Scaling Beyond Context: A Survey of Multimodal Retrieval-Augmented Generation for Document Understanding
-
ArXiv URL: http://arxiv.org/abs/2510.15253v1
-
作者: Weihua Luo; Yong Xien Chng; Sensen Gao; Qing-Guo Chen; Shanshan Zhao; Kaifu Zhang; Mingming Gong; Jia-Wang Bian; Xu Jiang; Lunhao Duan
-
发布机构: Alibaba International Digital Commerce Group; MBZUAI; Tsinghua University; University of Melbourne; Wuhan University
引言
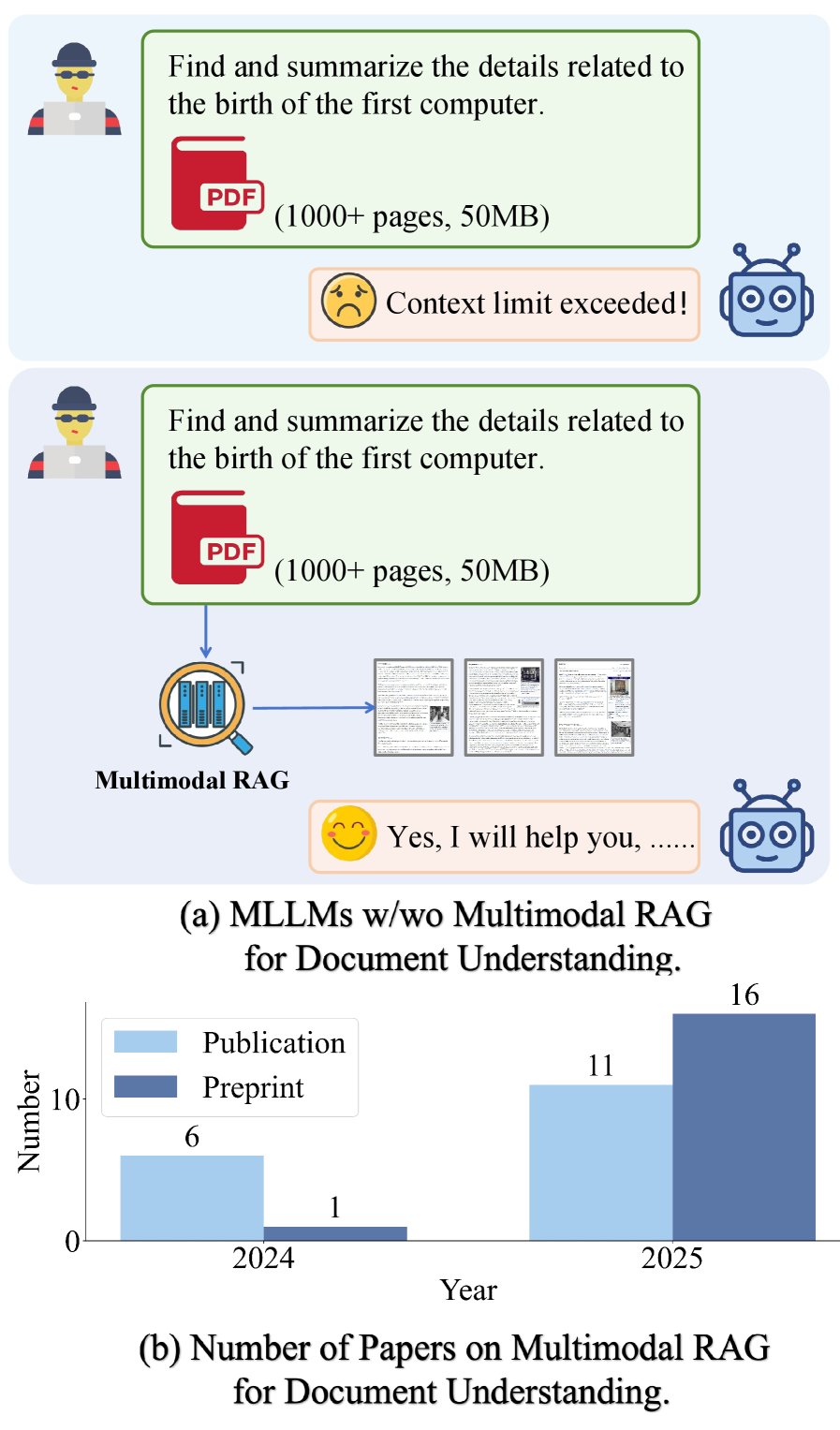 (a) 在长文档理解任务中,使用与不使用多模态RAG的多模态大语言模型(MLLM)的对比。(b) 2024年至2025年相关出版物的增长情况。
(a) 在长文档理解任务中,使用与不使用多模态RAG的多模态大语言模型(MLLM)的对比。(b) 2024年至2025年相关出版物的增长情况。
文档理解是信息时代的一项关键任务,它使机器能够自动解释、组织和推理海量非结构化和半结构化文档。早期研究主要集中于以文本为中心的文档,依赖光学字符识别(OCR)技术进行布局分析和关键信息提取。然而,现实场景中的文档,尤其是科学领域的文档,通常是视觉丰富的,包含表格、图表和图像等复杂元素。随着大语言模型(LLM)的飞速发展,对理解复杂多样文档的需求日益增长。
在视觉丰富文档理解领域,为整合布局、文本和结构信息,涌现了多种方法。原生多模态大语言模型(Multimodal LLM, MLLM)方法通常将文档表示为长图像序列,但这在处理数百页的长文档时会遇到序列长度限制和幻觉风险。为了提高模块性和鲁棒性,基于智能体(Agent-based)的方法引入专门的智能体处理子任务,但这增加了系统复杂性。检索增强生成(Retrieval-Augmented Generation, RAG)通过外部知识来增强模型响应,但传统RAG主要面向文本。
为了解决文本RAG在处理视觉丰富文档时的不足,即无法充分捕捉跨模态线索和结构语义,近期的研究焦点转向了多模态RAG(Multimodal RAG)。这些方法通过更细粒度的建模(如表格、图表)、图结构索引和多智能体框架,实现了对文档的整体检索与推理。尽管关于RAG和文档理解的综述已有很多,但很少有研究将两者明确联系起来。本文旨在填补这一空白,首次对用于文档理解的多模态RAG进行系统性综述,提出了一个基于领域、检索模态、粒度和混合增强方法的分类体系,并整理了相关的数据集、基准和未来挑战,为文档AI的未来发展提供路线图。
预备知识
在RAG系统中,系统首先检索一组相关的文档页面,然后基于这些证据生成响应。检索可以是封闭域(closed-domain,限定于单个源文档)或开放域(open-domain,搜索大型语料库)。假设候选池为 $D={d_i}_{i=1}^{N}$,每个文档 $d_i$ 可能包含光栅图像以及OCR文本 $T_i$。使用特定模态的编码器,将查询和文档映射到共享的嵌入空间。
查询 $q$ 通常是文本,因此在共享空间中计算文本-文本和文本-图像的相似度。文档和查询的嵌入表示为:$z_{i}^{\mathrm{img}}=\mathrm{Enc}_{\mathrm{img}}(d_{i})$,$z_{i}^{\mathrm{text}}=\mathrm{Enc}_{\mathrm{text}}(T_{i})$,以及 $e_{q}^{\mathrm{text}}=\mathrm{Enc}_{\mathrm{text}}(q)$。两种模态对的相似度通过内积计算:$s_{\mathrm{text}}(e_{q},z_{i})=\langle e_{q}^{\mathrm{text}},z_{i}^{\mathrm{text}}\rangle$ 和 $s_{\mathrm{img}}(e_{q},z_{i})=\langle e_{q}^{\mathrm{text}},z_{i}^{\mathrm{img}}\rangle$。
纯视觉检索
仅使用图像通道时,根据得分 $s_{\mathrm{img}}(e_q, z_i)$ 对文档进行排序,并选择超过阈值 $\tau_{\mathrm{img}}$ 的文档(或取前K个结果):
\[X_{\mathrm{img}}=\left\{\,d_{i}\in D\;\middle \mid \;s_{\mathrm{img}}(e_{q},z_{i})\geq\tau_{\mathrm{img}}\,\right\}.\]视觉-文本联合检索
两种常用策略:
-
置信度加权融合:图像和文本分数通过一个凸权重 $\lambda_i \in [0,1]$ 进行组合,该权重反映了对项目 $d_i$ 的图像模态的置信度。
\[s_{\mathrm{conf}}(e_{q},z_{i}) = \lambda_{i}\,s_{\mathrm{img}}(e_{q},z_{i}) + \bigl(1-\lambda_{i}\bigr)\,s_{\mathrm{text}}(e_{q},z_{i}),\] \[X_{\mathrm{conf}} = \left\{\,d_{i}\in D\;\middle \mid \;s_{\mathrm{conf}}(e_{q},z_{i})\geq\tau_{\mathrm{conf}}\,\right\}.\] -
独立检索后合并:首先使用各自的模态独立检索页面,然后取结果的并集。
\[X_{\mathrm{img}} = \left\{\,d_{i}\in D\;\middle \mid \;s_{\mathrm{img}}(e_{q},z_{i})\geq\tau_{\mathrm{img}}\,\right\},\] \[X_{\mathrm{text}} = \left\{\,d_{i}\in D\;\middle \mid \;s_{\mathrm{text}}(e_{q},z_{i})\geq\tau_{\mathrm{text}}\,\right\},\] \[X_{\cup} = X_{\mathrm{img}}\cup X_{\mathrm{text}}.\]
生成
生成器 $\mathcal{G}$ 基于原始查询 $q$ 和检索到的上下文 $X$(可以是 $X_{\mathrm{img}}$, $X_{\mathrm{conf}}$, 或 $X_{\cup}$)生成最终响应 $r$。
\[r=\mathcal{G}(q,X).\]关键创新与方法论
本文从领域开放性、检索模态、检索粒度、基于图的集成和基于智能体的增强等维度对多模态RAG方法进行系统性分类和讨论。
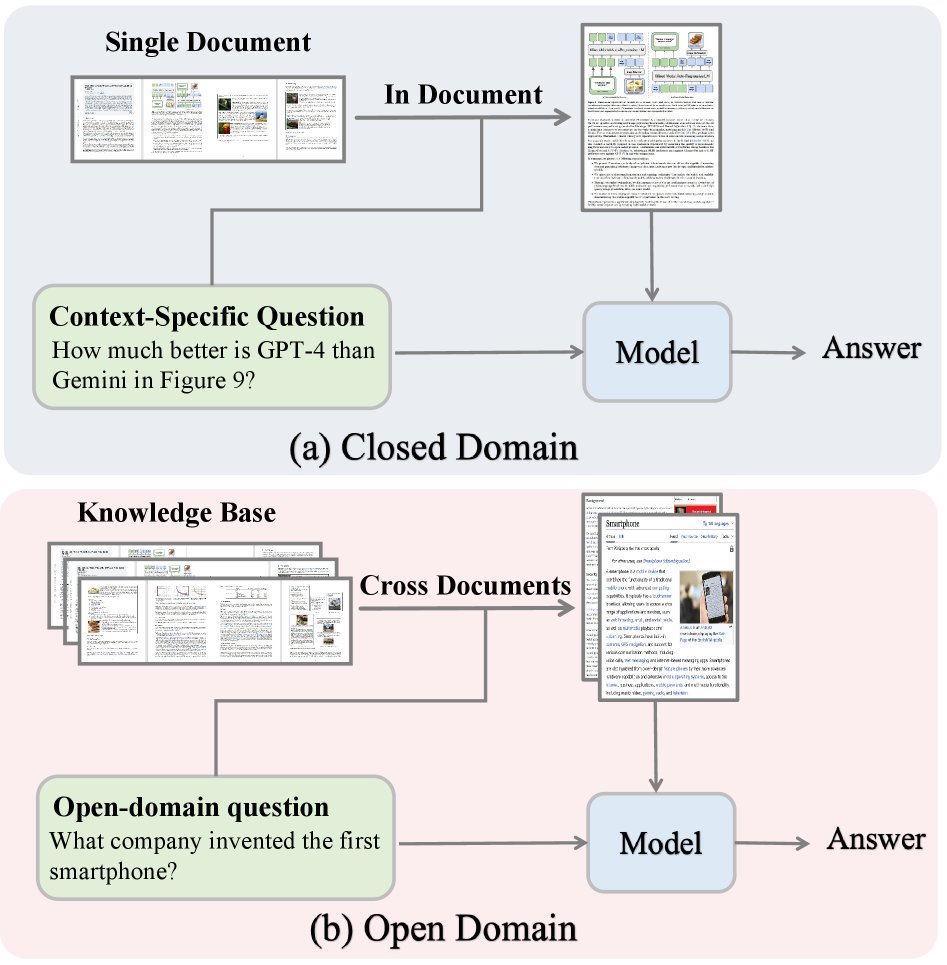 (a) 在封闭域中,模型利用单文档内的检索来回答特定上下文的问题。(b) 在开放域中,模型依赖于跨多份文档的检索来回答开放性问题。
(a) 在封闭域中,模型利用单文档内的检索来回答特定上下文的问题。(b) 在开放域中,模型依赖于跨多份文档的检索来回答开放性问题。
开放域与封闭域
RAG系统根据其检索范围分为开放域和封闭域。
开放域多模态RAG从大规模文档语料库中检索信息,以构建广泛的知识库,增强LLM在特定领域的知识。早期方法依赖OCR构建文本索引,计算成本高。近期方法如DSE和ColPali利用视觉语言模型(VLM)直接编码文档页面,提高了效率。为解决多数方法仅限于单文档内推理的问题,M3DocRAG引入近似索引以加速大规模检索,而VDocRAG则通过将视觉内容压缩为与文本对齐的密集Token表示来减少页面级信息损失。
封闭域多模态RAG专注于单个长文档,仅检索最相关的页面片段作为MLLM的输入,以解决MLLM的上下文窗口限制和幻觉问题。例如,SV-RAG利用MLLM自身作为多模态检索器,FRAG独立评分每个页面并进行Top-K选择,CREAM则引入了从粗到细的多模态检索框架。这些方法均证明了封闭域RAG能在不扩展模型上下文长度的情况下,有效理解长文档。
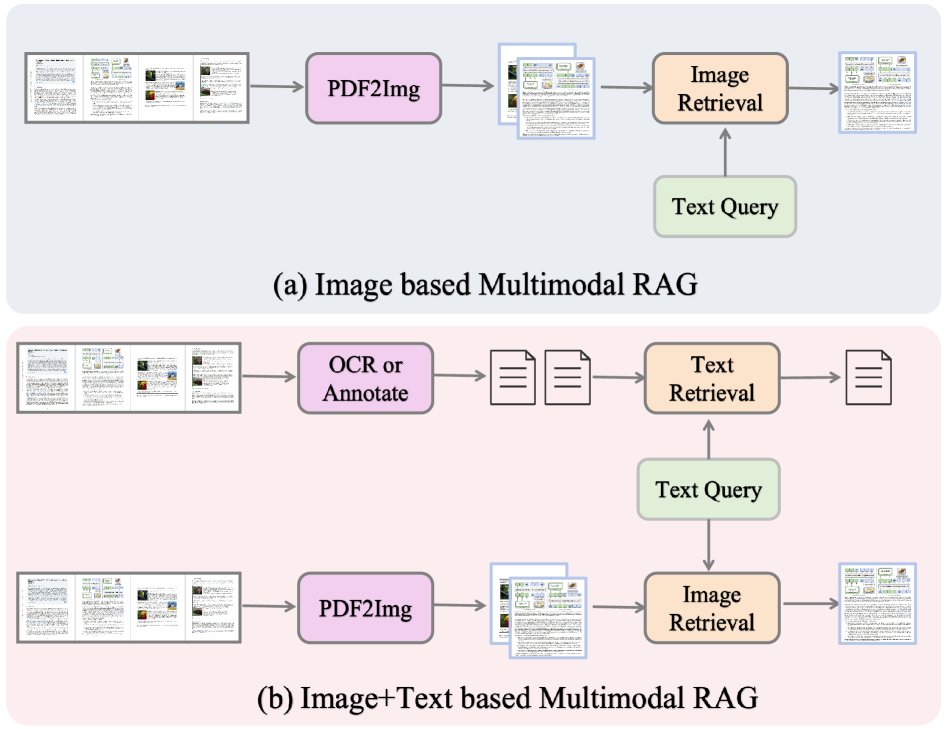 (a) 基于图像的RAG仅从页面图像中检索信息,效率高但文本细节有限;(b) 基于图像+文本的RAG结合了OCR/注释与视觉特征,实现了更丰富的检索,但处理复杂性更高。
(a) 基于图像的RAG仅从页面图像中检索信息,效率高但文本细节有限;(b) 基于图像+文本的RAG结合了OCR/注释与视觉特征,实现了更丰富的检索,但处理复杂性更高。
检索模态
根据用于检索的信息类型,方法可分为纯图像检索和图像-文本混合检索。
纯图像检索将每个文档页面视为一张图像,并使用VLM的视觉编码器将其编码为页面级表示。查询同样被编码,通过计算相似度来对页面进行排序和检索。例如,MM-R5在图像嵌入基础上引入了推理增强的重排器(reranker),而Light-ColPali则通过Token合并技术减少嵌入大小,实现高内存效率的视觉文档检索。
图像-文本混合检索结合了视觉和文本两种模态,以缓解仅依赖视觉编码器时细粒度文本信息的损失。文本通道通常通过OCR提取或由大型VLM生成摘要注释。VisDomRAG和HM-RAG采用双路流水线,对每个模态分别进行检索和推理,然后融合结果。而ViDoRAG和PREMIR则先在各模态内检索,然后合并候选集再进行答案生成。SimpleDoc采用两阶段方案:先基于嵌入选择候选,再利用VLM生成的页面摘要进行重排。
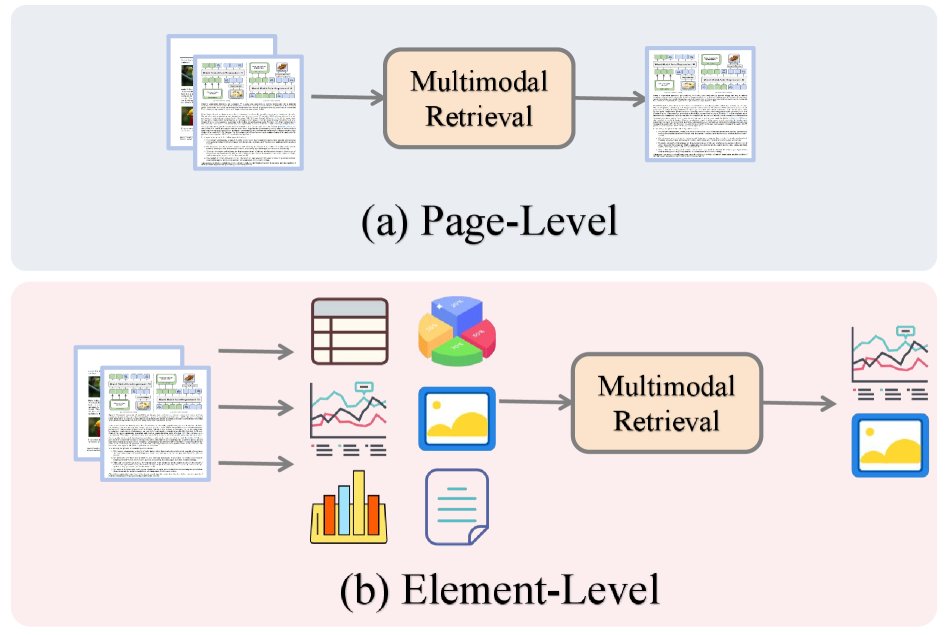 (a) 页面级:将整个页面作为原子单元进行编码和排序。(b) 元素级:将页面分解为表格、图表、图像和文本块;检索在这些元素上操作以定位证据并聚合结果。
(a) 页面级:将整个页面作为原子单元进行编码和排序。(b) 元素级:将页面分解为表格、图表、图像和文本块;检索在这些元素上操作以定位证据并聚合结果。
检索粒度
检索操作的最小单元定义了检索的粒度,从页面级到更精细的元素级。
早期的研究通常以页面为原子检索单元,忽略了页面内的表格、图表等精细结构。近期工作越来越关注页内细粒度检索。一些方法通过显式编码这些组件来提升检索精度。例如,VRAG-RL通过强化学习使LLM能关注到检索页面内与查询直接相关的细粒度区域。MG-RAG采用多粒度策略,允许在页面、表格和图像等不同层级进行检索。DocVQA-RAP引入效用驱动的检索机制,优先选择对答案质量贡献大的文档片段。MMRAG-DocQA利用层级索引和多粒度语义检索来捕捉细粒度的多模态关联。mKG-RAG则利用多模态知识图谱进行两阶段检索,以优化证据选择。PREMIR通过为表格和图表生成预定义的问答对,实现页内细粒度检索。
混合增强方法
为进一步提升多模态RAG的性能,研究者引入了图结构和智能体框架。
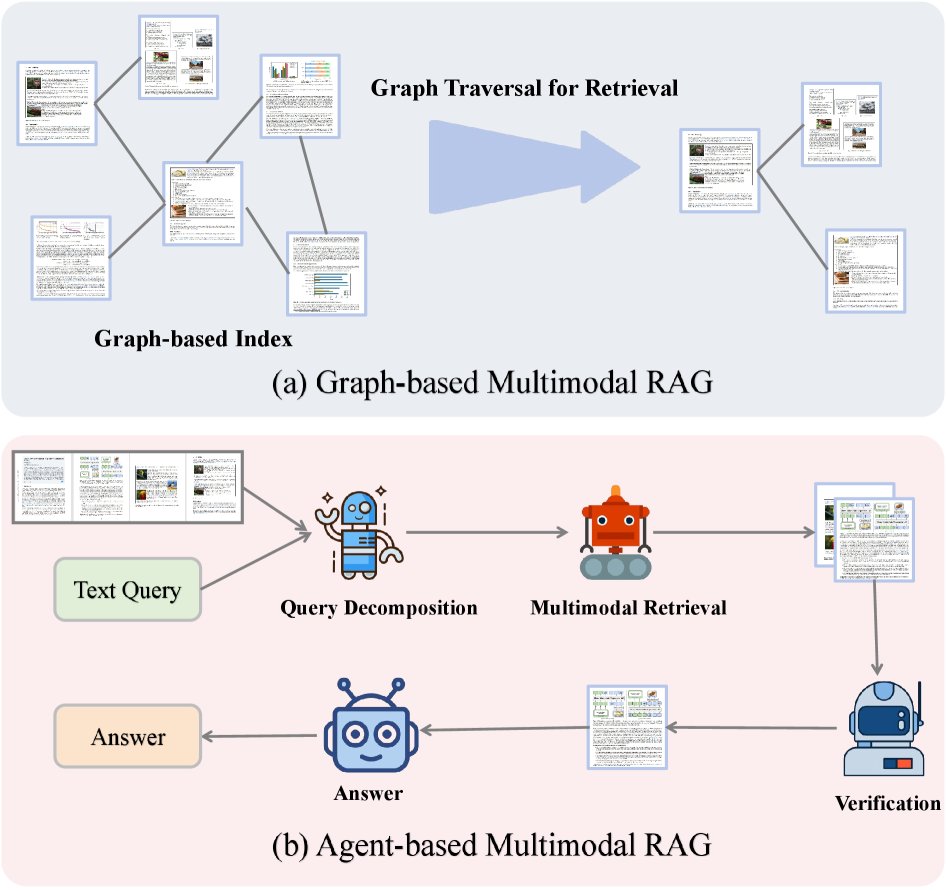 (a) 基于图:文档/元素构成一个图索引,通过图遍历来检索相关邻域。(b) 基于智能体:一个LLM智能体分解文本查询,协调多模态检索,验证收集的证据,并综合生成最终答案。
(a) 基于图:文档/元素构成一个图索引,通过图遍历来检索相关邻域。(b) 基于智能体:一个LLM智能体分解文本查询,协调多模态检索,验证收集的证据,并综合生成最终答案。
基于图的多模态RAG
该方法将多模态内容表示为一个显式图,节点代表模态或内容单元(如页面、文本块、图像、表格),边代表它们之间的语义、空间和上下文关系。在此图上进行检索和推理能更有效地整合异构证据。例如,HM-RAG将基于图的数据库作为多源检索的关键模态之一。mKG-RAG则显式构建多模态知识图谱,作为结构化知识库来提升检索精度。MoLoRAG利用编码了页面间逻辑关系的页面图,通过图遍历来检索证据。
基于智能体的多模态RAG
该方法部署自主智能体来协调检索-生成过程。这些智能体能动态地制定查询、选择检索策略,并根据任务需求自适应地融合来自多模态的信息。例如,ViDoRAG引入了负责探索、总结和反思的迭代式智能体工作流。HM-RAG设计了一个层级化多智能体架构,包括分解智能体、检索智能体和决策智能体。Patho-AgenticRAG则在医疗领域使用智能体进行任务分解和多轮搜索交互。这些框架展示了专门的智能体设计如何提升多模态RAG系统的细粒度检索和推理能力。
数据集与基准
用于文档理解的多模态RAG研究所使用的数据集和基准通常包含视觉丰富的文档集合。下表对现有数据集和基准进行了总结。
| 数据集/基准 | 查询数 | 数据集规模 | 内容类型 | 简介 |
|---|---|---|---|---|
| 常用数据集 | ||||
| DocVQA | 50k | 12k (I) | q! | 视觉问答,关注文档图像 |
| InfographicVQA | 30k | 5k (I) | q! | 针对信息图的视觉问答 |
| ChartQA | 32k | 27k (I) | q! | 针对图表的问答 |
| Kleister-NDA | 0.5k | 0.5k (D) | q! | 从法律文件中提取信息 |
| TAT-QA | 16k | 16k (I) | q! | 表格和文本混合的问答 |
| 新兴基准 | ||||
| ViDoRe | 43k | 41k (D) | q!1 | 跨学术和实践领域的综合基准 |
| VISR-BENCH | 2k | 262 (D) | q!1 | 人工验证的多样化数据集 |
| M3DocVQA | 6k | 3k (D) | q!1 | 开放域、跨文档视觉问答 |
| VisDoMBench | 2k | 1k (D) | q! | 开放域、跨文档视觉问答 |
| OpenDocVQA | 1k | 39k (D) | q! | 开放域、跨文档视觉问答 |
| ViDoSeek | 84k | 4.8k (D) | q!1 | 针对RAG系统设计的视觉丰富文档集 |
注:q: 文本, !: 表格, Charts: 图表, 1: 幻灯片。 (D)指文档数, (I)指图像数。
许多现有方法也指出了当前基准的不足,并构建了新的、更多样化的基准。例如,ColPali构建了ViDoRe,一个跨越能源、政府和医疗等领域的综合基准。为了解决现有基准大多侧重于单文档检索的问题,M3DocVQA、VisDoMRAG和VDocRAG分别引入了开放域基准M3DocVQA、VisDoMBench和OpenDocVQA。ViDoRAG则推出了ViDoSeek,一个专为RAG系统设计的视觉丰富文档数据集,支持在真实检索设置下进行严格评估。
应用
多模态RAG在金融、科研和调查分析等领域的文档理解中应用日益广泛。
- 金融领域:MultiFinRAG通过联合建模文本、表格和图表来改进财务报告的问答效果。FinRAGBench-V则提供了一个强调视觉引用的基准,以实现证据的可追溯性。
- 科研领域:HiPerRAG支持在百万级研究论文规模上进行跨模态检索和推理。CollEX支持对多模态科学语料库进行交互式探索。
- 社会科学领域:一个基于欧盟民意调查(Eurobarometer)的框架将RAG与MLLM相结合,统一处理文本和信息图,以提高调查数据的可解释性。
这些应用共同证明了多模态RAG如何增强跨领域复杂文档的理解和利用能力。
挑战与未来方向
尽管多模态RAG在文档理解方面取得了持续进展,但仍存在若干开放性挑战,为未来研究指明了方向。
-
效率 (Efficiency):集成高维视觉和文本特征会产生巨大的计算成本,限制了可扩展性。未来的研究方向包括设计轻量级多模态编码器、自适应检索策略以及内存高效的融合机制,以在不牺牲检索精度的情况下降低延迟。
-
更细粒度的文档表示 (Finer-grained document representations):许多现有模型在页面或段落级别操作,忽略了表格、图表、脚注和布局等微观结构语义。能够捕捉微观结构同时保持宏观上下文的层级化编码器和注意力机制,可以提高模型的可解释性,并增强下游的推理和决策能力。
-
安全性与鲁棒性 (Security and robustness):模型需要具备抵御对抗性攻击和错误信息的能力,确保检索到的信息是可信的,并且生成的内容是可靠的。未来的工作需要关注如何验证多模态信息的来源和一致性,并设计更鲁棒的端到端系统。