Rethinking Cross-lingual Gaps from a Statistical Viewpoint
-
ArXiv URL: http://arxiv.org/abs/2510.15551v1
-
作者: Darshan Singh; Trevor Cohn; Purvam Jain; Partha Talukdar; Vihari Piratla
-
发布机构: Google DeepMind; Google Research
TL;DR
本文从统计学视角重新审视了大型语言模型的跨语言知识差距问题,提出这一差距主要源于目标语言(target language)响应的方差增大,而非知识传递失败所导致的偏差(bias),并通过创新的偏差-方差分解框架和一系列实验验证了该假设。
关键定义
本文的核心在于引入了一个统计框架来解释跨语言差距。关键概念沿用并重定义了统计学中的术语:
- 偏差-方差分解 (Bias-Variance Decomposition):本文将模型在源语言和目标语言上的响应误差分解为两个部分。
- 偏差 (Bias):指目标语言的响应系统性地偏离正确答案。这对应于“知识壁垒”或“知识未传递”的场景,即模型在目标语言中无法识别或理解关键实体,导致其猜测一个完全不同的答案。
- 方差 (Variance):指目标语言的响应虽然以正确答案为中心,但分布非常分散、不确定性高。这对应于“信心未传递”的场景,即模型知道答案,但在目标语言中表达时信心不足,导致回答摇摆不定。
- 源/目标响应分布模型 (Source/Target Response Distribution Model):本文将LLM的响应生成过程建模为一个两步随机过程。
-
源语言响应 (Source Response):模型的 logits $\vec{z}$ 从一个均值为 $\vec{\mu}_s$、方差为 $\sigma_s^2I$ 的正态分布中采样,然后通过 Softmax 生成分类分布,最终采样得到响应 $\hat{y}_s$。
\[\vec{z} \sim \mathcal{N}(\vec{\mu}_s, \sigma_s^2I) \\ \hat{y}_s \sim \text{Categorical(softmax}(\vec{z}))\] -
目标语言响应 (Target Response):本文创新地将目标语言的 logits 生成过程建模为一个混合分布,由一个混合系数 $\pi$ 控制。该模型融合了高方差和高偏差两种可能性。
\[\kappa \sim \text{Bernoulli}(\pi) \\ \vec{z} \sim \kappa \underbrace{\mathcal{N}(\vec{\mu}_s/\tau, \eta\sigma_s^2I)}_{\text{high var. component}} + (1-\kappa) \underbrace{\mathcal{N}(\vec{\mu}_b, \sigma_b^2I)}_{\text{high bias component}} \\ \hat{y}_t \sim \text{Categorical(softmax}(\vec{z}))\]其中,$\pi$ 代表了差距由方差主导的概率。当 $\pi \to 1$ 时,差距主要由方差引起(均值与源语言一致但更平坦,方差更大);当 $\pi \to 0$ 时,差距主要由偏差引起(均值 $\vec{\mu}_b$ 与源语言 $\vec{\mu}_s$ 不同)。
-
相关工作
当前,大型语言模型(LLMs)在处理跨语言知识密集型任务时,普遍存在所谓的“跨语言差距”(cross-lingual gap),即当查询语言(目标语言)与知识编码的主要语言(源语言,source language)不同时,模型表现会显著下降。
以往的研究普遍将此问题归因于表征层面的不对齐(representation misalignment)。这种观点认为,由于非英语语料在预训练数据中较为稀疏,同一个实体(例如“纳尔逊·曼德拉”和其印地语“नेल्सन मंडेला”)在不同语言中可能被编码成不同的向量,导致知识无法有效泛化和传递。这种“知识碎片化”或“知识壁垒”的解释,本质上是指模型在目标语言中产生了系统性的偏差(bias)。
本文旨在解决的核心问题是:跨语言差距的根本原因究竟是知识未能传递(偏差),还是知识传递了但信心不足(方差)?作者认为,以往的研究忽视了响应方差在其中扮演的关键角色,而区分这两者对于设计有效的缓解策略至关重要。
本文方法
本文的核心创新在于提出了一个新颖的统计学视角,即使用偏差-方差分解框架来形式化和诊断跨语言差距的根源。其核心假设是:差距主要由方差(variance)而非偏差(bias)引起。
创新点:偏差-方差分解框架
作者将LLM的响应生成过程建模为从输入 $\mathbf{x}$ 到 logits $\vec{z}$ 再到最终响应 $\hat{y}$ 的随机过程。源语言的响应分布由其 logits 的均值 $\vec{\mu}_s$ 和方差 $\sigma_s^2$ 决定。
与传统认知不同,本文假设目标语言的响应分布是一个混合模型,由一个参数 $\pi$ 控制,该参数代表了高方差分量(unbiased noise)所占的比重。
- 高方差分量($\kappa=1$):目标语言的 logits 均值与源语言相关($\vec{\mu}_s/\tau, \tau \ge 1$),但方差更大($\eta\sigma_s^2, \eta \ge 1$)。这代表“信心未传递”:模型知道答案,但不确定。
- 高偏差分量($\kappa=0$):目标语言的 logits 均值 $\vec{\mu}_b$ 与源语言无关。这代表“知识未传递”:模型不知道答案。
本文的主要目标就是通过实验证明 $\pi$ 的值非常接近1,即跨语言差距主要由高方差分量主导。
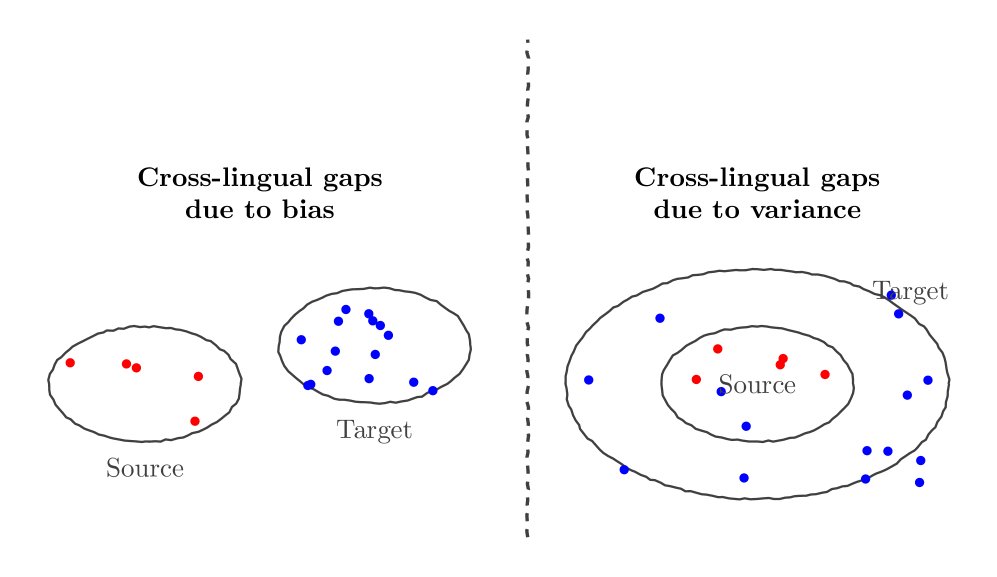 图1:偏差(左)与方差(右)导致跨语言差距的示意图。偏差导致目标语言响应偏离源语言,而方差导致目标语言响应围绕源语言但更分散。
图1:偏差(左)与方差(右)导致跨语言差距的示意图。偏差导致目标语言响应偏离源语言,而方差导致目标语言响应围绕源语言但更分散。
设计的优点:可验证性
该框架的巧妙之处在于,偏差和方差两种误差来源对“方差降低”操作的反应是不同的。
- 如果差距是偏差(bias)主导,简单地降低响应方差(例如通过多次采样取众数)不会显著提高源语言和目标语言响应的一致性,因为它们的中心点本身就不同。
- 如果差距是方差(variance)主导,降低响应方差会使得响应更集中于其共同的中心点(即正确答案),从而显著提高源-目标一致性。
因此,通过设计能够降低方差的推理时干预(inference-time interventions),就可以有效地诊断出差距的真实来源。
框架的进一步推论
基于目标语言噪声是无偏的(unbiased)这一核心假设,本文还导出了两个重要推论:
- 源-目标方差成比例:源语言响应的方差(或不确定性)与目标语言响应的方差是相关的。
- 源语言信心决定差距:当模型在源语言上非常有信心(即响应方差很低)时,其在目标语言上的信心也会相应提高,从而使得跨语言差距减小。
这两个推论也为后续的实验验证提供了方向。
实验结论
本文通过在 ECLeKTic 和 MMLU (with mixup) 两个基准数据集上,对五种先进的开源和闭源LLM(如Gemini系列、GPT系列、Deepseek)进行了广泛实验,有力地验证了其核心假设。
跨语言差距主要源于方差
为了验证降低响应方差能否缩小跨语言差距,本文设计了两种集成(ensembling)方法。
- 响应集成 (Response Ensembling):对同一个问题多次提问并对回答进行集成。实验结果显示,随着集成样本数量的增加,源语言响应与目标语言响应之间的距离(在ECLeKTic上使用嵌入向量的L2距离,在MMLU上使用选项分布的卡方距离)持续且显著地减小。这表明集成操作有效地抑制了方差,从而提高了源-目标一致性。
- 通过该实验估计出的 $\pi$ 值在 ECLeKTic 上约为 0.9,在 MMLU 上约为 0.95,强有力地证明了约90-95%的跨语言差距是由高方差的无偏噪声($\kappa=1$)引起的。

 图2:在ECLeKTic(上)和MMLU(下)数据集上,响应集成(Response Ensembling)可以持续减小源-目标响应的差异。
图2:在ECLeKTic(上)和MMLU(下)数据集上,响应集成(Response Ensembling)可以持续减小源-目标响应的差异。 - 输入集成 (Input Ensembling):通过在单个提示中包含问题的多种语义等价形式来隐式地促使模型进行集成。
- 翻译集成 (TrEn-k):在提示中附上k个其他语言的翻译。
- 先翻译后回答 (TTA-k):指令模型先生成k个翻译,然后再回答问题。
- 实验结果表明,这两种方法都能显著提高模型的跨语言迁移得分(transfer score)。特别是TTA-1方法,在多个模型上取得了稳定且大幅的性能提升,例如在Gemini-2.5-Pro和GPT-5上,迁移得分提升了约12-14个百分点。
| 方法 | G-2.5-Flash | G-2.5-Pro | GPT-5-mini | GPT-5 | Deepseek | Gem-3-27B |
|---|---|---|---|---|---|---|
| Baseline | 30.7 | 37.2 | 19.1 | 35.4 | 18.0 | 9.6 |
| TrEn-1 | 32.8 | 39.2 | 23.4 | 37.6 | 19.9 | 10.3 |
| TrEn-3 | 33.7 | 40.7 | 24.2 | 38.0 | 19.5 | 10.7 |
| TrEn-5 | 36.0 | 40.6 | 22.6 | 39.3 | 18.8 | 11.5 |
| LightLimeGreen TTA-1 | 37.8 | 49.3 | 22.3 | 49.1 | 18.4 | 14.9 |
| TTA-3 | 40.6 | 48.7 | 22.7 | 46.6 | 21.0 | 11.4 |
表1:在ECLeKTic数据集上的源-目标迁移得分。TTA-1(高亮行)表现出持续的良好性能。
源语言方差决定跨语言差距
实验还验证了框架的推论:源语言的信心(即低方差)与跨语言差距的减小直接相关。
- 通过将样本按源语言的回答置信度(即众数回答的频率)分组,实验发现,随着源语言置信度的提高,源语言和目标语言回答一致的概率也稳步提升。
- 这表明,当模型对源语言的答案非常确定时,这种确定性(信心)会更有效地传递到目标语言,从而抑制了方差,缩小了差距。
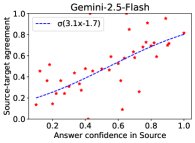
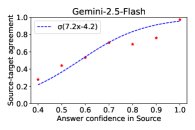 图3:在ECLeKTic(左)和MMLU(右)上,源语言回答的置信度越高,源-目标回答的一致性也越高,表明跨语言差距随源语言信心的增强而减小。
图3:在ECLeKTic(左)和MMLU(右)上,源语言回答的置信度越高,源-目标回答的一致性也越高,表明跨语言差距随源语言信心的增强而减小。
最终结论
本文的实验结果一致表明,LLM的跨语言差距根本上是一个“信心传递”问题(方差问题),而不是一个“知识传递”问题(偏差问题)。当模型在源语言中掌握了某个知识但信心不足时,这种不确定性会在翻译到目标语言时被放大,导致性能下降。这一发现对未来的研究具有重要指导意义:缓解跨语言差距的重点应放在开发能够降低模型在目标语言中响应方差的技术上,而非仅仅关注于预训练数据的语言分布或表征对齐。通过简单的推理时干预,如本文展示的TTA方法,已经可以取得20-25%的显著改进。