Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
-
ArXiv URL: http://arxiv.org/abs/2310.11511v1
-
作者: Akari Asai; Avirup Sil; Hannaneh Hajishirzi; Yizhong Wang; Zeqiu Wu
-
发布机构: Allen Institute for AI; IBM Research; University of Washington
TL;DR
本文提出了一种名为自反思检索增强生成 (Self-Reflective Retrieval-Augmented Generation, Self-RAG) 的新框架,通过训练一个语言模型,使其能按需自适应地进行检索,并利用特殊的“反思”Token (reflection tokens) 对检索到的信息和自身的生成内容进行反思和评价,从而显著提升生成内容的质量、事实性和可控性。
关键定义
本文的核心是引入了一种新的 Token 类型,即 反思 Token (Reflection Tokens),它们被集成到语言模型的词汇表中,使模型能够进行自我评估。这些 Token 分为两大类:
- 检索 Token (Retrieval Tokens): 用于判断在生成过程中是否需要以及何时需要从外部知识源检索信息。它包含三个可能的值:
- \({yes}\): 表示需要进行检索以获取事实知识。
- \({no}\): 表示仅依靠模型的参数化知识即可回答,无需检索。
- \({continue}\): 表示继续当前的生成任务,可能在后续步骤中需要检索。
- 评价 Token (Critique Tokens): 用于评估检索到的段落的质量以及模型生成内容的好坏。它包含三个子类别:
- IsRel (Relevance): 评估检索到的文档 \(d\) 是否与问题 \(x\) 相关。可能的值为 \({relevant, irrelevant}\)。
- IsSup (Support): 评估模型生成的回复 \(y\) 是否完全被检索到的文档 \(d\) 所支持。可能的值为 \({fully supported, partially supported, no support}\)。
- IsUse (Usefulness): 评估生成回复 \(y\) 的整体有用性,包括事实正确性和全面性。可能的值为 \({1, 2, 3, 4, 5}\),代表从低到高的有用性。
| 类型 | 输入 | 输出 | 定义 |
|---|---|---|---|
| \([Retrieve]\) | $x$ / $x,y$ | {yes, no, continue} | 决定何时使用检索器 $\mathcal{R}$ |
| \([IsRel]\) | $x,d$ | {relevant, irrelevant} | 文档 $d$ 是否为解决问题 $x$ 提供了有用的信息。 |
| \([IsSup]\) | $x,d,y$ | {fully supported, partially supported, no support} | 回复 $y$ 中所有需要验证的陈述是否都得到了文档 $d$ 的支持。 |
| \([IsUse]\) | $x,y$ | {5, 4, 3, 2, 1} | 回复 $y$ 对于问题 $x$ 是否有用。 |
表格1:Self-RAG 中使用的四种反思 Token
相关工作
当前的检索增强生成 (Retrieval-Augmented Generation, RAG) 方法虽然能通过引入外部知识减少大型语言模型 (Large Language Models, LLMs) 的事实性错误,但存在明显瓶颈。
主流的 RAG 方法通常不加区分地为每个输入检索固定数量的文档,无论检索是否必要或者文档是否相关。这种“一刀切”的策略可能引入无关或干扰性信息,导致生成质量下降,同时也损害了 LLM 在不需要事实知识的任务(如创意写作)上的通用性。此外,现有模型并未被显式训练来遵循和利用所提供的段落中的事实,因此无法保证生成结果与引用的来源完全一致。
本文旨在解决上述问题,即如何让 RAG 模型变得更加智能和可控:
- 实现按需检索,只在确实需要外部知识时才启动检索过程。
- 确保生成内容与检索到的证据高度一致和可验证。
- 在提升事实性的同时,不损害模型的通用性和创造力。
本文方法
本文提出 Self-RAG 框架,通过训练一个语言模型 $\mathcal{M}$,使其不仅能生成文本,还能生成特殊的 “反思 Token” 来控制检索和评估自身输出。其核心思想是将“反思”内化为模型自身的能力,而不是依赖外部模块。
 图1:Self-RAG 框架概览。左侧为传统RAG,右侧为 Self-RAG。Self-RAG 学会按需检索、评价和生成文本,以提升整体质量、事实性和可验证性。
图1:Self-RAG 框架概览。左侧为传统RAG,右侧为 Self-RAG。Self-RAG 学会按需检索、评价和生成文本,以提升整体质量、事实性和可验证性。
训练流程
Self-RAG 的训练是一个两阶段过程,旨在高效地将反思能力注入标准 LM 中:
- 训练评价模型 (\(C\)):
- 首先,通过提示工程(prompting)让一个强大的专有模型(如 GPT-4)为一批数据生成反思 Token,从而创建一个高质量的“标注”数据集 $\mathcal{D}_{critic}$。
-
然后,使用这个数据集来微调一个较小的开源模型(如 Llama2-7B),得到一个评价模型 \(C\)。这个模型 \(C\) 的作用就是模仿昂贵的大模型,以低成本为后续步骤生成反思 Token。训练目标是最大化对数似然:
\[\max_{\mathcal{C}}\mathbb{E}_{((x,y),r)\sim\mathcal{D}_{critic}}\log p_{\mathcal{C}}(r \mid x,y)\]
- 训练生成器模型 (\(M\)):
- 利用训练好的评价模型 \(C\) 和一个现成的检索器 \(R\),对原始的指令微调数据集进行离线处理,生成一个增强版的新数据集 $\mathcal{D}_{gen}$。对于每个样本,\(C\) 会预测何时需要检索、检索到的文档是否相关、生成内容是否被支持等,并将相应的反思 Token 插入到文本中。
-
最后,在增强数据集 $\mathcal{D}_{gen}$ 上训练最终的生成器模型 \(M\)(如 Llama2-7B/13B)。训练目标是标准的下一 Token 预测,模型需要同时预测常规文本 Token 和反思 Token。
\[\max_{\mathcal{M}}\mathbb{E}_{(x,y,r)\sim\mathcal{D}_{gen}}\log p_{\mathcal{M}}(y,r \mid x)\] - 这种离线(offline)生成反思 Token 的方式,使得训练生成器 \(M\) 时无需同时运行评价模型,极大降低了训练成本和复杂度,与需要在线奖励模型和复杂强化学习策略的 RLHF 形成对比。
 图2:Self-RAG 训练样本示例。左侧例子不需要检索,右侧例子需要检索并插入了外部段落和相应的反思 Token。
图2:Self-RAG 训练样本示例。左侧例子不需要检索,右侧例子需要检索并插入了外部段落和相应的反思 Token。
推理流程
Self-RAG 的推理过程通过生成反思 Token 实现了高度的可控性和灵活性。
``$$ Algorithm 1: Self-RAG Inference
1: 输入: prompt x, 已生成内容 y_{<t} 2: M 预测 [Retrieve] Token 的概率 3: if [Retrieve] == Yes or 概率 > 阈值 then 4: R 检索相关文档 D 5: for 每个文档 d in D (并行): 6: M 预测 [IsRel] 7: M 生成后续文本 y_t 8: M 预测 [IsSup] 和 [IsUse] 9: 根据 [IsRel], [IsSup], [IsUse] 的分数对生成的 y_t 进行排序,选择最优的一个 10: else if [Retrieve] == No then 11: M 直接生成 y_t 12: M 预测 [IsUse] \(`\)
-
自适应检索 (Adaptive Retrieval): 在生成每个文本片段前,模型首先会预测是否需要检索(即生成 \([Retrieve]\) Token)。这使得模型可以根据任务需求动态决定是否引入外部知识。用户也可以通过设置一个概率阈值来调整检索的频率。
-
树状解码 (Tree Decoding): 当决定进行检索后,系统会取回 \(K\) 个相关文档。模型会并行地处理这 \(K\) 个文档,为每个文档生成一个候选的后续文本片段。
-
基于评价的择优: 模型会对每个候选文本片段生成评价 Token(\(IsRel\), \(IsSup\), \(IsUse\))。然后,通过一个加权评分函数 $\mathcal{S}$ 来计算每个候选片段的综合分数,并选择分数最高的片段作为最终输出。评分函数定义为:
\[\mathcal{S}(\text{Critique}) = \sum_{G \in \{\text{IsRel, IsSup, IsUse}\}} w^G s_t^G\]其中,$s_t^G$ 是某个评价类别(如 \(IsSup\))中最理想 Token(如 \(fully supported\))的归一化概率,$w^G$ 是可调整的权重。通过在推理时调整这些权重,可以轻松地改变模型的行为偏好。例如,为了追求最高的事实准确性,可以增大 \(IsSup\) 的权重 $w^{\text{IsSup}}$。这种方式无需重新训练模型,即可实现灵活控制。
实验结论
本文在包括开放域问答、推理、事实核查和长文本生成在内的六个任务上进行了广泛实验。
| LM | PopQA (acc) | TQA (acc) | Pub (acc) | ARC (acc) | Bio (FS) | ASQA (pre) | ASQA (rec) |
|---|---|---|---|---|---|---|---|
| LMs with proprietary data | |||||||
| Llama2-c$_{13b}$ | 20.0 | 59.3 | 49.4 | 38.4 | 55.9 | – | – |
| Ret-Llama2-c$_{13b}$ | 51.8 | 59.8 | 52.1 | 37.9 | 79.9 | 19.8 | 36.1 |
| ChatGPT | 29.3 | 74.3 | 70.1 | 75.3 | 71.8 | – | – |
| Ret-ChatGPT | 50.8 | 65.7 | 54.7 | 75.3 | – | 65.1 | 76.6 |
| Baselines without retrieval | |||||||
| Alpaca$_{13b}$ | 24.4 | 61.3 | 55.5 | 54.9 | 50.2 | – | – |
| Baselines with retrieval | |||||||
| Alpaca$_{13b}$ | 46.1 | 66.9 | 51.1 | 57.6 | 77.7 | 2.0 | 3.8 |
| Our Self-Rag$_{7b}$ | 54.9 | 66.4 | 72.4 | 67.3 | 81.2 | 66.9 | 67.8 |
| Our Self-Rag$_{13b}$ | 55.8 | 69.3 | 74.5 | 73.1 | 80.2 | 70.3 | 71.3 |
表格2:六个任务上的主要实验结果(节选)。粗体表示非专有模型中的最佳性能。acc=准确率, FS=FactScore, pre=引用精度, rec=引用召回率。
关键实验结果:
- 全面超越基线: Self-RAG(7B和13B)在所有六项任务上均显著优于同等规模的预训练模型(Llama2)和指令微调模型(Alpaca),无论这些基线是否使用检索。
- 优于强大的闭源模型: 在多个任务中,Self-RAG 的表现超过了 ChatGPT 和检索增强的 Llama2-chat。特别是在长文本生成任务 ASQA 上,Self-RAG 在引用精度(citation precision)和引用召回率(citation recall)方面表现出色,7B 模型在引用精度上甚至超过了 Ret-ChatGPT,13B 模型则在两项指标上都接近甚至超越 Ret-ChatGPT。
- 对复杂任务提升显著: 在传统 RAG 方法提升有限的任务上(如事实核查 PubHealth 和推理 ARC),Self-RAG 依然取得了巨大进步。这表明其通过自我评价来筛选和利用证据的机制比简单的信息拼接更为有效。
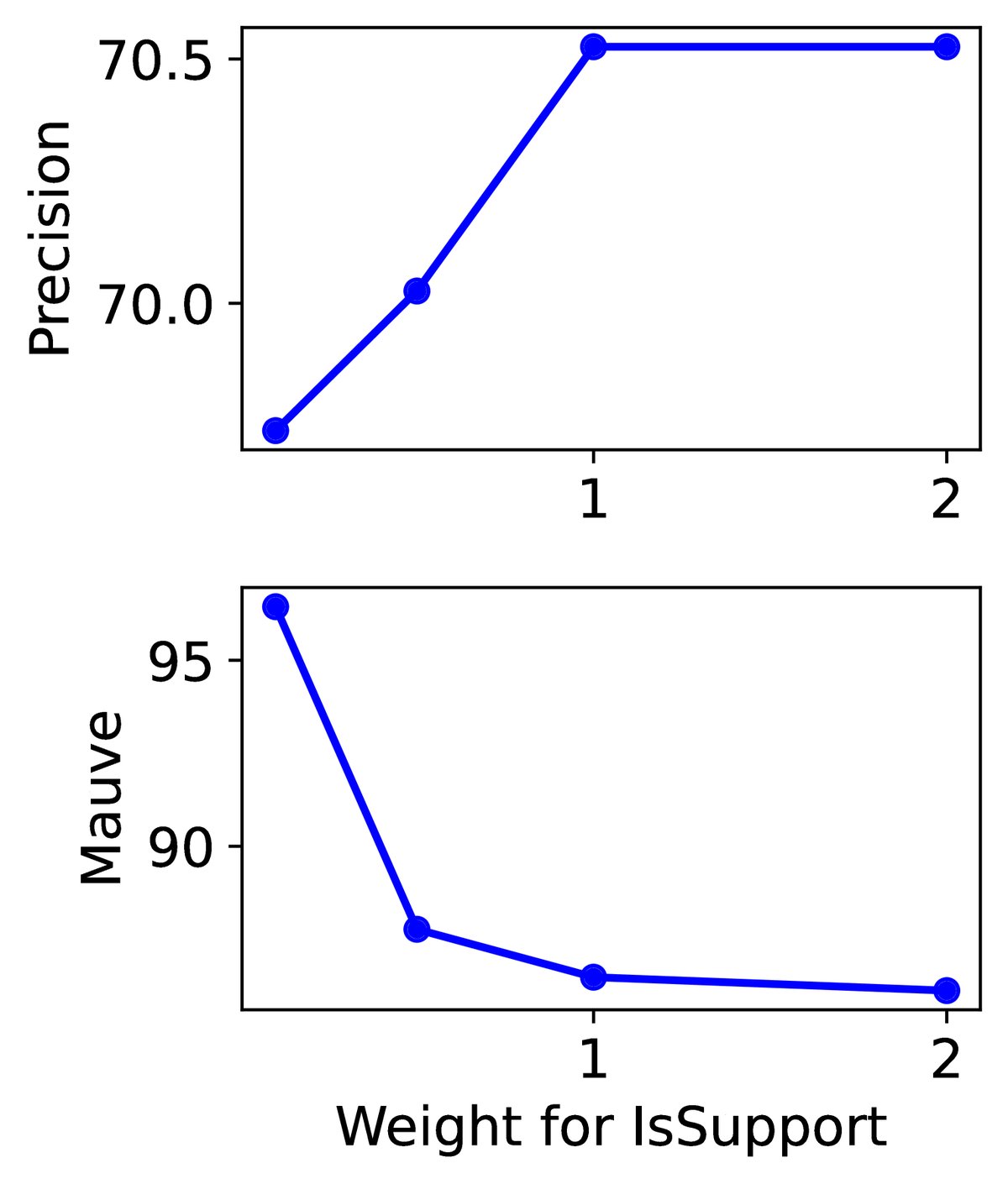
- 可控性验证: 消融实验证明了 Self-RAG 各个组成部分(如评价模型 \(C\)、\(IsSup\) 评价 Token)的有效性。实验还表明,通过在推理时调整评价 Token 的权重,可以有效地在生成内容的流畅性(MAUVE)和事实性(引用精度)之间进行权衡,实现了无需再训练的灵活控制。
 (a)消融研究,显示了移除训练或测试中关键组件后的性能下降。
(a)消融研究,显示了移除训练或测试中关键组件后的性能下降。
 (b)可定制性,展示了调整 $$IsSup` Token 的权重可以在流畅性(Mauve)和引用精度之间进行权衡。
(b)可定制性,展示了调整 $$IsSup` Token 的权重可以在流畅性(Mauve)和引用精度之间进行权衡。
最终结论: Self-RAG 框架成功地训练了一个语言模型,使其具备内在的自我反思能力。通过按需检索和对生成内容进行细粒度的自我评价,Self-RAG 不仅显著提升了生成内容的质量和事实准确性,还提供了强大的推理时可控性。实验结果证明,该方法在多种任务上均优于现有的 LLMs 和 RAG 方法,为构建更可靠、更智能的生成式AI系统提供了新的方向。