RollPacker: Mitigating Long-Tail Rollouts for Fast, Synchronous RL Post-Training
-
ArXiv URL: http://arxiv.org/abs/2509.21009v1
-
作者: Yuheng Zhao; Wenbo Su; Weixun Wang; Siran Yang; Ju Huang; Tianyuan Wu; Wei Wang; Bo Zheng; Jiamang Wang; Shaopan Xiong; 等12人
-
发布机构: Alibaba; Alibaba Group; Hong Kong University of Science and Technology
TL;DR
本文提出了一种名为 RollPacker 的同步强化学习(RL)训练系统,其核心是一种创新的 rollout 调度策略——尾部批处理(tail batching),该策略通过将导致长响应的 prompt 整合到少数专用的 rollout 步骤中,显著减少了因响应长度不均衡导致的 GPU 空闲时间,从而在不牺牲模型准确率的前提下,大幅加速了大型语言模型的同步 RL 训练。
关键定义
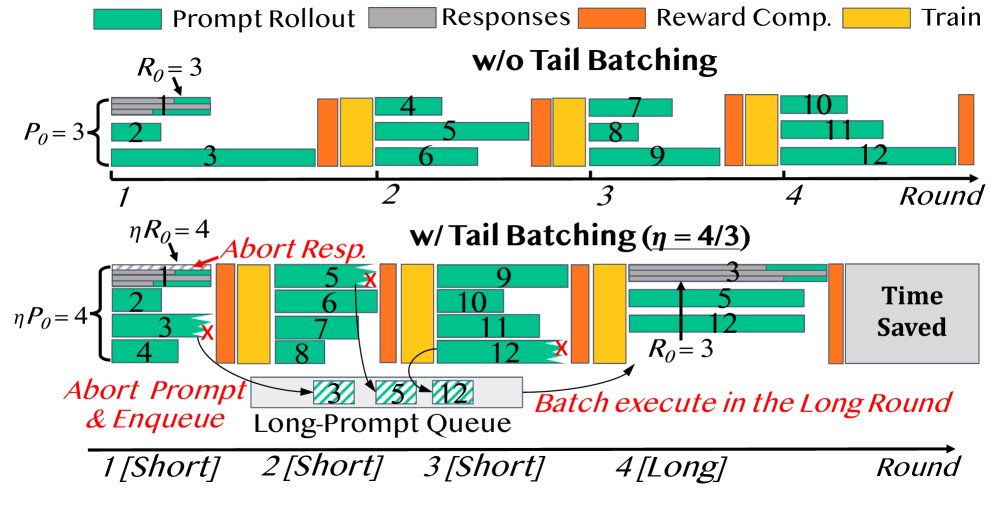
- 尾部批处理 (Tail Batching):一种新颖的 prompt 调度策略。它将训练样本重新排序,把可能产生长响应的“尾部 prompt”整合到少数专用的“长轮次”中,而让大多数“短轮次”只包含响应长度均衡的短响应。该策略通过投机执行(speculative execution)来识别和推迟长响应,从而在保持整体样本分布不变的情况下,减少 GPU 等待时间。
- 长轮次 (Long Rounds) & 短轮次 (Short Rounds):由尾部批处理产生的两种 rollout 步骤。短轮次构成了大部分训练步骤,其中系统通过投机执行快速生成一批长度均衡的短响应,以提高效率。长轮次则专门用于处理在短轮次中被推迟的、会产生长响应的 prompt,确保所有样本都能得到训练。
- RollPacker:本文提出的一个完整的、为实现尾部批处理的优势而设计的系统。它集成了三大优化:用于 rollout 阶段的弹性并行规划器、用于奖励计算阶段的动态资源调度器,以及用于训练阶段的流式训练器,实现了对整个 RL 训练流程的端到端优化。
- 流式训练器 (Stream Trainer):RollPacker 的一个关键组件,用于减少长轮次中的 GPU 空闲。它会在 rollout 过程中,机会性地将已完成响应的 GPU 重新分配给训练任务,提前开始梯度计算。通过精心设计的梯度缩放和延迟更新机制,它在不破坏同步在策略(on-policy)训练正确性的前提下,实现了 rollout 和训练的细粒度重叠。
相关工作
当前,使用强化学习(RL)对大型语言模型(LLM)进行后训练(post-training)是提升其复杂推理能力的关键技术。为了保证最佳的模型性能,业界通常采用同步在策略(synchronous on-policy)的 RL 训练范式,即确保用于生成响应的 actor 模型始终是最新版本。
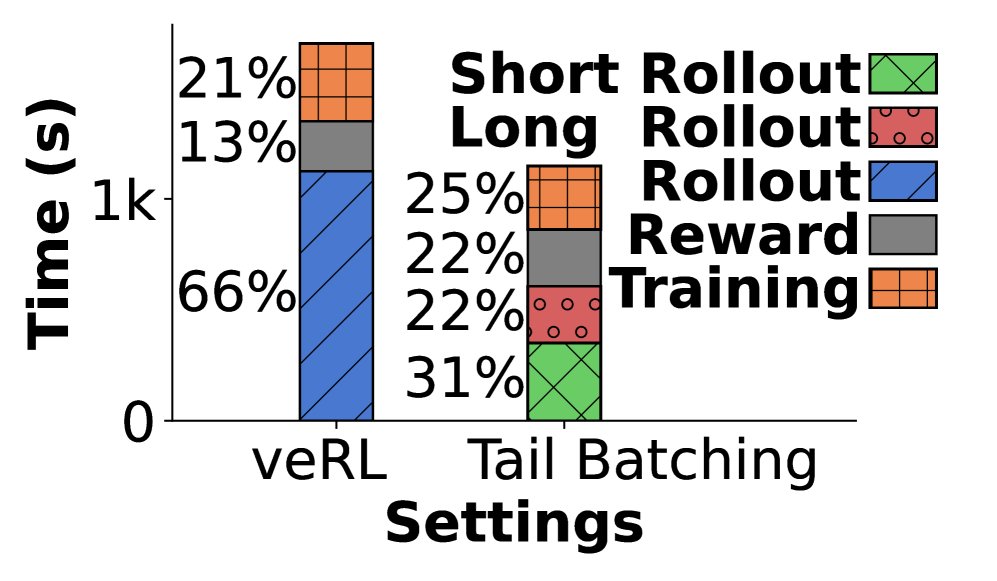
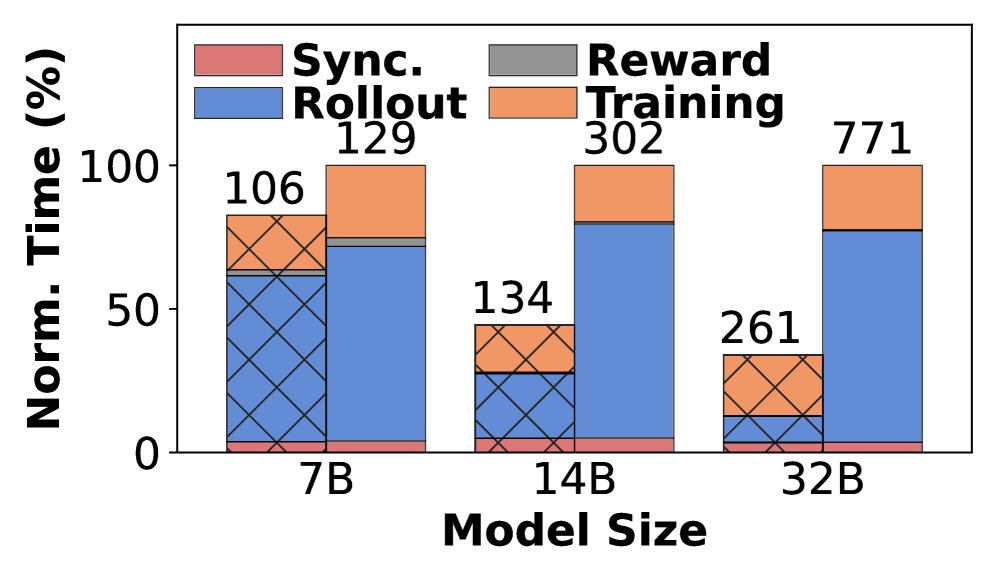
然而,这种同步机制导致了严重的性能瓶颈。由于输入 prompt 生成的响应长度呈现出明显的“长尾分布”,即少数响应极长,导致在 rollout 阶段,处理短响应的 GPU 必须长时间空闲等待,造成了巨大的资源浪费(即“气泡”)。据统计,rollout 阶段的耗时占整个训练时间的约 70%。
现有的解决方案主要有两类:
- 在同步约束下重叠阶段:如 RLHFuse 等系统尝试将 rollout 阶段与奖励计算、参考模型推理等阶段重叠。但这些辅助阶段的计算量(通常<15%)远不足以填补长 rollout 造成的巨大空闲时间。
- 放宽同步约束:如 StreamRL、AReaL 等系统采用异步或“一次性”流水线,允许使用过时(stale)的模型权重生成的响应进行训练。虽然这提高了 GPU 利用率,但破坏了在策略训练的原则,常常导致模型准确率下降和训练不稳定。
因此,本文旨在解决的核心问题是:如何在不牺牲同步在策略 RL 训练准确性和稳定性的前提下,有效缓解因响应长度不均衡导致的 GPU 严重利用不足问题,从而加速 LLM 的后训练过程。
本文方法
本文的核心方法是 尾部批处理 (Tail Batching),并在此基础上构建了一个名为 RollPacker 的高效同步 RL 训练系统,该系统通过对 rollout、奖励(reward)和训练(training)三个阶段的协同优化,最大化了尾部批处理带来的收益。
尾部批处理 (Tail Batching)
尾部批处理是一种创新的 prompt 调度策略,其本质是通过重新排序训练样本来解决响应长度不均衡的问题,同时保持在策略训练的语义。
该策略的实现依赖于两个关键技术:
-
投机执行 (Speculative Execution):在大部分的 短轮次 (short rounds) 中,系统会超量启动 prompt 和响应的生成任务。例如,若一个批次需要 $P_0$ 个 prompt,每个 prompt 需 $R_0$ 个响应,系统会启动多于 $P_0$ 个 prompt,并为每个 prompt 生成多于 $R_0$ 个响应。然后,系统只保留最先完成的 $P_0$ 个 prompt 及其最先完成的 $R_0$ 个响应。这种“竞速完成”的机制自然地筛选出了响应较短、长度均衡的批次,从而大大减少了 GPU 的空闲等待时间。
-
延迟调度与长轮次 (Deferred Scheduling & Long Rounds):在投机执行中被“淘汰”的、响应时间过长的 prompt 并不会被丢弃,而是被添加到一个“长 prompt 队列”中。当这个队列累积到足够数量(例如 $P_0$ 个)时,系统会启动一个专用的 长轮次 (long round)。在长轮次中,投机执行被禁用,所有 prompt 都会被完整地执行,以生成它们的长响应。
由于产生长响应的 prompt 是少数,因此长轮次出现的频率远低于短轮次。这种设计确保了所有训练样本最终都会被使用,保持了原始数据分布的无偏性,因此不会损害模型准确率。尾部批处理仅仅改变了样本的训练顺序,这在近期的研究中已被证明对模型性能无负面影响。

RollPacker 系统设计
RollPacker 系统围绕尾部批处理策略,设计了三个协同工作的组件,分别应对 RL 训练三个阶段的瓶颈。
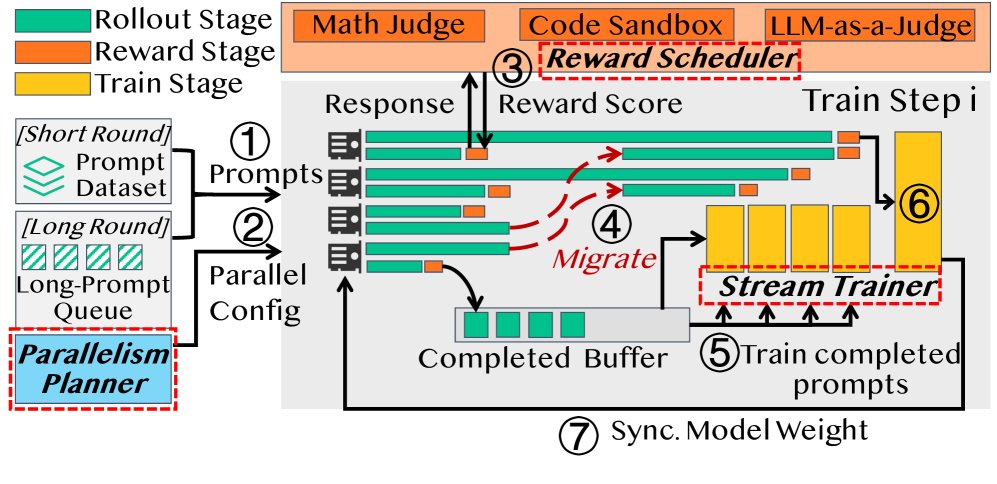
系统概览
RollPacker 的工作流程分为离线分析和在线执行两个阶段。离线阶段,系统会分析不同并行配置下的模型性能和内存占用。在线执行阶段,系统协调三大核心组件:
- 并行规划器 (Parallelism Planner):在 rollout 阶段,根据当前是短轮次还是长轮次,动态选择最优的张量并行(Tensor Parallelism, TP)配置,以应对不同的内存压力。
- 奖励调度器 (Reward Scheduler):将奖励计算与 rollout 过程并行化,并为不同类型的奖励任务(如代码执行、LLM 裁判)动态调整计算资源,避免奖励计算成为新瓶颈。
- 流式训练器 (Stream Trainer):在长轮次中,将 rollout 和训练过程进行细粒度重叠。它会把空闲的 GPU 从 rollout 任务中解放出来,提前投入到梯度计算中,进一步减少等待时间。
并行规划器 (Parallelism Planner)
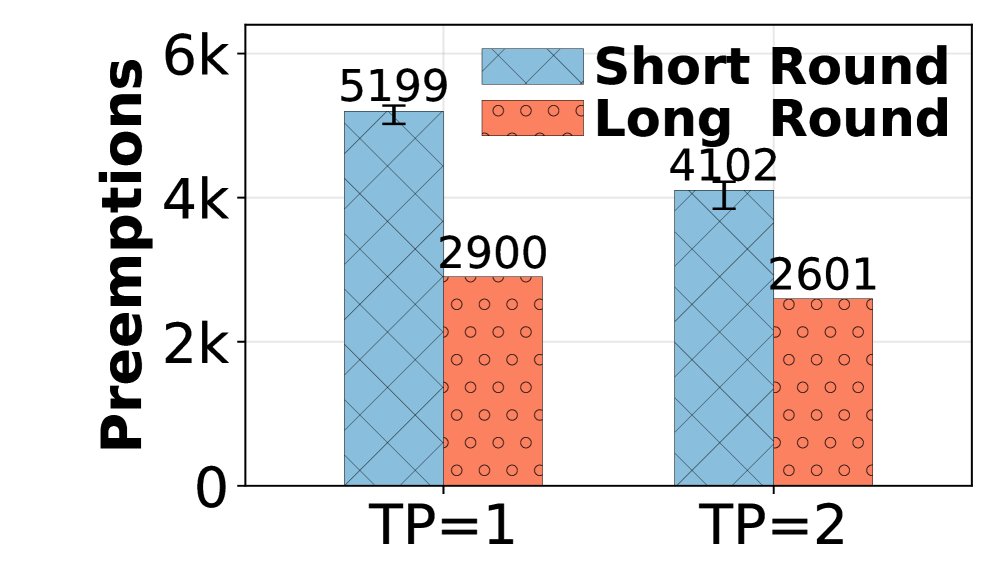
短轮次由于投机执行会并发处理更多请求,导致 GPU 内存压力远高于长轮次。固定的 TP 配置无法同时适应这两种模式。
- 问题:TP 太小,在短轮次内容易因 KV 缓存不足导致大量请求被抢占(preemption),产生开销;TP太大,在长轮次中通信开销又会拖慢速度。
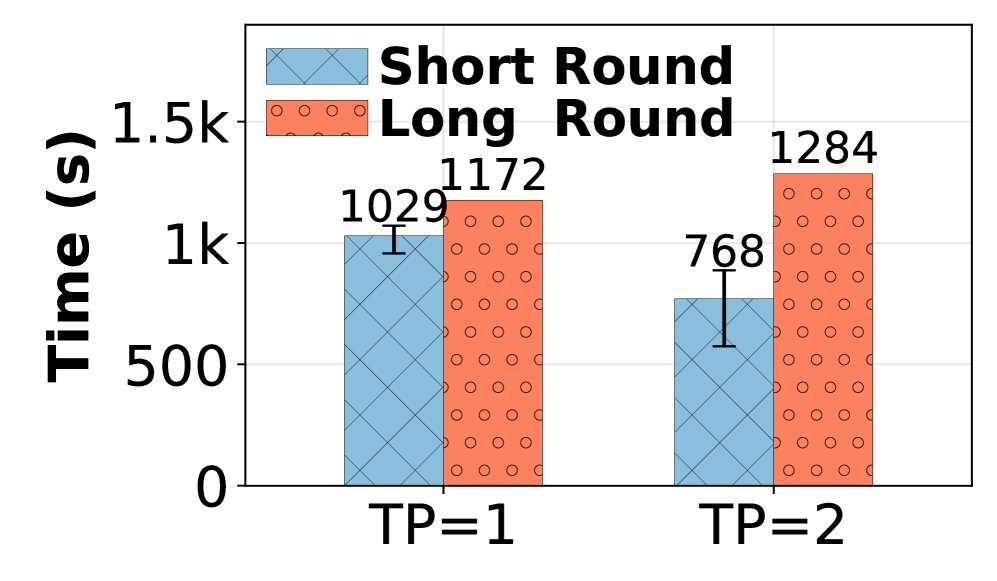
- 方案:RollPacker 的并行规划器在每个训练步骤动态调整 TP 大小。它通过监控运行时的抢占次数来启发式地决策:当抢占次数激增时,增加 TP 大小(例如加倍);当一段时间内没有抢占时,减小 TP 大小(例如减半)。这种自适应策略使得 rollout 阶段始终在近乎最优的并行配置下运行。
奖励调度器 (Reward Scheduler)
当 rollout 耗时被显著缩短后,奖励计算可能成为新的瓶颈。奖励调度器通过异步化和智能资源管理来解决此问题。
- 异步计算:完成的响应被立刻分发到奖励工作进程进行评估,与仍在进行的 rollout 过程重叠,隐藏了部分延迟。
- 针对代码执行的自适应超时:对于代码评估任务,调度器不再使用固定的长超时,而是根据历史上正确代码的执行时间动态调整超时阈值 $T_{\text{timeout}}$。其计算公式为:
其中 $T_{\text{anchor}}$ 是正确响应的最大执行时间记录。这能快速淘汰掉那些几乎不可能成功的慢速执行,节省了大量时间。
- 针对 LLM 裁判的 GPU 共享:对于使用 LLM 作为裁判的任务,调度器不为其预留专用 GPU,而是让裁判 LLM 与 actor LLM 在同一批 GPU 上通过多进程服务(Multi-Process Service, MPS)并发执行。为了解决内存不足问题,它采用一种分层流水线方案,将裁判 LLM 的部分层卸载到 CPU 内存,在计算时通过 PCIe 流式传输回 GPU,从而在不影响 rollout 性能的情况下高效利用 GPU 资源。

流式训练器 (Stream Trainer)
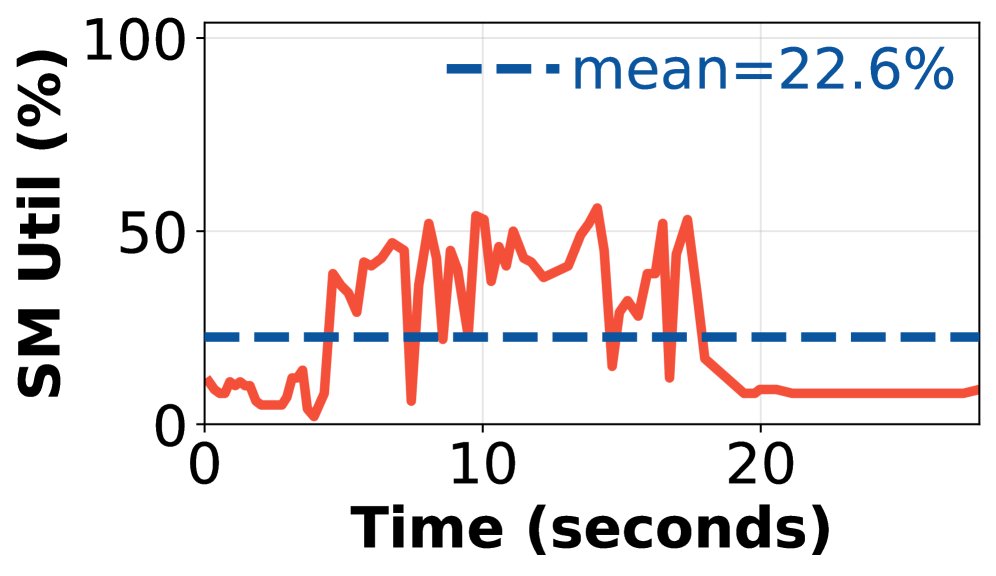
即使经过优化,长轮次依然存在 GPU 空闲。流式训练器通过一种更细粒度的阶段重叠来解决这个问题。
- 动态 GPU 缩放与重分配:在长轮次进行中,一旦有足够比例(例如 20%-50%)的请求完成,流式训练器会评估是否可以将一部分 GPU 从 rollout 任务中释放出来。决策依据包括:1) 缩减 GPU 是否会导致剩余 GPU 的内存溢出;2) 缩减操作是否会破坏 rollout 任务所需的通信组(如 TP 组)。
- 流式梯度计算:一旦 GPU 被成功重分配给训练任务,它便立即开始接收已完成的响应流,并进行梯度计算。这个过程与仍在进行的 rollout 完全并行。
- 保持在策略语义:为了确保与标准在策略训练的数学等价性,流式训练器遵循两个原则:1) 在流式计算期间,只计算并缓存梯度,不进行任何参数更新或优化器状态同步。2) 在整个 rollout 阶段结束后,系统会进行一次最终的、全局同步的梯度计算和更新。此时,会根据每个数据并行副本已处理的样本数量对局部梯度进行重新归一化,以确保最终的梯度更新结果完全正确。
实验结论
本文在多达 128 个 H800 GPU 的集群上,使用 Qwen2.5 系列模型(7B-32B)和真实世界数据集对 RollPacker 进行了评估。
端到端评估
- 准确率与收敛速度:实验证明,与基线系统 veRL相比,RollPacker 在所有模型尺寸上都取得了几乎完全相同的验证准确率曲线,证实了其尾部批处理策略不会损害模型性能。
- 训练速度:RollPacker 展现了显著的端到端训练加速效果。与 veRL 相比,针对 7B、14B、32B 模型的端到端训练时间分别缩短了 2.03倍、2.22倍和2.56倍。与同样采用重叠优化的 RLHFuse 相比,也取得了最高 2.24倍的加速。加速主要来源于短轮次的大幅耗时缩减。
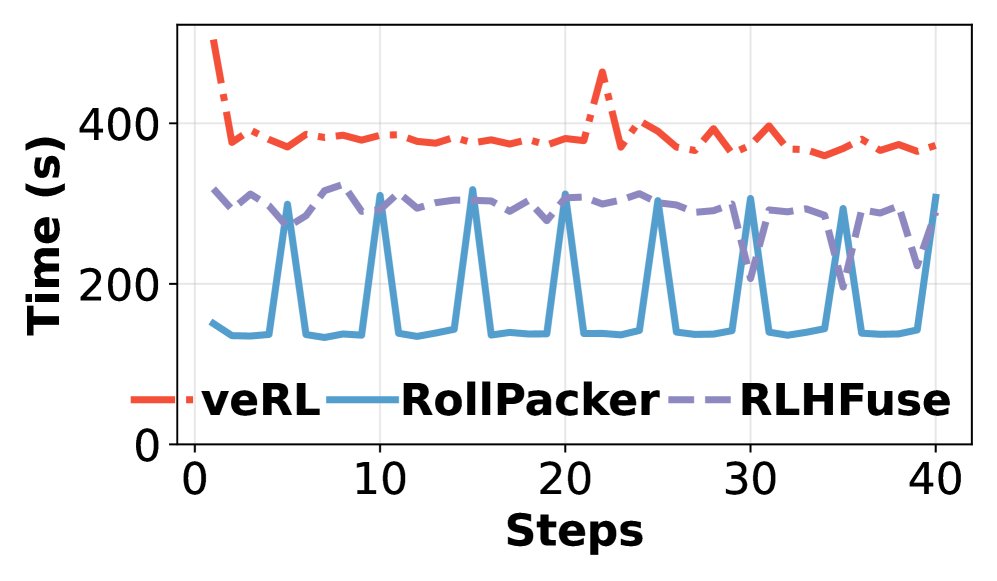
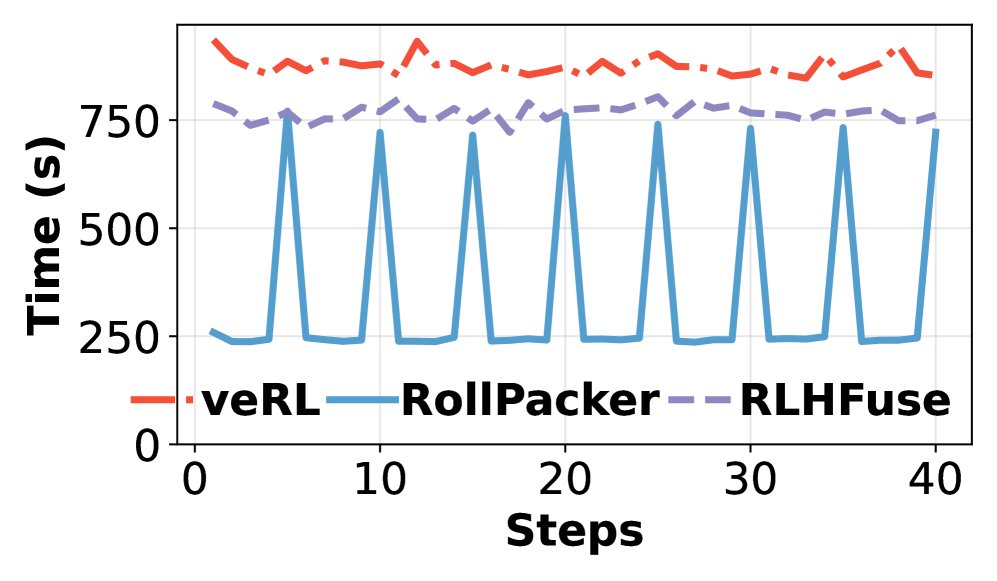
性能分解
对各项优化技术的累积加速效果进行了分解:
| 模型/序列长度 | 仅尾部批处理 | +奖励调度器 | +并行规划器 | +流式训练器 (完整RollPacker) |
|---|---|---|---|---|
| Qwen2.5-7B/8k | 1.30x | 2.01x | 2.02x | 2.03x |
| Qwen2.5-14B/16k | 1.76x | 1.95x | 2.02x | 2.22x |
| Qwen2.5-32B/32k | 2.21x | 2.48x | 2.52x | 2.56x |
- 尾部批处理是加速的核心,响应序列越长,其优势越明显,最高带来 2.21 倍加速。
- 奖励调度器在短序列上效益显著(提升71%),在长序列上也持续贡献(提升27%)。
- 并行规划器在高内存压力场景(大模型、长序列)下提供额外增益。
- 流式训练器通过重叠 rollout 和训练,在 14B 模型上带来了 20% 的显著性能提升。


微基准测试分析
- 尾部批处理:通过同时对 prompt 和响应进行投机执行($\eta=1.25$),相比仅对其中一项进行投机,平均 rollout 速度提高了 1.5 倍至 1.6 倍。
- 并行规划器:在响应长度动态变化的场景下,自适应TP选择相比固定TP配置,平均 rollout 加速达 1.9倍。在短轮次中,它能将抢占次数平均减少 13.8%,rollout 时间加速 1.11x-1.28x。
- 奖励调度器:针对 LLM 裁判任务,GPU 共享(colocation)结合 MPS 技术可带来高达 1.25 倍的加速;分层流水线执行可为长序列奖励计算带来 1.4 倍加速。针对代码任务,自适应超时相比固定超时平均加速 1.6倍。
- 流式训练器:自适应的 GPU 缩放策略比任何固定的触发策略都更优,相比不缩放基线带来 1.08 倍加速。异步流式获取数据比单次批量获取最多可减少 14% 的端到端步骤时间。
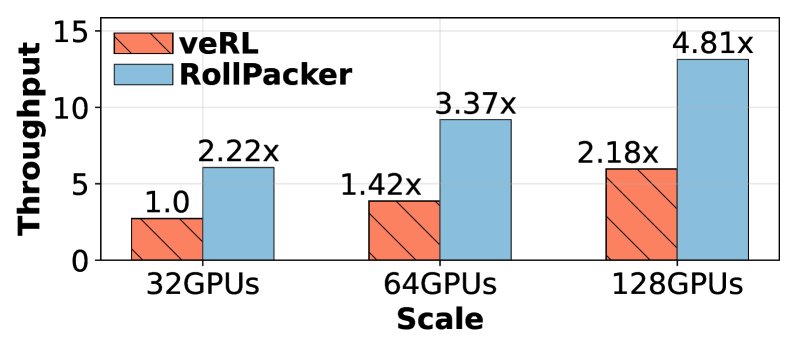
可扩展性分析
在扩展至 128 个 GPU 时,RollPacker 表现出良好的可扩展性。与 veRL 相比,它在各种规模下始终保持约 2.2倍 的吞吐量优势。
总结
本文提出的 RollPacker 系统及其核心的尾部批处理策略,成功解决了同步 RL 训练中因响应长度不均衡导致的效率低下问题。通过将长短响应分离调度,并结合并行规划、奖励调度和流式训练等一系列系统级优化,RollPacker 在完全保留在策略训练准确性的前提下,实现了对 LLM 后训练过程的显著端到端加速,为大规模、高性能的 RL 对齐训练提供了有效的解决方案。