SCRIBES: Web-Scale Script-Based Semi-Structured Data Extraction with Reinforcement Learning
-
ArXiv URL: http://arxiv.org/abs/2510.01832v1
-
作者: Zhaojiang Lin; Wen-tau Yih; Lisheng Fu; Kai Sun; Shicheng Liu; Yue Liu; Xin Luna Dong; Rulin Shao; Xinyuan Zhang; Xilun Chen; 等11人
-
发布机构: Meta; Meta Reality Labs; Stanford University; University of Washington
TL;DR
本文提出了一种名为 SCRIBES 的新型强化学习框架,它通过利用同一网站内网页间的布局相似性作为奖励信号,训练大型语言模型生成可重用的提取脚本,从而实现对网页半结构化数据(如表格和列表)的网络规模、高效率提取。
关键定义
本文提出或沿用了以下几个核心概念:
- SCRIBES (Script-Based Semi-Structured Content Extraction at Web-Scale):本文提出的核心框架名称。它是一个基于强化学习的系统,旨在训练语言模型生成可跨相似网页重用的提取脚本,以实现网络规模的半结构化数据提取。
- 提取脚本 (Extraction Script):由语言模型生成的、可执行的程序或指令。该脚本的目标不是仅处理单个网页,而是能够泛化并应用于同一网站下一组具有相似结构的其他网页,从中提取出结构化数据(通常是三元组)。
- HTML Deduplication (Dedup):本文采用的一种简单而有效的预处理方法。它通过将HTML文档中重复的块折叠成紧凑的表示形式(例如“$n$ more …elements”),显著缩短了输入给模型的上下文长度,从而提升了模型性能。
- 跨页泛化奖励 (Cross-Page Generalization Reward):SCRIBES框架的核心创新。其奖励机制主要基于一个为特定页面 $p$ 生成的脚本,在同组其他相似页面 $q$ 上的执行效果。这种设计激励模型学习能够捕捉共同布局模式的、具有泛化能力的脚本,而非仅仅适用于单个页面的过拟合规则。
相关工作
目前,从网页中提取半结构化数据的方法主要分为两类。传统方法,如包装器归纳 (wrapper induction) 和基于布局的方法,虽然在特定场景下有效,但通常比较“脆弱” (brittle),难以泛化到未见过的数据或网站结构上。
近年来兴起的基于大型语言模型 (LLM) 的方法,虽然能够产生高质量的提取结果,但其主要瓶颈在于资源消耗巨大。这些方法通常需要为每一个网页单独调用一次LLM进行推理,这在网络规模的应用场景下成本过高且效率低下。此外,它们将每个页面视为独立个体,忽略了同一网站内页面间普遍存在的布局规律性。
因此,本文旨在解决的核心问题是:如何以一种资源高效且可扩展的方式,从海量网页中准确、可靠地提取结构化信息,同时克服传统方法的泛化难题和LLM方法的成本瓶颈。
本文方法
本文提出了SCRIBES框架,一个通过强化学习(Reinforcement Learning, RL)训练模型生成通用提取脚本的创新方法。
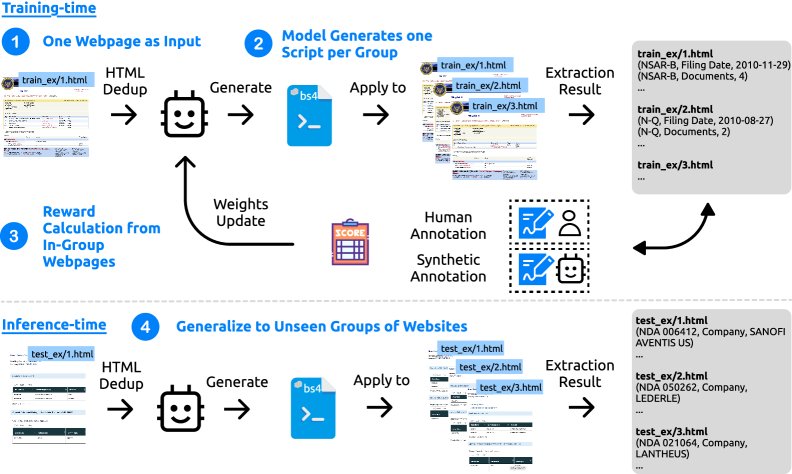
创新点
SCRIBES的核心创新在于其独特的强化学习范式,它不依赖于对脚本本身的直接标注,而是利用网站内网页的结构相似性作为一种天然的监督信号。
其工作流程如下:给定一个网页 $p$,模型被要求生成一个提取脚本 $\hat{y}_p$。这个脚本不仅要在当前页面 $p$ 上表现良好,更重要的是,它必须能成功应用于同一网站内其他结构相似的页面 $q \in G(p)$。
RL 设置与奖励函数
框架将此任务定义为一个RL问题。奖励 $r(p \to q)$ 被定义为:将页面 $p$ 生成的脚本 $\hat{y}_p$ 应用于页面 $q$ 后,提取结果与真实标签 $y^{\star}_q$ 的相似度得分。该得分综合了基于模糊匹配的F1分数 ($F_1^{\text{fuzzy}}$) 和基于LLM作为裁判的评判结果 ($F_1^{\text{LM}}$)。
为了强调泛化能力,本文采用 组相对策略优化 (Group Relative Policy Optimization, GRPO),其奖励函数设计如下:
\[\mathcal{R}_{\textsc{SCRIBES}}(p)=\tfrac{1}{ \mid G(p) \mid }\sum_{q\in G(p)}r(p\!\to\!q)=\tfrac{1}{ \mid G(p) \mid }r_{\text{self}}(p)+\tfrac{ \mid G(p) \mid -1}{ \mid G(p) \mid }\sum_{q\in G(p),p\neq q}r_{\text{cross}}(p,q)\]在这个公式中,$r_{\text{self}}(p)$ 是脚本在源页面上的表现得分,$r_{\text{cross}}(p,q)$ 是其在同组其他页面上的表现得分。由于交叉得分占据了奖励的大部分权重,模型被强力引导去生成能够泛化到未见页面的脚本。
预处理:HTML去重
为了处理LLM的上下文窗口限制,本文提出了一种HTML去重 (Dedup) 方法。它能将HTML中的重复结构性元素(如表格行)折叠,大幅缩减输入Token数量,实验证明这对模型性能有显著提升。
从无标签数据中学习
由于高质量的标注数据稀少,SCRIBES设计了一个巧妙的迭代训练流程,以利用来自野外(in-the-wild)的CommonCrawl(简称CC)无标签数据。
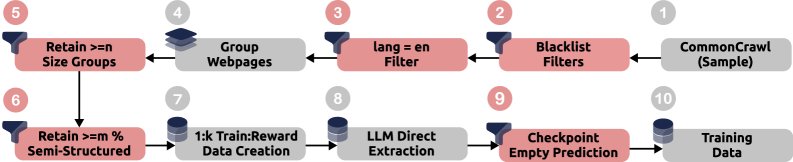
该流程分为几个步骤:
- 数据筛选: 从CC数据中筛选出包含半结构化内容的英文网页,并按域名分组。
- 生成伪标签: 对于一个网页分组,使用强大的LLM直接进行内容提取,其结果作为“合成标注” (synthetic annotations) 或伪标签。
- 聚焦失败案例: 为了避免伪标签的噪声干扰,训练过程并非在所有CC数据上进行。相反,它首先使用在高质量标注数据上训练过的模型进行预测,然后专门挑选出那些模型预测失败(即未提取出任何三元组)的“失败案例” (failure cases) 进行后续的强化学习训练。
- 迭代优化: 通过在这些具有挑战性的失败案例上进行训练,模型能够在不依赖人工标注的情况下,不断扩展其对多样化网页布局的适应能力。
实验结论
脚本生成质量
实验结果表明,经过SCRIBES框架训练的模型在生成可重用提取脚本方面,性能远超各种强大的智能体基线。
与基线模型的性能对比(使用LLM作为裁判的宏平均F1分数 $F_1^{\text{LM}}$)
| 模型系列 | 基线方法 (Best) | 基线 $F_1^{\text{LM}}$ (%) | SCRIBES-训练模型 | SCRIBES $F_1^{\text{LM}}$ (%) | 提升 |
|---|---|---|---|---|---|
| Q-14B | 5-shot agent | 34.6 | Q-14B | 48.4 | +13.8 |
| Q-32B | 5-shot agent | 34.6 | Q-32B | 50.5 | +15.9 |
| GO-120B | 5-shot agent | 50.8 | - | - | - |
如上表所示,经过SCRIBES训练的Q-14B和Q-32B模型,其脚本质量($F_1^{\text{LM}}$)相比于强大的5-shot智能体基线提升超过13%。值得注意的是,SCRIBES训练的Q-32B模型性能已经与体量大得多的GO-120B基线模型持平。
资源效率与可扩展性
SCRIBES在保持高质量的同时,显著提升了资源效率。在一个包含113,129个网页的实验中,模型仅需对4,661个页面进行直接LLM推理以生成脚本,剩余绝大多数页面的数据提取均通过执行这些可重用脚本完成,共提取了2,788,760个三元组。
相较于对每个页面都进行LLM推理的“扁平化”方法,SCRIBES的加速比随相似页面的数量 $k$ 线性增长,公式为:$\text{speedup}=\frac{k}{\rho}$,其中 $\rho \approx 3.7$ 是单页处理的Token比率。这意味着只要一个网站有超过4个结构相似的页面,SCRIBES就开始展现出成本优势。
消融研究
- 奖励设计: 对比实验证实,移除奖励函数中的跨页泛化项后,模型在未见过的“留出”页面上的性能下降了7.2%,证明了SCRIBES奖励设计的关键作用。
- 野外数据训练: 在高质量标注数据上预训练后,再利用CommonCrawl的野外数据进行迭代训练,能使模型性能进一步提升(Q-32B模型提升约5%)。研究还发现,优先训练“失败案例”子集的策略比在所有CC数据上训练效果更好。
错误分析
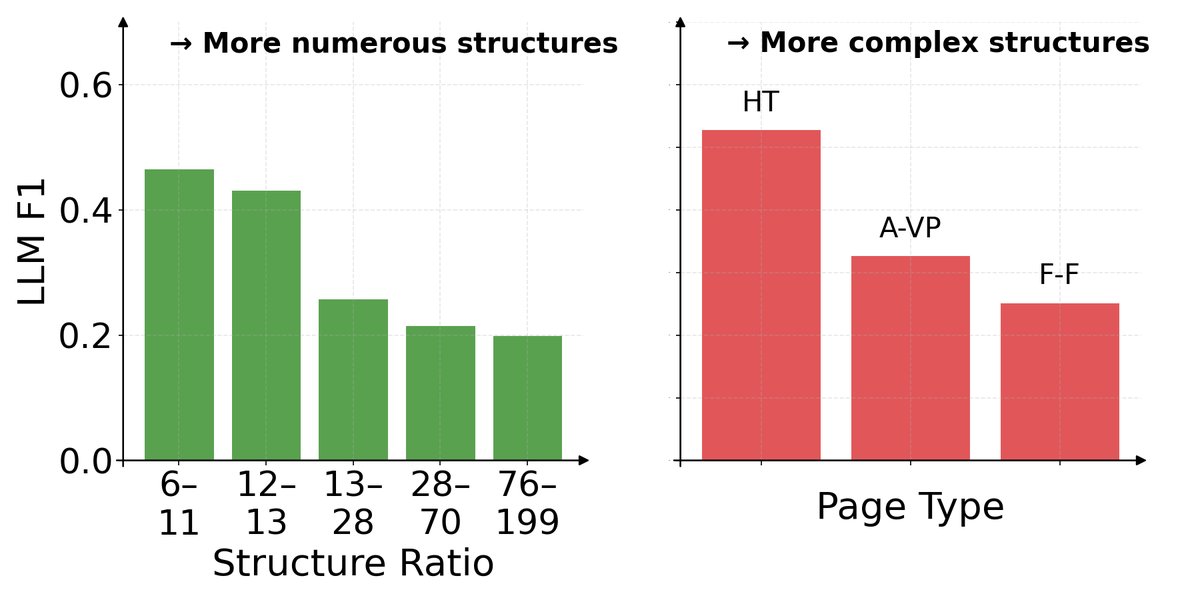 模型在处理结构更复杂(HTML代码与纯文本长度比更高)的页面时性能下降。从页面类型来看,模型处理“水平表格” (Horizontal Tables) 的效果最好,其次是“属性-值对” (Attribute–Value Pairs),而对“自由格式” (Free-Form) 页面的处理效果最差。
模型在处理结构更复杂(HTML代码与纯文本长度比更高)的页面时性能下降。从页面类型来看,模型处理“水平表格” (Horizontal Tables) 的效果最好,其次是“属性-值对” (Attribute–Value Pairs),而对“自由格式” (Free-Form) 页面的处理效果最差。
下游应用:问答任务
将SCRIBES提取的三元组信息增强到问答系统的上下文中,可以显著提升其在处理半结构化数据时的准确率。
不同模型在增加SCRIBES提取的三元组后的QA准确率(%)
| QA模型 | 仅用扁平化HTML | + SCRIBES三元组 | 提升 |
|---|---|---|---|
| GPT-4o | 76.2 | 80.3 | +4.1 |
| Llama-3-70B | 72.4 | 75.5 | +3.1 |
| Qwen-1.5-32B | 68.3 | 71.4 | +3.1 |
| Gemma-7B | 60.1 | 63.2 | +3.1 |
实验表明,无论是对于最前沿的GPT-4o还是各类开源模型,SCRIBES提取的数据均能带来一致的性能增益,证明了其产出数据的实用价值。
总结
本文成功地展示了一个新颖、有效且高效的框架SCRIBES。它通过创新的强化学习奖励机制,使模型能够生成泛化能力强的提取脚本,解决了网络规模下半结构化数据提取的成本与泛化双重难题,为后续在复杂问答、知识图谱构建和模型预训练等领域的研究开辟了新的可能性。