SAM 2: Segment Anything in Images and Videos
-
ArXiv URL: http://arxiv.org/abs/2408.00714v2
-
作者: Christoph Feichtenhofer; Chao-Yuan Wu; Ronghang Hu; Piotr Doll’ar; Laura Gustafson; Chloé Rolland; Haitham Khedr; Junting Pan; Roman Rädle; Nikhila Ravi; 等8人
-
发布机构: Meta
TL;DR
本文提出了SAM 2,一个统一处理图像和视频中可提示分割任务的基础模型,它通过引入流式记忆架构和构建大规模视频分割数据集SA-V,在显著提升分割精度和交互效率的同时,性能超越了现有方法。
关键定义
- 可提示视觉分割 (Promptable Visual Segmentation, PVS):本文提出的新任务,将可提示图像分割推广到视频领域。用户可以在视频的任意帧上通过提示(如点、框、掩码)来定义或修正一个感兴趣的分割目标,模型则需要预测该目标在整个视频中的时空掩码(masklet)。
- 掩码集 (Masklet):指一个目标在视频中的时空掩码(spatio-temporal mask),即该目标在视频每一帧上的分割掩码序列。它是 PVS 任务的输出。
- 数据引擎 (Data Engine):一个用于收集大规模视频分割数据集SA-V的系统。它采用“模型在环”(model-in-the-loop)的模式,让人类标注员与模型(SAM 2)进行交互,高效地标注具挑战性的新数据,然后用这些数据反过来迭代优化模型。
- 流式记忆 (Streaming Memory):SAM 2 的核心架构组件,使模型能以流式方式(一次一帧)处理视频。它通过一个记忆库(Memory Bank)存储过去帧的预测和用户提示信息,从而在处理当前帧时能够利用历史上下文,实现对目标的持续跟踪和高效修正。
相关工作
当前,视觉分割领域在处理视频时面临诸多挑战。以SAM为代表的图像分割模型虽然强大,但仅限于静态图像,无法处理视频中的动态变化。
现有的视频分割方法主要分为两类:
- 交互式视频对象分割 (iVOS):通常采用模块化设计,如将SAM与一个独立的视频追踪器结合。这种方法的缺点是:追踪器可能对某些对象失效,SAM在视频帧上的表现可能不佳,且当追踪失败时,修正过程复杂,通常需要从头重新标注,缺乏对历史信息的记忆。
- 半监督视频对象分割 (VOS):依赖于在第一帧提供一个高质量的掩码,然后追踪到视频结尾。这只是PVS任务的一个特例,且在实际应用中,为第一帧精确标注掩码既困难又耗时。
同时,现有的视频分割数据集在规模和多样性上存在不足,大多只关注车辆、动物等特定类别的完整对象,缺乏对任意物体(things and stuff)及其组成部分(parts)的覆盖。
本文旨在解决上述问题,即创建一个统一的、能够“分割万物”的基础模型,它既能处理图像也能处理视频,支持在整个视频流中进行灵活的交互式分割,并且通过构建一个前所未有的大规模、多样化的视频分割数据集来支撑这一能力。
本文方法
本文的核心贡献是一个统一的模型(SAM 2),一个创新的数据收集引擎,以及一个大规模的数据集(SA-V)。
SAM 2 模型架构
SAM 2 可以被看作是 SAM 在视频领域的自然泛化。它采用流式处理架构,逐帧消费视频,并通过一个记忆机制来维持对目标对象的时空理解。当处理单张图片时(可视为单帧视频),记忆库为空,其行为退化为与SAM类似。
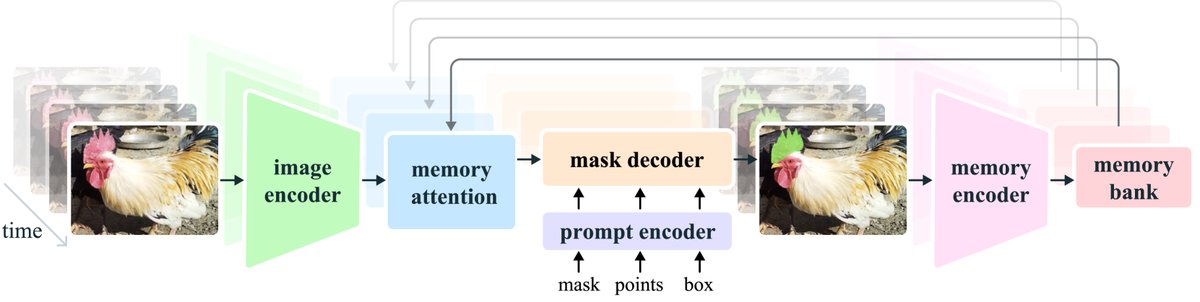 图 3: SAM 2 架构。 对于给定帧,分割预测依赖于当前提示和/或先前观察到的记忆。视频以流式方式处理,图像编码器逐帧处理,并与之前帧的目标记忆进行交叉注意力计算。掩码解码器(可选地接收输入提示)预测该帧的分割掩码。最后,记忆编码器转换预测和图像编码器嵌入,以供未来帧使用。
图 3: SAM 2 架构。 对于给定帧,分割预测依赖于当前提示和/或先前观察到的记忆。视频以流式方式处理,图像编码器逐帧处理,并与之前帧的目标记忆进行交叉注意力计算。掩码解码器(可选地接收输入提示)预测该帧的分割掩码。最后,记忆编码器转换预测和图像编码器嵌入,以供未来帧使用。
其主要组件包括:
- 图像编码器 (Image Encoder):采用 MAE 预训练的 Hiera 分层式编码器。它为视频的每一帧提取多尺度的特征嵌入(tokens),整个交互过程只运行一次。
- 记忆库 (Memory Bank):这是实现时间感知的关键。它由两个先进先出(FIFO)队列组成,分别存储:
- 最近 $N$ 帧的记忆(包含预测掩码和特征)。
- 最多 $M$ 个被用户提示过的关键帧的记忆。 此外,它还存储轻量级的对象指针 (object pointers),即从掩码解码器输出中提炼出的高级语义向量。
- 记忆注意力 (Memory Attention):该模块是连接过去与现在的桥梁。它通过Transformer块中的交叉注意力机制,将当前帧的原始特征与记忆库中存储的历史帧特征、预测以及对象指针进行融合,生成一个包含了上下文信息的时务实征。
- 提示编码器与掩码解码器 (Prompt Encoder and Mask Decoder):基本沿用 SAM 的设计,处理点、框、掩码等稀疏和密集提示。解码器接收经由记忆注意力模块调整后的帧特征和用户提示,输出分割掩码。与SAM不同的是,SAM 2 增加了一个额外的预测头,用于判断目标对象在当前帧是否存在(例如被遮挡),并引入了从分层图像编码器到解码器的跳跃连接,以利用高分辨率特征提升掩码的精细度。
- 记忆编码器 (Memory Encoder):负责生成要存入记忆库的“记忆”。它将当前帧的输出掩码进行下采样,并与原始的帧特征进行融合,形成一个紧凑的表示。
创新点
- 统一流式架构:SAM 2 不是“SAM + 追踪器”的拼接组合,而是一个端到端的统一模型。其流式记忆机制使其能自然地处理视频,无需为图像和视频设计两套分离的系统。
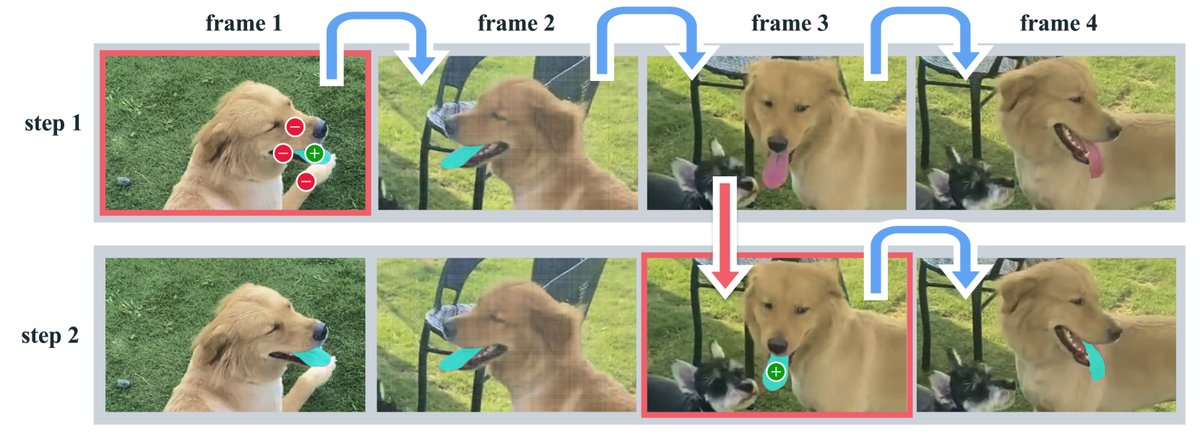
- 高效的交互式修正:得益于记忆机制,模型能够记住对象的历史信息。当追踪发生错误时,用户仅需在后续帧提供少量提示(如一次点击),模型就能利用存储的上下文信息恢复正确的分割,而无需像传统方法那样从头开始重新标注整个对象。如下图所示,修正舌头的分割仅需在第3帧进行一次点击。
- 任务泛化能力:模型设计使其能够自然地从视频任务泛化到图像任务,实现了对两种模态的统一建模。
数据引擎与SA-V数据集
为了训练强大的 SAM 2,本文构建了一个高效的数据引擎,通过三个阶段的迭代,收集了迄今为止规模最大的视频分割数据集 SA-V (Segment Anything Video)。
- 数据引擎演进:
- 阶段1 (SAM per frame):完全手动,使用 SAM 逐帧标注。速度慢(37.8秒/帧),但质量高。
- 阶段2 (SAM + SAM 2 Mask):使用 SAM 标注首帧,再用一个只接受掩码输入的早期版 SAM 2 进行传播和修正。速度提升至 7.4秒/帧。
- 阶段3 (SAM 2):使用完整的 SAM 2 进行交互式标注。标注员只需通过少量点击即可完成修正,效率最高(4.5秒/帧),速度比阶段1提升了 8.4倍。
| | 模型在环 | 每帧时间 | 编辑帧比例 | 每次点击帧的点击数 | 与阶段1的掩码对齐得分 (IoU>0.75) | | :— | :— | :— | :— | :— | :— | | 阶段 1 | 仅 SAM | 37.8 s | 100.00 % | 4.80 | - | | 阶段 2 | SAM + SAM 2 Mask | 7.4 s | 23.25 % | 3.61 | 86.4 % | | 阶段 3 | SAM 2 | 4.5 s | 19.04 % | 2.68 | 89.1 % | 表1: 数据引擎各阶段效率与质量对比。
- SA-V 数据集: 最终发布的 SA-V 数据集包含 5.09万个视频、64.26万个掩码集(masklets),总计 3550万个掩码。其掩码数量比任何现有的VOS数据集多出 53倍以上。该数据集不仅包含完整对象,还广泛覆盖了物体的部件,且具有很高的遮挡和重现率(消失率为42.5%),为训练“分割视频万物”模型提供了坚实基础。
| 数据集 | 视频数 (K) | 掩码集数 (K) | 掩码数 (M) | | :— | :— | :— | :— | | YouTube-VOS | 4.5 | 8.6 | 0.2 | | BURST | 2.9 | 16.1 | 0.6 | | MOSE | 2.1 | 5.2 | 0.4 | | SA-V Manual | 50.9 | 190.9 | 10.0 | | SA-V Manual+Auto | 50.9 | 642.6 | 35.5 | 表3: SA-V 数据集与其它VOS数据集的规模对比(部分)。
实验结论
本文通过在多个基准上的零样本实验,全面验证了 SAM 2 的性能。
-
交互式视频分割 (PVS) 性能: 在模拟用户交互的场景下,SAM 2 的表现远超 SAM+XMem++ 和 SAM+Cutie 等强基线。它能用 少3倍以上 的交互次数(点击)达到更高的分割精度,证明了其记忆机制在交互修正上的优越性。
-
半监督VOS性能: 在传统的 VOS 任务上(仅在第一帧提供提示),SAM 2 同样全面超越了为该任务专门设计的 XMem++ 和 Cutie。这表明 SAM 2 不仅擅长交互,在非交互式追踪任务上同样强大。
| 方法 | 1-click | 3-click | 5-click | bounding box | ground-truth mask | | :— | :— | :— | :— | :— | :— | | SAM+XMem++ | 56.9 | 68.4 | 70.6 | 67.6 | 72.7 | | SAM+Cutie | 56.7 | 70.1 | 72.2 | 69.4 | 74.1 | | SAM 2 | 64.7 | 75.3 | 77.6 | 74.4 | 79.3 | 表4: 在17个视频数据集上的零样本平均准确率 ($\mathcal{J}\&\mathcal{F}$) 对比。
-
图像分割性能: 在 SAM 的原始评测基准上,SAM 2 不仅比 SAM 精度更高(1-click mIoU: 58.9 vs 58.1),而且速度快6倍(130.1 FPS vs 21.7 FPS),这主要归功于更高效的 Hiera 图像编码器。使用本文收集的视频数据进行混合训练后,性能得到进一步提升。
-
与SOTA模型的对比: 在多个主流 VOS 验证集上(如 DAVIS, YTVOS, MOSE),SAM 2 均取得了当前最佳(SOTA)性能。特别是在本文新提出的更具挑战性的 SA-V 测试集上,SAM 2 的性能(77.0 $\mathcal{J}\&\mathcal{F}$)远超所有先前方法(最佳约为62.7),凸显了其在“分割视频万物”能力上的巨大优势。
| 方法 | MOSE val | DAVIS 2017 val | YTVOS 2019 val | SA-V test | | :— | :— | :— | :— | :— | | Cutie-base+ | 71.7 | 88.1 | 87.5 | 62.8 | | SAM 2 (Hiera-B+) | 76.6 | 90.2 | 88.6 | 77.0 | 表6: VOS 任务与SOTA方法的性能对比(部分)。
最终结论: SAM 2 通过创新的流式记忆架构,成功地将强大的可提示分割能力从图像扩展到了视频领域,创建了一个统一、高效且高性能的基础模型。结合其配套的超大规模SA-V数据集和数据引擎,本文为视觉感知领域树立了新的里程碑,将推动相关研究和应用的进一步发展。