Retrieval-Augmented Generation for Large Language Models: A Survey
-
ArXiv URL: http://arxiv.org/abs/2312.10997v5
-
作者: Yunfan Gao; Kangxiang Jia; Yi Dai; Qianyu Guo; Jiawei Sun; Meng Wang; Jinliu Pan; Haofen Wang; Yuxi Bi; Yun Xiong; 等1人
-
发布机构: Fudan University; Shanghai Research Institute for Intelligent Autonomous Systems; Tongji University
TL;DR
本文系统性地综述了大型语言模型(LLM)的检索增强生成(Retrieval-Augmented Generation,RAG)技术,将其发展划分为朴素(Naive)、高级(Advanced)和模块化(Modular)三个范式,并深入剖析了检索、生成与增强这三大核心组件的前沿技术、评估体系及未来挑战。
RAG概述
一个典型的RAG应用场景如图2所示。当用户向ChatGPT这类模型询问近期发生的事件时,由于其知识库截止于预训练数据,无法直接回答。RAG通过从外部知识库(如新闻文章)中检索相关信息,并将这些信息与原始问题一同作为提示(Prompt)输入给LLM,从而赋能LLM生成基于最新信息的、内容详实的回答。
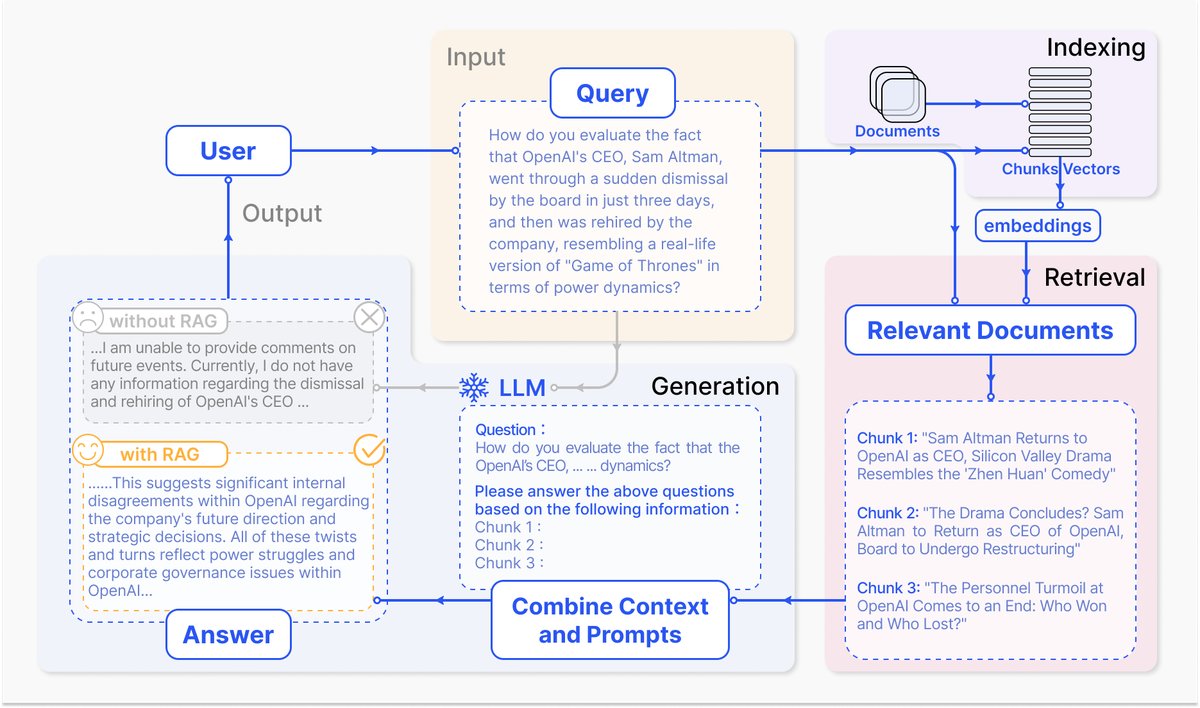 图2:一个RAG在问答任务中的典型应用实例。主要包含3个步骤:1) 索引:将文档分割成块,编码成向量并存入向量数据库。2) 检索:根据语义相似度,检索与问题最相关的Top-K个文本块。3) 生成:将原始问题和检索到的文本块一同输入LLM,生成最终答案。
图2:一个RAG在问答任务中的典型应用实例。主要包含3个步骤:1) 索引:将文档分割成块,编码成向量并存入向量数据库。2) 检索:根据语义相似度,检索与问题最相关的Top-K个文本块。3) 生成:将原始问题和检索到的文本块一同输入LLM,生成最终答案。
RAG的研究范式在不断演进,本文将其归纳为三个阶段:朴素RAG、高级RAG和模块化RAG,如图3所示。
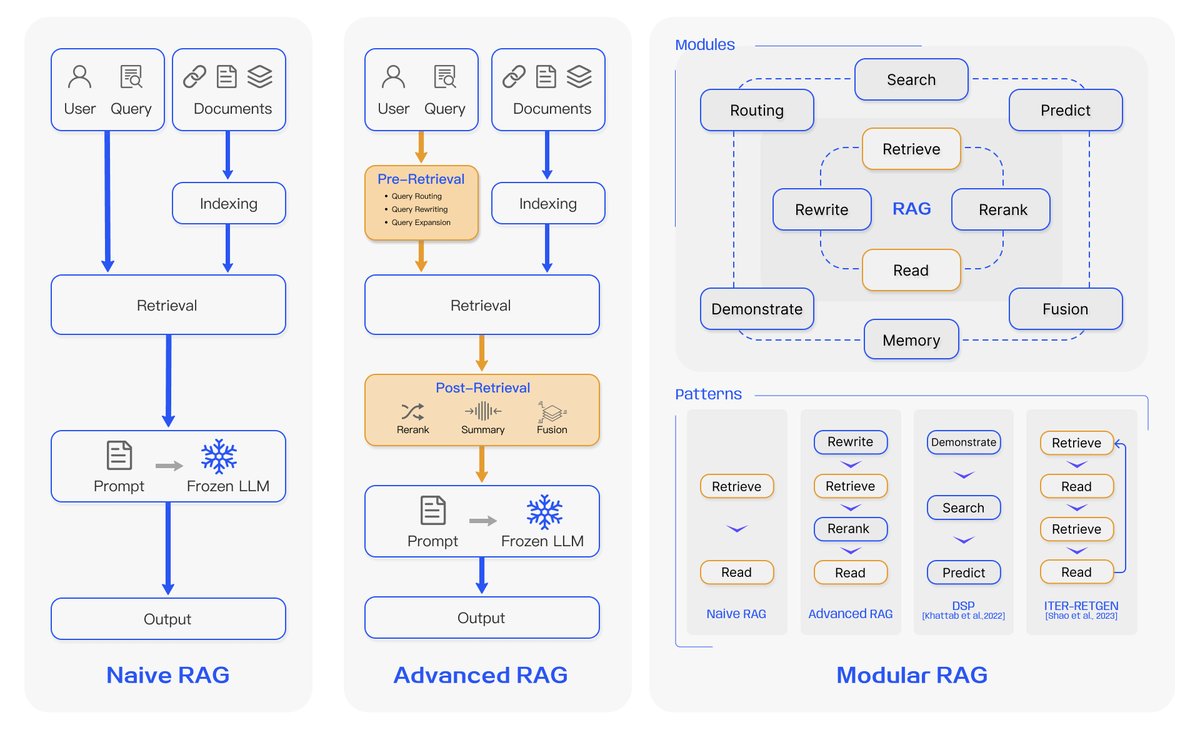 图3:三种RAG范式的对比。(左) 朴素RAG主要包含索引、检索和生成三部分。(中) 高级RAG围绕检索前和检索后环节提出了多种优化策略,其流程与朴素RAG相似,仍为链式结构。(右) 模块化RAG继承并发展了前两种范式,整体展现出更大的灵活性,引入了多个特定功能模块并可替换现有模块,其流程不限于顺序执行,包含迭代和自适应检索等方式。
图3:三种RAG范式的对比。(左) 朴素RAG主要包含索引、检索和生成三部分。(中) 高级RAG围绕检索前和检索后环节提出了多种优化策略,其流程与朴素RAG相似,仍为链式结构。(右) 模块化RAG继承并发展了前两种范式,整体展现出更大的灵活性,引入了多个特定功能模块并可替换现有模块,其流程不限于顺序执行,包含迭代和自适应检索等方式。
朴素RAG
朴素RAG是早期的主流方法,遵循“检索-阅读”(Retrieve-Read)的流程,主要包括三个步骤:
- 索引 (Indexing):将原始文档(如PDF、HTML等)清洗并转换为纯文本,分割成小块(Chunks),然后使用嵌入模型(Embedding Model)将其向量化,并存入向量数据库。
- 检索 (Retrieval):接收到用户查询后,使用相同的嵌入模型将查询向量化,并与数据库中的文本块向量计算相似度,检索出最相关的Top-K个文本块。
- 生成 (Generation):将原始查询和检索到的文本块整合成一个提示,交由LLM生成回答。
然而,朴素RAG存在明显缺陷:
- 检索挑战:检索精度和召回率不高,可能导致检索到不相关或遗漏关键信息的文本块。
- 生成挑战:模型可能产生幻觉(Hallucination),即生成的内容与检索到的上下文不符。输出也可能存在不相关、有毒或带偏见的内容。
- 增强挑战:整合检索信息与不同任务时可能产生脱节或不连贯的输出,并且多源信息的冗余可能导致回答重复。
高级RAG
为了克服朴素RAG的局限性,高级RAG引入了特定优化。它主要通过检索前(Pre-retrieval)和检索后(Post-retrieval)策略来提升检索质量。
- 检索前过程:
- 索引优化:通过滑动窗口、细粒度分块、添加元数据等方式优化索引,提升索引内容的质量。
- 查询优化:通过查询重写(Query Rewriting)、查询转换(Query Transformation)、查询扩展(Query Expansion)等技术,使原始查询更清晰、更适合检索任务。
- 检索后过程:
- 重排序 (Re-ranking):对检索到的信息进行重新排序,将最相关的内容置于提示的边缘(开头或结尾),以利用LLM对长上下文的注意力偏差。
- 上下文压缩 (Context Compressing):为避免信息过载,对检索到的内容进行筛选和压缩,只保留最关键的信息,减少噪声干扰。
模块化RAG
模块化RAG架构提供了更高的适应性和多功能性,它不仅优化现有组件,还引入了新的模块并支持更灵活的流程编排。
新模块
模块化RAG框架引入了多个专用组件以增强其能力:
- 搜索模块 (Search Module):利用LLM生成代码或查询语言,直接在多种数据源(搜索引擎、数据库、知识图谱)上进行搜索。
- 内存模块 (Memory Module):利用LLM的记忆来指导检索,通过迭代自我增强,创建一个无边界的内存池。
- 路由模块 (Routing Module):为查询选择最佳路径,决定是进行摘要、搜索特定数据库还是合并信息流。
- 预测模块 (Predict Module):利用LLM直接生成上下文,以减少检索带来的冗余和噪声。
- 任务适配器 (Task Adapter):为不同下游任务定制RAG,例如为零样本输入自动检索提示,或通过少样本查询生成任务特定的检索器。
新模式
模块化RAG通过模块的替换和重组,打破了朴素和高级RAG固定的“检索-阅读”链式结构,展现出强大的灵活性。
- 流程创新:
- Rewrite-Retrieve-Read: 利用LLM重写查询以提升检索效果。
- Generate-Read: 用LLM生成的内容替代外部检索内容。
- 混合检索: 结合关键词、语义和向量搜索。
- 迭代与自适应检索: 如FLARE和Self-RAG,根据需要动态决定是否以及何时进行检索,而不是固定的单次检索。例如,ITER-RETGEN采用“检索-阅读-检索-阅读”的迭代流程。
- 技术融合:模块化RAG能更方便地与微调(Fine-tuning)或强化学习(Reinforcement Learning)等技术结合,以协同优化检索器和生成器。
RAG vs. 微调 (Fine-tuning)
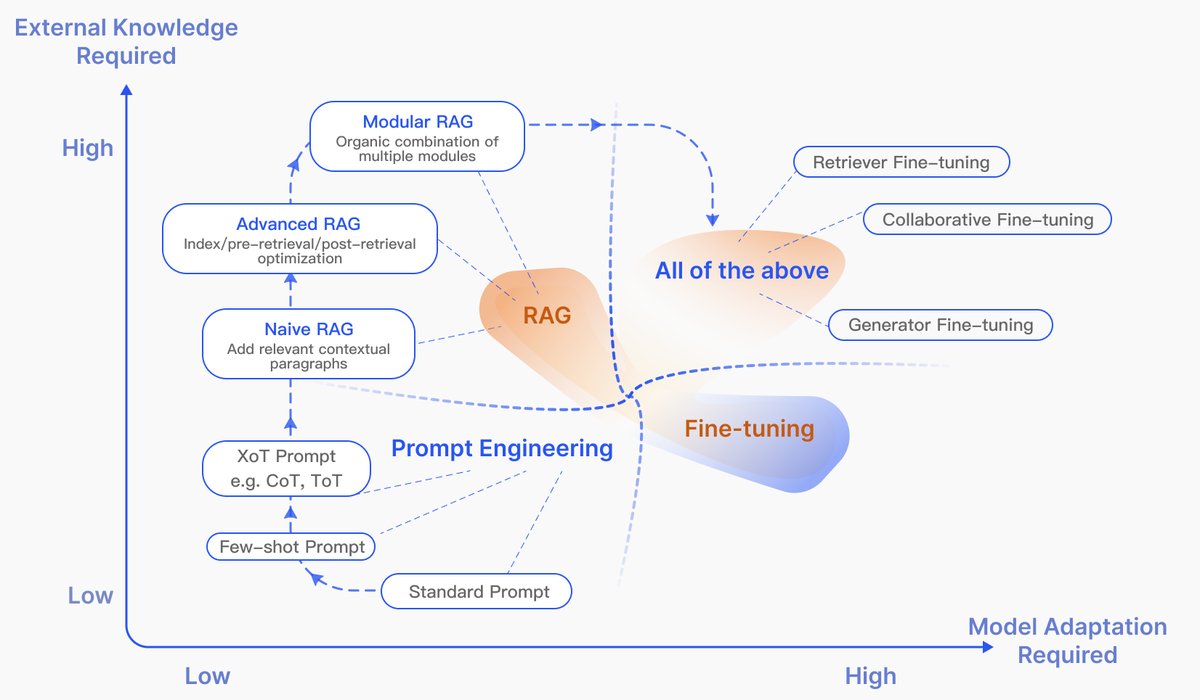 图4:RAG与其他模型优化方法在“所需外部知识”和“所需模型适配”两个维度的比较。提示工程对模型和外部知识的改造要求最低;微调涉及对模型的进一步训练;RAG在早期对模型改造要求低,但随着发展,模块化RAG与微调技术结合得越来越紧密。
图4:RAG与其他模型优化方法在“所需外部知识”和“所需模型适配”两个维度的比较。提示工程对模型和外部知识的改造要求最低;微调涉及对模型的进一步训练;RAG在早期对模型改造要求低,但随着发展,模块化RAG与微调技术结合得越来越紧密。
如图4所示,RAG和微调是增强LLM的两种不同路径:
- RAG:像给模型一本“开卷考试”用的教科书,擅长需要实时、精确信息的任务。它能动态更新知识,可解释性强,但可能引入延迟。
- 微调 (Fine-tuning, FT):像让学生“闭卷考试”前内化知识,适合需要复制特定结构、风格或格式的任务。它能深度定制模型行为,但知识更新需要重新训练,计算成本高。
RAG和微调并非互斥,可以互补使用。研究表明,在知识密集型任务上,RAG的表现通常优于无监督微调。两者的结合往往能达到最佳性能。
RAG方法总结
下表总结了本文调研的多种RAG方法的特性。
| 方法 | 检索来源 | 数据类型 | 检索粒度 | 增强阶段 | 检索过程 | |—|—|—|—|—|—| | CoG [29] | Wikipedia | 文本 | 短语 | 预训练 | 迭代 | | DenseX [30] | FactoidWiki | 文本 | 命题 | 推理 | 单次 | | EAR [31] | 数据集 | 文本 | 句子 | 微调 | 单次 | | UPRISE [20] | 数据集 | 文本 | 句子 | 微调 | 单次 | | RAST [32] | 数据集 | 文本 | 句子 | 微调 | 单次 | | Self-Mem [17] | 数据集 | 文本 | 句子 | 微调 | 迭代 | | FLARE [24] | 搜索引擎, Wikipedia | 文本 | 句子 | 微调 | 自适应 | | … | … | … | … | … | … | | GenRead [13] | LLMs | 文本 | 文档 | 推理 | 迭代 | | UniMS-RAG [74] | 数据集 | 文本 | 多种 | 微调 | 单次 | | … | … | … | … | … | … | | RoG [83] | Freebase | 知识图谱 | 三元组 | 推理 | 迭代 | | G-Retriever [84] | 数据集 | 文本图 | 子图 | 推理 | 单次 | (注:表格内容为原文TABLE I的部分示例)
检索
高效地从数据源中检索相关文档是RAG的关键。
检索源
数据结构
- 非结构化数据:如纯文本,是RAG最常用的检索源,主要来自维基百科、Common Crawl等语料库。
- 半结构化数据:如PDF中的表格。处理时,一种方法是利用LLM的编码能力执行Text-2-SQL查询,另一种是将其转换为文本格式。
- 结构化数据:如知识图谱(Knowledge Graphs, KGs),能提供更精确、经过验证的信息。
- LLM生成内容:一些研究利用LLM自身的内部知识来生成上下文。例如,Self-mem通过迭代创建一个无边界内存池,自我增强生成模型。
检索粒度
检索单元的粒度影响着信息的全面性和噪声水平。粒度从细到粗包括Token、短语、句子、命题(Proposition,文本中的原子事实表达)、文本块(Chunks)、文档等。选择合适的粒度对检索效果至关重要。
索引优化
索引构建的质量决定了检索阶段能否获取正确的上下文。
- 分块策略 (Chunking Strategy):固定大小分块是最常见的方法。但它可能切断语义完整的句子。因此,递归分割、滑动窗口和“Small2Big”(用小块检索,用大块作为上下文)等策略被提出来优化分块。
- 元数据附加 (Metadata Attachments):为文本块附加页码、作者、时间戳等元数据,可以实现基于元数据的过滤或加权检索,例如实现时间感知的RAG。此外,可以人工构建元数据,如段落摘要或假设性问题(Reverse HyDE)。
- 结构化索引 (Structural Index):建立文档的层次化结构,如层级索引或知识图谱索引,有助于快速定位和理解信息,减少幻觉。
查询优化
用户原始查询往往不够精确,直接用于检索效果不佳。
- 查询扩展 (Query Expansion):将单个查询扩展为多个,或分解为多个子查询,以丰富查询内容。例如,Multi-Query利用LLM并行生成多个查询;CoVe (Chain-of-Verification)通过LLM验证扩展后的查询以减少幻觉。
- 查询转换 (Query Transformation):基于转换后的查询进行检索。
- 查询重写 (Query Rewrite):利用LLM或专门的小模型重写原始查询。
- HyDE (Hypothetical Document Embeddings):生成一个假设性的答案,然后基于答案的嵌入向量去匹配相似的真实文档。
- Step-back Prompting: 将原始问题抽象成一个更高层次的概念问题,并结合原始问题一起检索。
- 查询路由 (Query Routing):根据查询的特点,将其路由到不同的RAG流程。例如,元数据路由根据查询中的关键词筛选,语义路由则根据查询的语义意图选择处理路径。
Embedding
Embedding模型将文本转换为向量,其语义表征能力是RAG检索性能的关键。
- 混合检索 (Mix/hybrid Retrieval):结合稀疏检索(如BM25)和密集检索(如BERT系列模型)的优势,前者擅长关键词匹配,后者擅长语义理解,两者互补。
- 微调Embedding模型 (Fine-tuning Embedding Model):在特定领域(如医疗、法律)的数据上微调模型,以增强其对专业术语的理解。一种趋势是利用LLM的反馈作为监督信号来微调检索器,如LSR (LM-supervised Retriever)和REPLUG。
- 适配器 (Adapter):在不完全微调模型的情况下,加入一个轻量级的外部适配器来对齐任务。例如,UPRISE训练一个提示检索器来自动选择最合适的提示;AAR引入一个通用适配器来适应多个下游任务。
生成
检索完成后,需要对检索到的内容和生成模型本身进行调整。
上下文管理
直接将所有检索信息输入LLM并非最佳实践,因为冗余信息会干扰生成,过长的上下文还会导致“中间遗忘”(Lost in the middle)问题。
- 重排序 (Reranking):对检索到的文本块进行重新排序,将最相关的内容放在开头和结尾,以符合LLM的注意力模式。可以使用基于规则或基于模型的方法(如Cohere rerank)进行重排。
- 上下文选择/压缩 (Context Selection/Compression):关键在于减少噪声,而非盲目增加上下文长度。
- (Long)LLMLingua等方法利用小型语言模型(SLM)检测并移除不重要的token,以在保留关键信息的同时压缩提示长度。
- PRCA和RECOMP等方法通过训练一个信息提取器或压缩器来实现,后者采用对比学习来训练编码器。