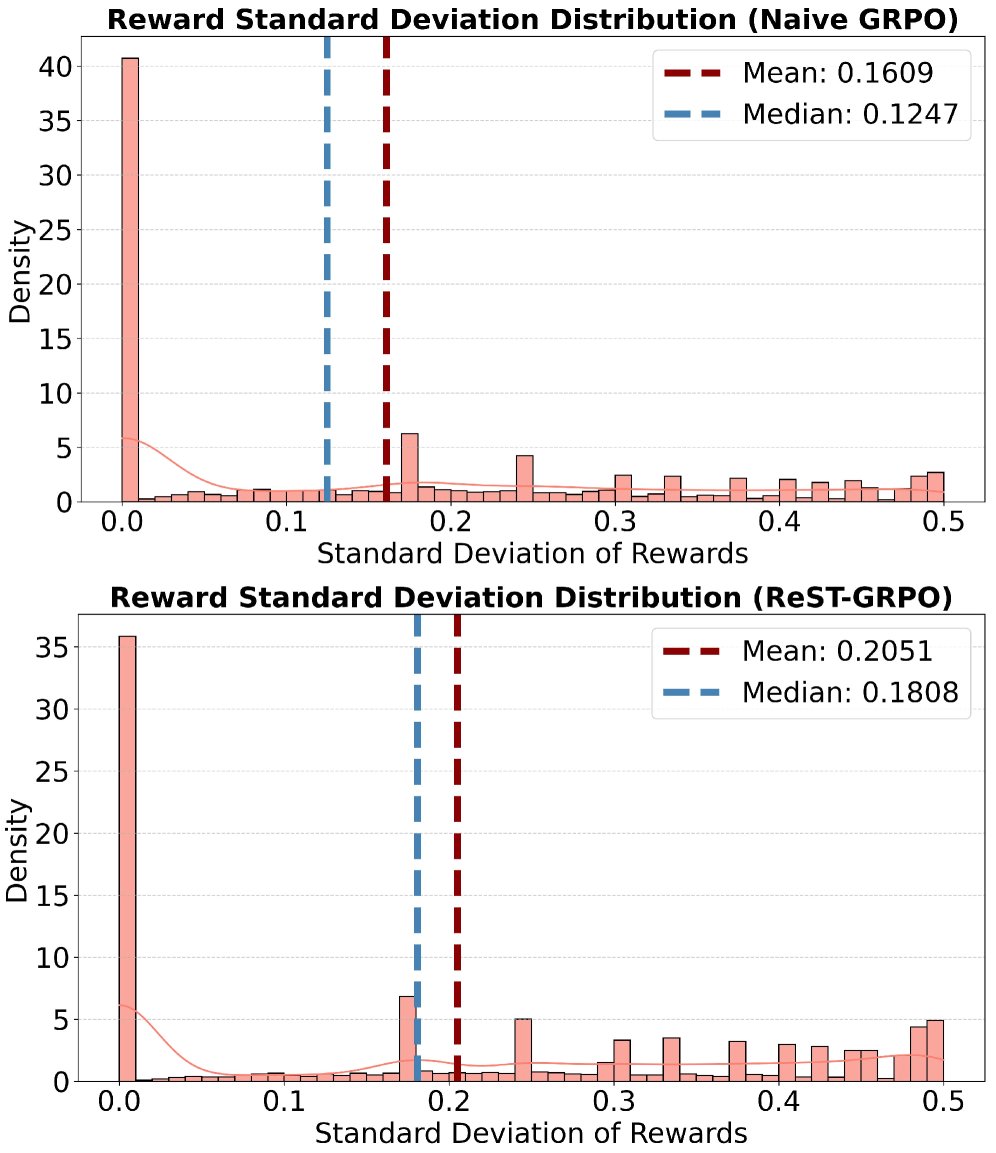
通过上述机制,ReST-GRPO 显著增加了训练数据中奖励的差异性(如下图所示),使得 GRPO 的更新信号更加明确和有效。
最后,使用组装好的高质量数据集,通过标准的 GRPO 目标函数(公式4)进行在线强化学习训练。
VM-MCTS
在策略模型通过 ReST-GRPO 得到增强后,VM-MCTS 在测试解码阶段提供进一步的性能提升。它分为价值模型训练和辅助解码两个步骤。
价值模型训练
-
价值目标定义:VM 的目标是学习状态的价值函数 $V^{\pi}(S_i)$,即预测从一个部分解状态出发的期望最终奖励。这比传统 PRM 评估单步操作正确性更具前瞻性。
-
数据收集与训练:使用蒙特卡洛树搜索 (MCTS) 算法,在不需要人工标注的情况下,通过对不同代码路径进行模拟和探索,来精确估计各个中间状态的价值。通过这种方式收集大量的 \((状态, 价值)\) 数据对,然后训练一个价值模型 $V_{\phi}$ 来拟合这些数据,其损失函数为:
\[\mathcal{L}_{\phi}=\mathbb{E}_{(S,v)\sim D_{value}}(V_{\phi}(S)-v)^{2}\]
辅助解码
在测试阶段,使用一个适配的 MCTS 算法进行解码。这个 MCTS 搜索过程由训练好的 VM 进行引导:
- 指导搜索:VM 提供的价值估计被用于 MCTS 的选择和扩展阶段,指导搜索树优先探索更有潜力的代码路径,提高了搜索效率。
- 最终验证:搜索结束后,VM 还可以像 PRM 一样,对 MCTS 生成的多个候选解进行打分和排序,选出最优解(类似 Best-of-N),进一步提升准确率。
实验结论
实验在多个代码生成基准(如 HumanEval, MBPP, APPS 等)上进行,验证了 ReST-RL 各组件及其整体的有效性。
ReST-GRPO 训练效果
- 性能对比:在对多个基础模型(如 Qwen2.5-Coder-7B, CodeQwen1.5-7B 等)进行两轮迭代训练后,ReST-GRPO 在所有模型上的平均分提升均显著优于基线方法(传统的 GRPO 和 ReST-DPO)。例如,在 Qwen2.5-Coder-7B 上,ReST-GRPO 带来了 6.7% 的平均分提升。
- 训练效率:在相同的训练步数下,ReST-GRPO 带来了比 naive GRPO 和 DAPO 更快、更持续的性能增长,证明了其更高的训练效率。
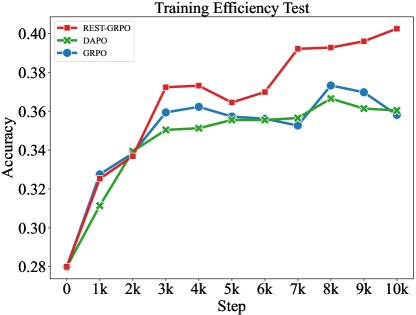 (a) ReST-GRPO、DAPO 和 naive GRPO 在 Llama-3-8B 上的训练效率对比。
(a) ReST-GRPO、DAPO 和 naive GRPO 在 Llama-3-8B 上的训练效率对比。
| 模型 | 训练方法 | HumanEval | HumanEval+ | MBPP | MBPP+ | APPS-500 | BCB | 平均分 |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-Coder-7B-Instruct | 基础模型 | 0.872 | 0.799 | 0.817 | 0.683 | 0.287 | 0.381 | 0.563 |
| ReST-GRPO (第2轮) | 0.890 | 0.835 | 0.849 | 0.712 | 0.415 | 0.462 | 0.630 | |
| CodeQwen1.5-7B-Chat | 基础模型 | 0.805 | 0.732 | 0.810 | 0.677 | 0.148 | 0.348 | 0.502 |
| ReST-GRPO (第2轮) | 0.878 | 0.816 | 0.828 | 0.706 | 0.278 | 0.425 | 0.579 | |
| DS-Coder-6.7b-Instruct | 基础模型 | 0.744 | 0.677 | 0.741 | 0.646 | 0.230 | 0.338 | 0.493 |
| ReST-GRPO (第2轮) | 0.793 | 0.707 | 0.749 | 0.646 | 0.300 | 0.368 | 0.529 | |
| OpenCI-DS-6.7B | 基础模型 | 0.756 | 0.707 | 0.722 | 0.630 | 0.204 | 0.331 | 0.486 |
| ReST-GRPO (第2轮) | 0.774 | 0.713 | 0.725 | 0.630 | 0.325 | 0.377 | 0.531 |
VM-MCTS 解码与验证效果
- 准确性对比:在所有测试模型上,VM-MCTS 的验证准确率均显著高于基于 ORM 和 PRM 的基线方法。
- 预算控制下的表现:在不同的采样预算(即验证成本)下,VM-MCTS 的性能始终优于其他方法,并且随着预算增加,其性能优势愈发明显。
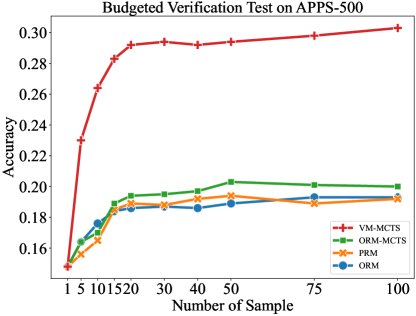 (b) 在 APPS-500 数据集上,不同验证方法在不同采样预算下的性能表现。
(b) 在 APPS-500 数据集上,不同验证方法在不同采样预算下的性能表现。
整体方法验证
将 ReST-GRPO 训练后的策略模型与 VM-MCTS 解码方法相结合(即完整的 ReST-RL 流程),取得了最佳的综合性能。如下表所示,ReST-RL 的平均分在所有基础模型上都超过了单独使用 VM-MCTS 或基础模型。
| 方法 | Qwen2.5-Coder-7B-Instruct | CodeQwen1.5-7B-Chat | DS-Coder-6.7b-Instruct | OpenCI-DS-6.7B | Llama-3.1-8B-Instruct |
|---|---|---|---|---|---|
| 基础模型 | 0.563 | 0.502 | 0.493 | 0.486 | 0.435 |
| ORM | 0.592 | 0.542 | 0.542 | 0.537 | 0.480 |
| PRM | 0.591 | 0.526 | 0.539 | 0.532 | 0.466 |
| ORM-MCTS | 0.588 | 0.545 | 0.547 | 0.535 | 0.481 |
| VM-MCTS | 0.652 | 0.599 | 0.576 | 0.569 | 0.519 |
| ReST-RL | 0.673 | 0.616 | 0.584 | 0.583 | 0.556 |
最终结论
实验结果充分证明,ReST-RL 作为一个统一的 RL 范式,通过其两个阶段的优化(ReST-GRPO 训练和 VM-MCTS 解码),能够有效、高效地提升 LLM 在复杂代码推理任务上的能力,且在成本、效率和泛化性之间取得了良好的平衡。