SFR-DeepResearch: Towards Effective Reinforcement Learning for Autonomously Reasoning Single Agents
-
ArXiv URL: http://arxiv.org/abs/2509.06283v2
-
作者: Revanth Gangi Reddy; Silvio Savarese; Caiming Xiong; Austin Xu; Xuan-Phi Nguyen; Shafiq Joty; Shrey Pandit
-
发布机构: Salesforce AI Research
TL;DR
本文提出了一种名为 SFR-DeepResearch 的方法,其核心是使用一套完全由合成数据驱动的强化学习(RL)方法,在保留并增强其原有推理能力的基础上,将专为推理优化的语言模型(如 QwQ, Qwen3)转化为用于深度研究(Deep Research)任务的自主单智能体。
关键定义
- 深度研究 (Deep Research, DR): 一类需要智能体对多个信息源进行广泛搜索和复杂推理才能解决的任务,通常涉及网页浏览和代码执行等工具的使用。
- 自主单智能体 (Autonomous Single-Agent): 指一个单独的大语言模型,它能根据当前上下文动态地、自主地决定下一步行动,而无需在中间步骤接受外部指令或被限定在预设的工作流中。这与多智能体系统中角色固定的智能体形成对比。
- 智能体推理脚手架 (Agentic Inference Scaffolding): 本文为稳定和优化智能体多步决策过程而设计的一套框架。它包括一个定制化的多轮交互格式(特别是将多轮对话重构为单轮上下文问答)和一个允许智能体自我管理的内存机制,以支持任意长度的交互。
- 长度归一化强化学习 (Length-normalized RL): 本文对 REINFORCE 算法的一项关键改进。它在计算优势(Advantage)时,用轨迹的长度对奖励信号进行归一化,目的是为了稳定训练过程,防止模型倾向于生成无意义的、过长的工具调用序列。
相关工作
当前,用于深度研究(DR)的智能体系统主要分为单智能体和多智能体两类。多智能体系统(如 OpenManus)通过为不同智能体(规划器、研究员、编码器等)分配预定义角色和工作流来协作完成任务,结构固定但可能缺乏泛化能力。单智能体系统(如 OpenAI DeepResearch)则依赖单个模型自主规划和执行,更为灵活。
以往训练智能体的方法多是从基础(base)或指令微调(SFT)模型开始,通过指令微调和强化学习进行训练。然而,这些方法在应用于已经过推理能力优化的“思考型”模型时,面临着独特的挑战,尤其是在长程的、多步骤的智能体任务中,RL 训练过程容易变得不稳定,并且可能损害模型固有的强大推理能力。
本文旨在解决的核心问题是:如何有效地将在单步推理任务上表现出色的模型,转化为能够胜任长程、多轮、需要复杂工具使用的深度研究任务的自主单智能体,同时在训练中保持其推理能力和稳定性。
本文方法
本文提出的 SFR-DeepResearch 框架包含两大核心组件:智能体推理脚手架和端到端的强化学习训练配方。
智能体推理脚手架
工具集
为了激励智能体学习更高效的探索和工具使用策略,本文为其配备了一套功能极简的工具集:
- \(search_internet(query:str)\): 调用基础的搜索API,返回前10个搜索结果(包含URL、标题和摘要)。
- \(browse_page(url:str, section_id:int)\): 抓取并以Markdown格式返回网页内容。关键点在于,页面中的超链接被移除,使得智能体只能通过搜索引擎发现新URL,而不能直接点击页面链接。
- \(code_interpreter(code:str)\): 在本地执行无状态的Python代码。每次执行都是独立的,不共享变量,且禁止访问文件系统或敏感的系统包。
智能体工作流
本文发现不同模型家族具有不同的多轮交互特性,因此设计了针对性的工作流:
- 针对 QwQ 和 Qwen3 模型: 将传统的多轮对话格式重构为一个迭代式的单轮上下文问答任务。在每一步,智能体接收到的提示都只有一个用户回合,其中包含了原始问题以及之前所有工具调用和结果的摘要。这种方式将任务范式拉近了模型原本擅长的单步推理场景,显著提升了稳定性。
- 针对 gpt-oss 模型: 该模型具有更强的多轮交互能力,因此直接沿用其默认的多轮对话模板。
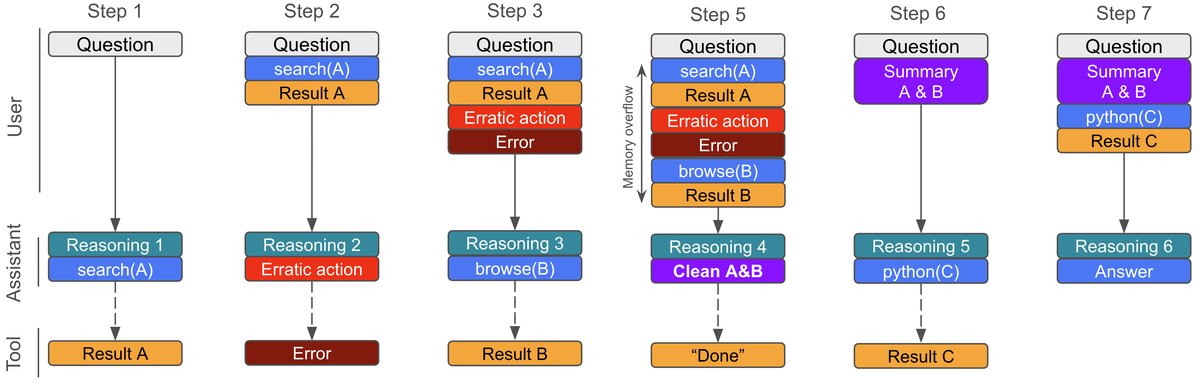
长程上下文管理
为解决长交互序列中上下文窗口溢出的问题,本文训练智能体自我管理其内存:
- 为 QwQ 和 Qwen 模型提供一个内部工具 \(clean_memory(content:str)\)。当上下文接近预设的内存缓冲区限制时,智能体会收到通知,并被要求调用该工具,自行总结和提炼关键信息来替换旧的上下文。
- 为 gpt-oss 模型则提供了编辑或删除单个历史工具调用结果的工具。
容错机制
为了应对模型在推理时可能出现的格式错误,系统实现了一套容错协议。对于可修复的错误进行修复,否则向模型返回语法错误信息,引导其在下一步中修正。
强化学习训练方法
训练数据合成
由于现有的开源数据集对于先进的推理模型而言过于简单,本文构建了一套新的、更具挑战性的合成训练数据。数据包含两类:
- 短格式问答: 通过迭代方式生成的、需要多跳推理和深入搜索才能解答的复杂问题。
- 长格式报告撰写: 利用LLM生成开放式研究问题的指令和详细的评分标准。
长度归一化的RL目标
本文采用 REINFORCE 算法的一个变体,其核心创新在于轨迹长度归一化。对于一个 rollout 轨迹,其每个步骤的优势(Advantage)计算公式如下:
\[A_{i,j}=A_{i}=\frac{r_{i}-\text{mean}(\overline{R})}{\text{std}(\overline{R})\cdot T_{i}}\]其中,$r_i$ 是轨迹的总奖励,$\overline{R}$ 是同一批次中所有轨迹的奖励集合,$T_i$ 是该轨迹的长度(工具调用次数)。这个分母项 $T_i$ 的作用是降低长轨迹中每一步的优势权重。
创新点:该设计解决了标准RL训练中的一个关键痛点。在没有长度归一化时,模型会倾向于生成更长的轨迹,因为长轨迹在损失计算中贡献了更多的步骤,即使这些轨迹是低效甚至错误的(如重复调用同一工具)。这种归一化惩罚了无效的“刷步数”行为,使得训练更稳定,并引导模型学习更高效、更有策略性的工具使用方式。
其它训练技术
- 轨迹过滤: 过滤掉无效(如格式错误)或因截断而未完成的轨迹。同时,通过随机或启发式丢弃来维持正负奖励轨迹的比例,避免模型崩溃。
- 部分 rollout: 将未完成的 rollout 轨迹作为新的初始状态,从中继续进行蒙特卡洛采样,以增加对长尾中间状态的学习。
- 奖励建模: 使用基座LLM自身作为奖励模型(Verifier),根据任务类型(短问答或长报告)进行评分。
实验结论
本文在一系列涵盖网页浏览和复杂推理的基准测试(FRAMES, GAIA, HLE)上对 SFR-DR 智能体进行了评估。
- 主要成果:
- 本文提出的 SFR-DR-20B 模型(基于 gpt-oss-20b)在各项基准上表现优异,不仅超越了同等规模的开源单智能体和多智能体系统,甚至在 HLE 基准上以 28.7% 的得分超过了 OpenAI 基于 o3 的 Deep Research 等部分专有系统。
- 相较于基座模型 gpt-oss-20b,SFR-DR-20B 在 HLE 上的性能相对提升了 65%,证明了本文 RL 微调方法的有效性。
- 8B 和 32B 版本的 SFR-DR 模型也比使用相同基座模型的其他开源方法表现更强。
| 智能体 | 基座模型 | FRAMES | GAIA | HLE/HLE-500 |
|---|---|---|---|---|
| 专有智能体 | ||||
| Deep Research (OpenAI, 2025) | o3 | - | 67.4 | 26.6/- |
| GPT-5 (OpenAI, 2025a) | GPT-5 | - | - | 35.2/- |
| gpt-oss-20b (Agarwal et al., 2025) | gpt-oss-20b | - | - | 17.3/- |
| 多智能体 | ||||
| OpenDeepSearch-QwQ (Alzubi et al., 2025) | QwQ-32B | 54.1* | - | 9.1*/- |
| WebThinker-32B (Li et al., 2025d) | QwQ-32B | 35.5* | 48.5† | -/15.8† |
| 单智能体 | ||||
| WebSailor-32B (Li et al., 2025a) | Qwen2.5-32B | 69.78* | 44.0* (53.2†) | 10.75*/ |
| WebShaper-32B (Tao et al., 2025) | QwQ-32B | 69.42* | 48.5* (53.3†) | 12.23*/ |
| AFM-32B (Li et al., 2025b) | Qwen2.5-32B | 55.3† | - | -/18.0† |
| SFR-DR-8B | Qwen3-8B | 63.3 | 41.7 | 13.2/14.0 |
| SFR-DR-32B | QwQ-32B | 72.0 | 52.4 | 16.2/17.1 |
| SFR-DR-20B | gpt-oss-20b | 82.8 | 66.0 | 28.7 |
- 分析与洞察:
- 工作流的有效性: 消融实验表明,为 QwQ/Qwen 模型设计的“单轮上下文问答”工作流带来了显著的无训练性能提升(例如在 FRAMES 上绝对提升 10%),因为它能有效避免模型在多轮交互中出现的思维退化。
| 智能体 | FRAMES | HLE |
|---|---|---|
| Qwen3-8B 多轮 | 52.5 | 8.8 |
| QwQ-32B 多轮 | 58.0 | 12.3 |
| SFR-DR-8B (RL前) | 58.8 | 9.9 |
| SFR-DR-32B (RL前) | 68.0 | 13.9 |
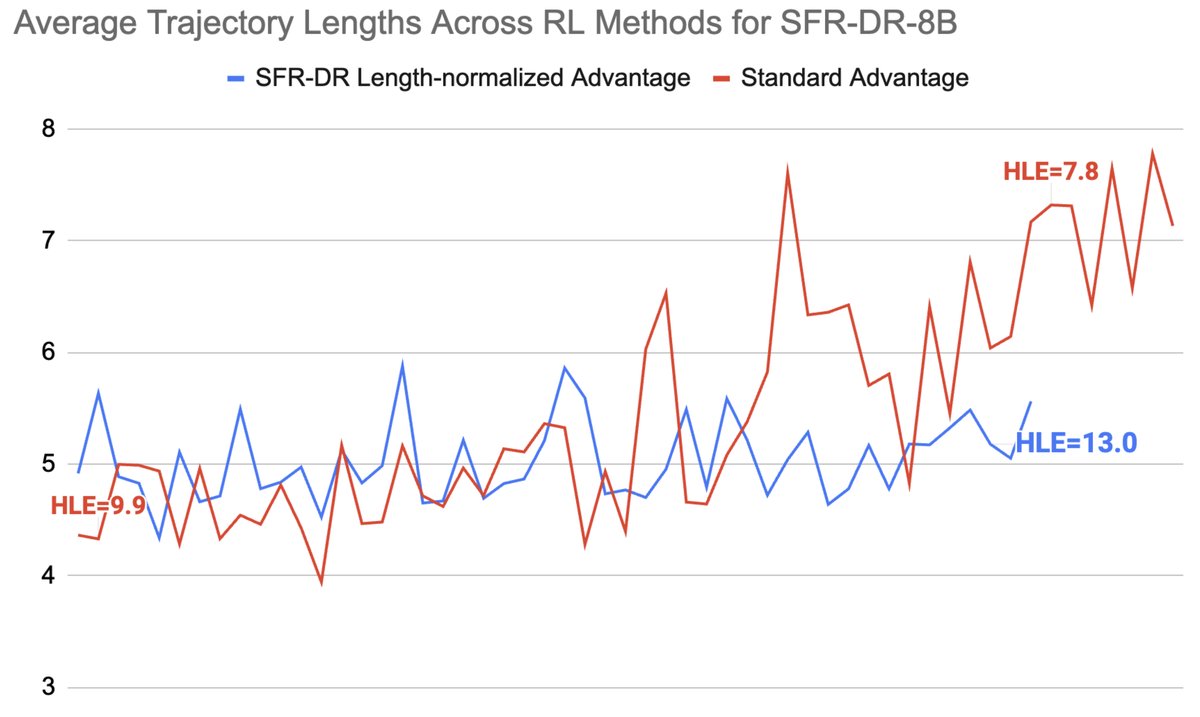
- 长度归一化的重要性: 对比实验证实,没有长度归一化时,模型会陷入“为了调用而调用”的恶性循环,工具调用次数急剧增加,但性能反而崩溃。长度归一化则能有效稳定训练,引导模型在适度增加工具使用的同时提升性能。
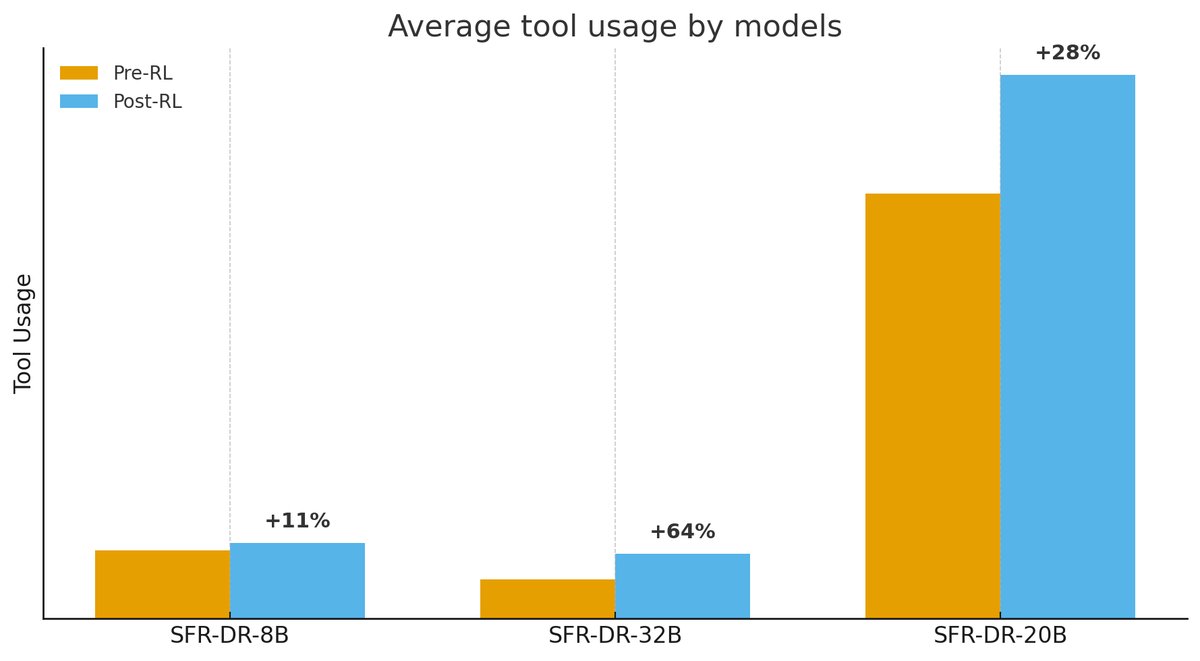
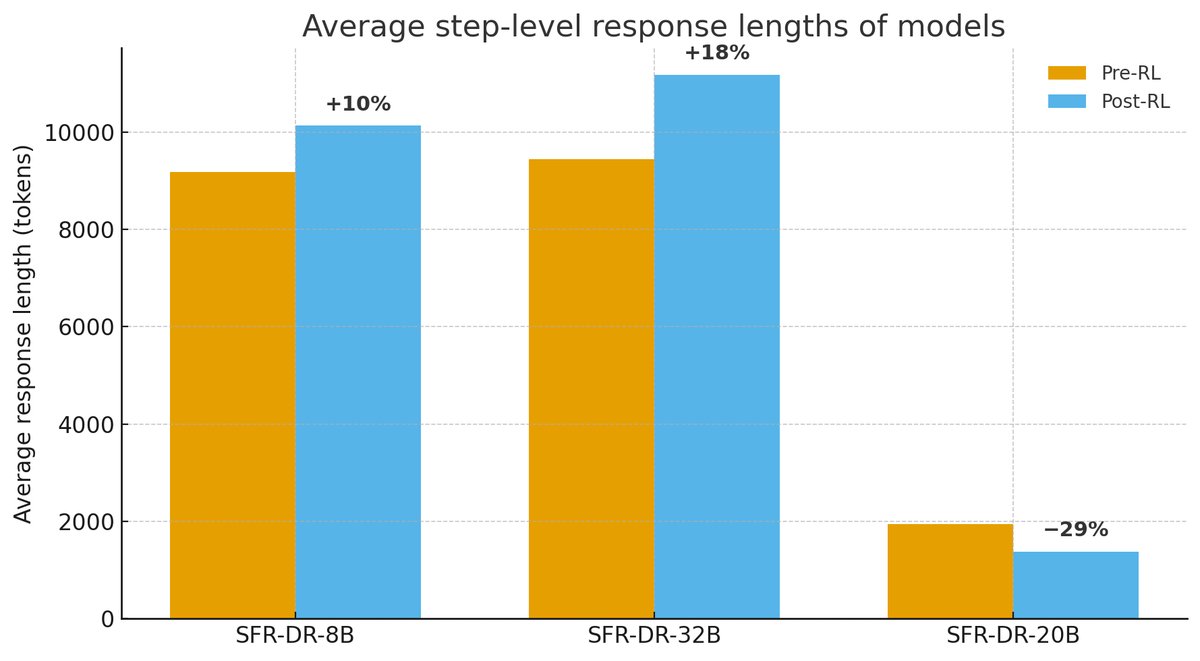
- 模型行为分析:
- gpt-oss-20b 模型相比 Qwen 家族模型,更倾向于使用工具进行探索,而不是仅依赖内部推理。
- gpt-oss-20b 的“思考”过程(CoT)也更为简洁高效,每一步生成的token数量远少于Qwen模型,这使得它更容易通过微调进行引导。
- 最终结论: 本文提出的基于合成数据的强化学习配方,能够成功地将推理优化的LLM转化为高效的自主单智能体。通过定制化的智能体工作流和创新的长度归一化RL目标,该方法有效解决了长程任务中的训练不稳定性问题,在保留模型推理能力的同时显著增强了其作为深度研究智能体的表现。