Retrieval Augmented Generation (RAG) for Fintech: Agentic Design and Evaluation
-
ArXiv URL: http://arxiv.org/abs/2510.25518v1
-
作者: Maraim Masoud; Koustav Ghosal; Thomas Cook
-
发布机构: Mastercard; Maynooth University; National College of Ireland; TU Dublin
TL;DR
本文提出了一种专为金融科技(Fintech)领域设计的智能体化检索增强生成(Agentic Retrieval-Augmented Generation, A-RAG)架构,通过一个由专业智能体组成的模块化、迭代式流水线,有效解决了领域内术语密集、缩写混杂和知识碎片化等挑战,显著提升了检索精度和答案相关性。
关键定义
本文的核心是提出一种新的智能体化RAG架构,并与基线进行对比。关键定义如下:
- 基线RAG (Baseline RAG, B-RAG): 一个标准的、线性的RAG流程,依次执行查询重构、单次向量检索和答案生成。该系统架构简单,但无法处理复杂查询、领域术语和知识碎片化问题。
- 智能体RAG (Agentic RAG, A-RAG): 本文提出的高级RAG架构。它由一个协调器智能体 (Orchestrator Agent) 负责调度多个专业智能体 (specialised agents),通过迭代式的检索、评估和精炼循环来处理用户查询。其设计旨在通过模块化和任务分解来应对金融科技领域的复杂性。
- 语义准确度 (Semantic Accuracy): 本文使用的一种评估指标,通过一个作为“法官”的语言模型(LLM-as-a-judge)来评估生成答案与标准答案在语义上的等价性,而非仅仅是词汇上的重叠。评分范围为1-10分。
相关工作
当前,检索增强生成(RAG)系统在通用领域取得了显著成功,但在金融科技(Fintech)等高度专业化和严格监管的领域部署时面临巨大挑战。
研究现状的瓶颈主要包括:
- 领域特殊性:金融科技领域充满了密集的专业术语、不一致的缩写和高度碎片化的内部知识库(如产品文档、合规文件、架构图等),标准RAG系统难以准确理解用户意图和检索正确上下文。
- 组织与合规限制:监管要求数据不能离开企业边界,这使得依赖云API或第三方评估平台的SaaS方案不可行。同时,企业内部部门墙导致知识孤立,加剧了信息检索的难度。
- 评估困难:由于数据保密性,无法使用众包平台进行人工评估,而寻找领域专家进行大规模标注成本高昂且耗时。
因此,本文旨在解决的核心问题是:如何设计一个能够在企业内部署、适应金融科技领域复杂性(术语、缩写、信息碎片化)的RAG系统,并建立一套安全、可复现的评估方法。
本文方法
本文首先实现了一个标准的基线RAG系统(B-RAG)作为对比,然后设计并实现了一个更先进的智能体RAG系统(A-RAG)。
基线方法 (B-RAG)
B-RAG代表了一个标准的检索流程,其架构简单、线性,如下图所示。
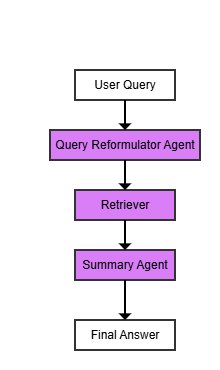
该流程包括三个主要智能体:
- 查询重构器 (Query Reformulator): 将用户问题转化为关键词丰富的简洁查询。
- 向量检索器 (Vector Searcher): 在知识库中执行一次单遍的向量相似度搜索,找出相关的文档片段。
- 摘要生成器 (Summarizer): 将检索到的文档片段整合成连贯的答案,并被明确指示不要生成原文中没有的信息。
B-RAG的主要局限性在于其单遍检索机制,缺乏迭代优化,无法分解复杂问题,不能处理领域缩写,也未对检索结果进行重排序,导致在处理复杂和模糊查询时精度较低。
智能体RAG方法 (A-RAG)
为解决B-RAG的局限性,本文提出了A-RAG,一个以协调器智能体 (Orchestrator Agent) 为核心的模块化、迭代式系统。其设计灵感来源于研究人员的工作流:先尝试直接回答,然后评估结果质量,必要时再启动更深入、更具针对性的探索。
A-RAG与B-RAG的工作流对比如下,A-RAG增加了缩写解析、子查询生成、重排序和答案质量评估等多个环节,并引入了反馈循环。
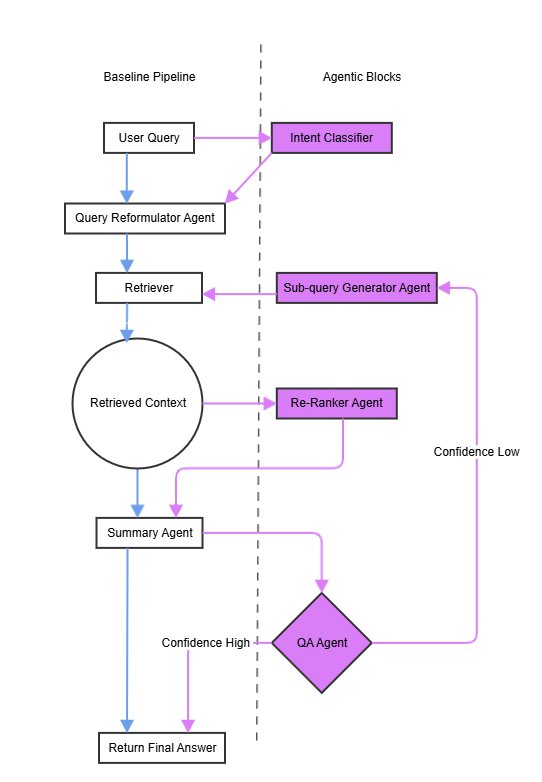
创新点
A-RAG的本质创新在于从线性、单次的检索转变为动态、迭代的“检索-推理”循环。这个循环由一个内部的质量评估机制驱动,实现了架构的高度模块化和适应性。
其核心优势体现在以下几个方面:
- 模块化智能体设计:系统由8个轻量级、功能专一的智能体构成,由一个协调器统一调度。这种设计使得系统可以灵活地编码特定领域的规则和知识(如内部术语、访问控制等)。
- 核心智能体组件:包括判断检索必要性的 \(Router Agent\)、扩展缩写和同义词的 \(Query Reformulator\)、处理并行检索的 \(Vector Searcher\)、在初步检索效果不佳时生成细分查询的 \(Sub-Query Generator\)、使用交叉编码器(cross-encoder)优化结果排序的 \(Re-ranker\)、评估答案质量并决定是否需要迭代的 \(QA Agent\),以及动态维护术语表的 \(Acronym Agent\)。
-
迭代式精炼循环:A-RAG引入了一个由 \(QA Agent\) 驱动的反馈循环。当生成的初步答案置信度低时,系统不会直接返回结果,而是触发子查询生成和重排序等精炼步骤,进行更深入的探索,直到答案质量满足预设阈值。
- 主动式术语处理:\(Acronym Agent\) 主动识别和解析查询及文档中的领域缩写,显著降低了因术语模糊性导致的检索错误,提升了答案的准确性。
工作流程概述
以一个金融科技查询为例,A-RAG的工作流程如下:
- 查询预处理:首先对用户查询进行重构和缩写扩展(例如,将“CMA”根据上下文解析为“Consumer Management Application”)。
- 初步检索与生成:执行第一遍向量检索,并生成一个初步答案。
- 质量评估:\(QA Agent\) 对答案进行打分(0-10分)。
- 迭代精炼(如果需要):如果分数低于阈值,系统将触发精炼流程。\(Sub-Query Generator\) 会生成更具针对性的子查询(如“CVaR formula”),再次检索,并通过 \(Re-ranker\) 优化结果排序,然后重新生成答案。
- 最终输出:如果经过迭代后能生成高置信度的答案,则返回该答案;否则,系统会向用户明确表示无法找到确切答案,保证了透明度。
实验结论
本文通过在一个真实的金融科技企业内部知识库上进行实验,对B-RAG和A-RAG的性能进行了定量和定性评估。
知识库与评估集
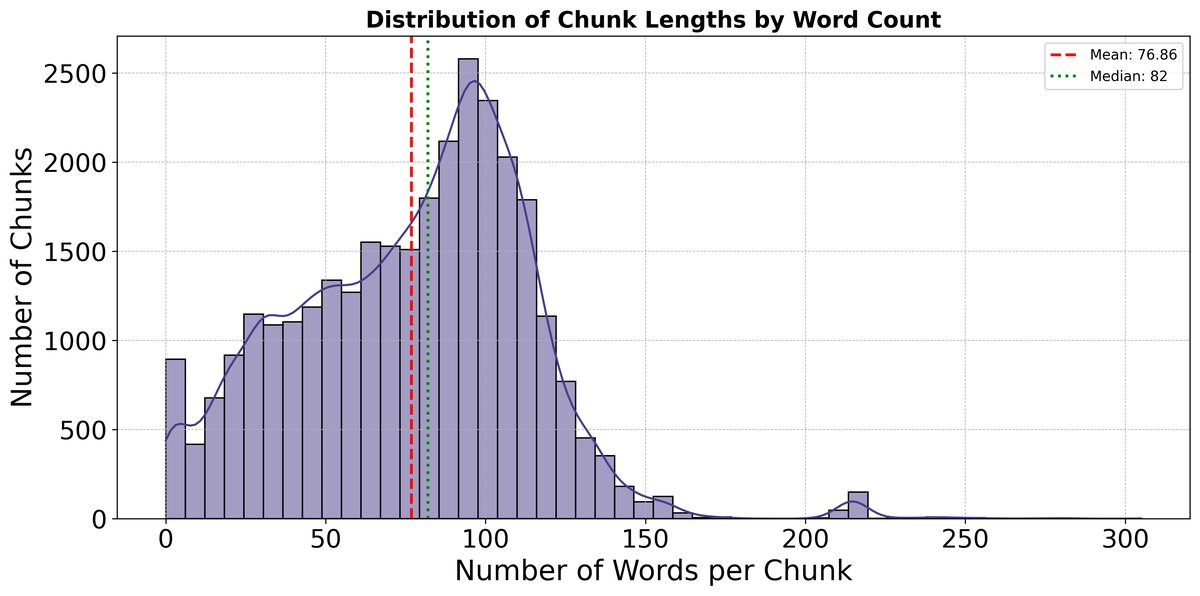
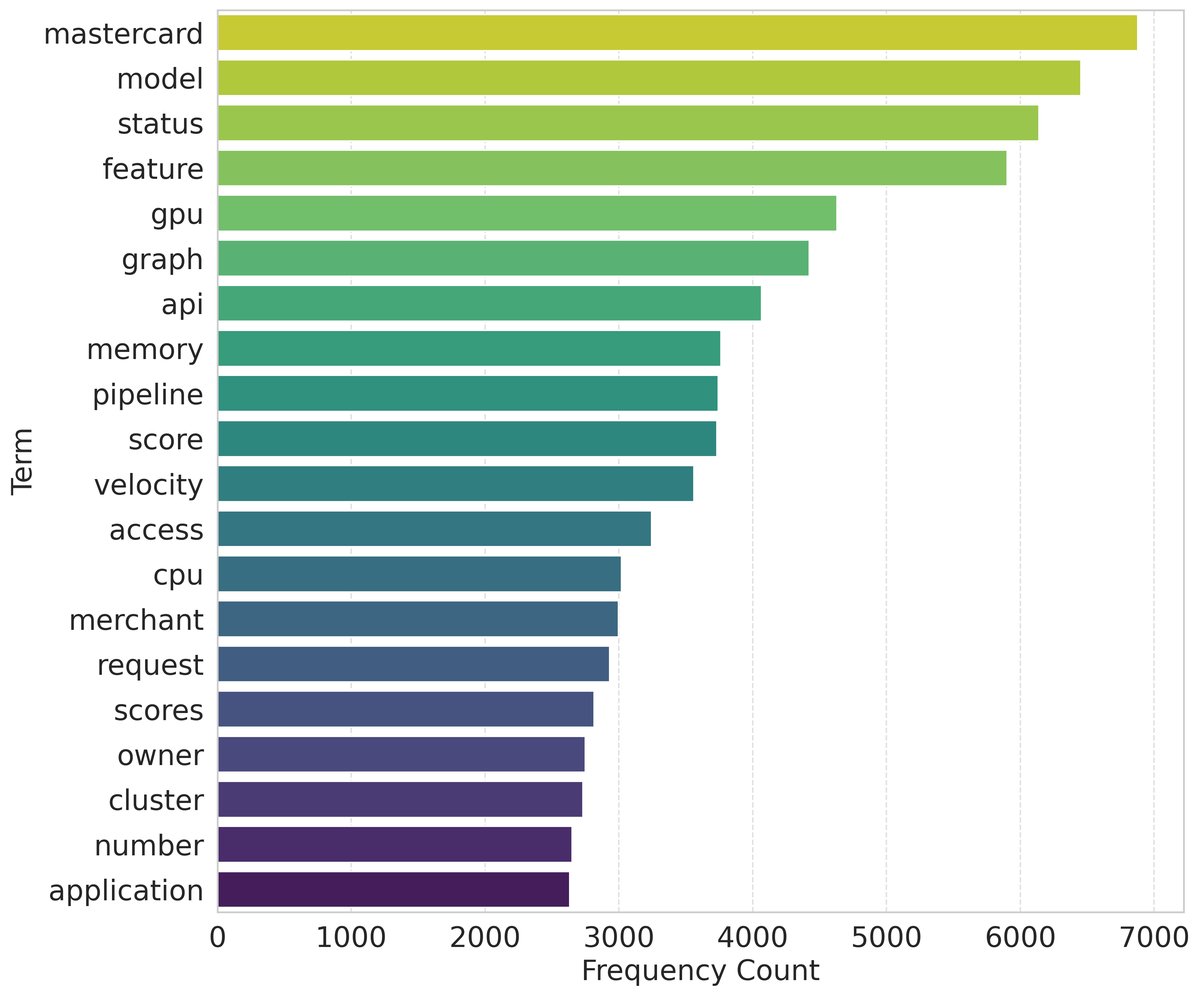
- 知识库:由超过1624份内部文档构成,预处理后切分为超过30,000个文本块。文本块长度主要集中在50-120词之间,内容富含“feature”、“API”、“model”等领域术语。
- 评估集:采用“LLM-as-a-judge”范式,从知识库中自动生成了85个高质量的“问题-答案”对作为主要评估集。此外,还手动构建了一个包含17个问题、33个标准答案链接的基准测试集,用于更细致的分析。

核心实验结果
实验从检索准确率、延迟和答案语义准确度三个维度比较了两个系统。
检索准确率与延迟
A-RAG在检索准确率上优于B-RAG,但延迟也显著增加,这体现了性能与效率的权衡。
| 指标 | B-RAG | A-RAG |
|---|---|---|
| 评估问题总数 | 85 | 85 |
| 检索准确率 (Hit @5, %) | 54.12 | 62.35 |
| 平均每次查询延迟 (秒) | 0.79 | 5.02 |
经过手动分析,若考虑语义等价但来源不同的文档,A-RAG的调整后准确率可达69.41%,而B-RAG为58.82%,进一步证明了A-RAG在整合碎片化信息上的优势。
答案语义准确度
使用LLM-as-a-judge对答案质量进行评分(1-10分),A-RAG的平均得分为7.04,高于B-RAG的6.35。
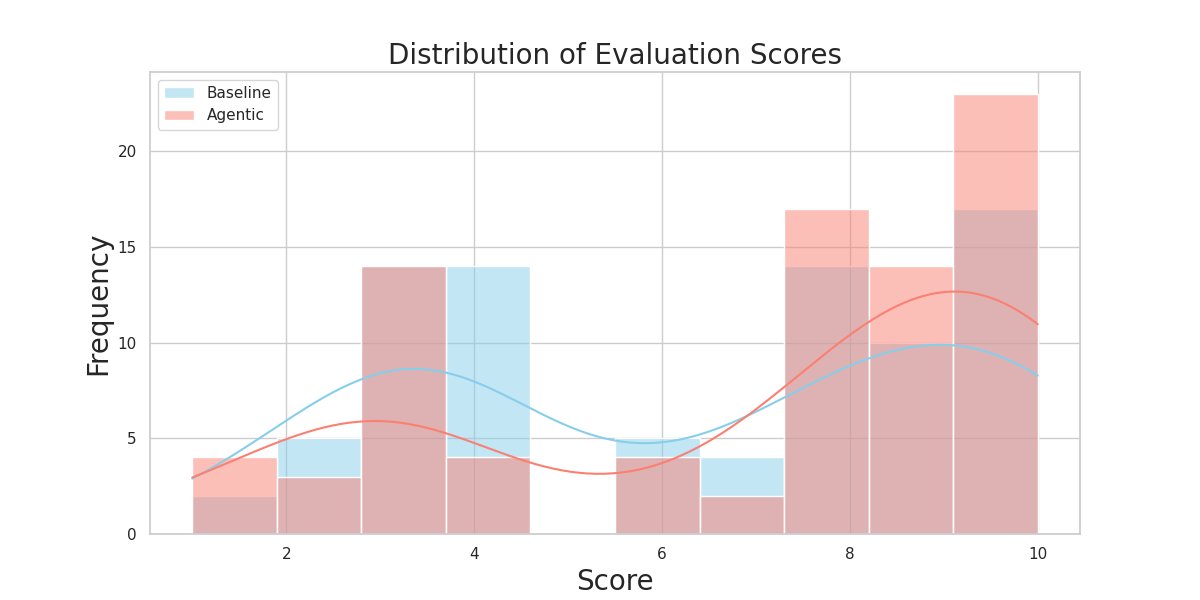
如上图所示,A-RAG显著减少了低质量答案(得分<5)的比例(从18%降至8%),并增加了高质量答案(得分≥9)的比例(从12%增至22%)。在64%的情况下,A-RAG的表现优于B-RAG。
人工策划基准测试结果
在包含多重可能答案的手动构建测试集上,A-RAG在整体上表现更优,尤其在程序性问题上实现了100%的覆盖率,远超B-RAG。
| 系统 | 类别 | 问题数 | 覆盖率 (%) | 语义准确度 |
|---|---|---|---|---|
| B-RAG | 总体 | 17 | 66.67 | 7.88 |
| 定义性 | 9 | 73.68 | 7.78 | |
| 程序性 | 4 | 57.14 | 7.75 | |
| 缩写 | 4 | 57.14 | 8.25 | |
| A-RAG | 总体 | 17 | 69.70 | 8.06 |
| 定义性 | 9 | 68.42 | 7.89 | |
| 程序性 | 4 | 100.0 | 8.25 | |
| 缩写 | 4 | 42.85 | 8.25 |
最终结论
实验结果证实,本文提出的A-RAG架构通过智能体分解和迭代式精炼策略,在处理金融科技领域碎片化、术语密集的知识时,其检索准确率和答案质量均显著优于标准的RAG基线。尽管这带来了更高的延迟,但其在提升系统鲁棒性方面的优势表明,结构化的多智能体方法是增强复杂领域专用RAG系统性能的一个极具前景的方向。