SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot
-
ArXiv URL: http://arxiv.org/abs/2301.00774v3
-
作者: Elias Frantar; Dan Alistarh
-
发布机构: Institute of Science and Technology Austria; Neural Magic Inc.
TL;DR
本文提出了一种名为 SparseGPT 的新颖剪枝方法,能够对超大规模语言模型(如 OPT-175B)进行一次性(One-Shot)剪枝,在不进行任何重新训练的情况下,达到50%-60%的稀疏度,同时保持极低的准确率损失。
关键定义
本文主要沿用并扩展了领域内已有的关键定义,其核心贡献在于解决这些定义所引出问题的全新算法。
-
逐层剪枝 (Layer-Wise Pruning):将整个模型的压缩问题分解为一系列独立的、针对每一层的子问题。对于每一层 \(l\),目标是找到一个稀疏掩码 \(M_l\) 和更新后的权重 \(\widehat{\mathbf{W}}_{\ell}\),以最小化剪枝前后层输出之间的 \(L2\) 误差。其目标函数为:
\[\operatorname{argmin}_{\max \mathbf{M}_{\ell}, \widehat{\mathbf{W}}_{\ell}} \mid \mid \mathbf{W}_{\ell} \mathbf{X}_{\ell} - (\mathbf{M}_{\ell} \odot \widehat{\mathbf{W}}_{\ell}) \mathbf{X}_{\ell} \mid \mid _2^2\] - 权重重构 (Weight Reconstruction):在确定了要剪枝的权重(即固定了掩码 \(M\))之后,调整剩余未剪枝的权重,以补偿因剪枝造成的精度损失。
- Hessian 矩阵:在逐层剪枝问题中,Hessian矩阵 \(H\) 定义为输入激活的二阶矩,即 \(H = XX^T\)。该矩阵的逆 \(H^{-1}\) 对于计算剪枝一个权重后其他权重的最优更新至关重要。
相关工作
当前,大型语言模型(LLM)因其巨大的参数量和计算成本而难以部署。模型压缩是解决此问题的关键路径,主要包括量化和剪枝。
- 现状:量化研究已在 GPT-3 规模的模型上取得进展。然而,剪枝领域的SOTA方法大多需要昂贵的重新训练来恢复精度,这对于超大规模模型来说不切实际。而已有的一次性剪枝方法,如 AdaPrune,虽然准确,但计算成本过高,无法扩展到百亿参数级别的模型;更简单的方法如幅度剪枝 (Magnitude Pruning),在稀疏度稍高时会导致模型精度急剧下降。
- 问题:领域内缺少一种能够同时满足准确、高效和可扩展性的一次性剪枝方法,来处理拥有超过1000亿参数的巨型模型。
- 本文目标:提出一种名为 SparseGPT 的一次性剪枝算法,它足够快,可以在数小时内处理175B规模的模型,并且足够准确,能够在高达60%的稀疏度下保持接近原始模型的性能。
本文方法
方法动机:精确重构的扩展性瓶颈
对于一个给定的剪枝掩码 \(M\),最优的权重重构需要对每一行 \(i\) 分别求解一个稀疏回归问题。这涉及到计算并求逆一个与该行特定掩码相关的 Hessian 子矩阵 \(H_{M_i}\)。由于每一行的剪枝掩码 \(M_i\) 都不同,导致需要对 \(d_{row}\) 行中的每一行都进行一次独立的 \(O(d_{col}^3)\) 复杂度的矩阵求逆,总复杂度高达 \(O(d_{row} \cdot d_{col}^3)\)。对于 Transformer 模型中的 \(d_{hidden} \times d_{hidden}\) 矩阵,其复杂度为 \(O(d_{hidden}^4)\),这在计算上是不可行的。
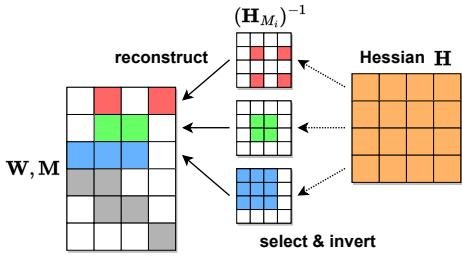 图3:行-Hessian 挑战图示:各行独立稀疏化,不同行的掩码不同导致无法共享Hessian逆矩阵的计算。
图3:行-Hessian 挑战图示:各行独立稀疏化,不同行的掩码不同导致无法共享Hessian逆矩阵的计算。
核心机制:Hessian 同步与近似重构
SparseGPT 的核心创新在于设计了一种高效的近似重构算法,它巧妙地规避了为每行计算独立 Hessian 逆矩阵的瓶颈。
- 迭代视角:本文首先从 OBS (Optimal Brain Surgeon) 框架的迭代视角出发。剪掉一个权重 \(w_m\) 后,对剩余权重的最优更新 \(\delta\) 可以通过 \(H^{-1}\) 精确计算。通过迭代地、一次一个地剪掉所有待移除的权重,最终可以得到与直接求解稀疏回归问题相同的最优解。
- 部分更新:OBS 更新通常会调整所有未剪枝的权重。本文发现,可以只选择一个子集 \(U\) 的权重进行更新,这虽然可能降低补偿效果,但如果 \(U\) 较小,则计算 \(H_U\) 的逆会快得多。
- Hessian 同步:这是算法的关键。SparseGPT 按列顺序处理权重矩阵 \(W\)。对于每一列 \(j\),它使用一个预先计算好的、共享的逆 Hessian 矩阵 \((H_{U_j})^{-1}\) 来执行剪枝操作。这里的 \(U_j\) 是一个递减的索引集 \(U_{j+1} = U_j - \{j\}\)。通过这种方式,所有行在处理同一列 \(j\) 时,都使用相同的逆 Hessian 矩阵。
- 高效实现:整个逆 Hessian 序列 \((H_{U_j})^{-1}\) 可以通过高斯消元法从初始的 \(H^{-1}\) 在 \(O(d_{col}^3)\) 时间内递归计算得出。这使得总的重构时间复杂度从 \(O(d_{row} \cdot d_{col}^3)\) 大幅降低到 \(O(d_{col}^3 + d_{row} \cdot d_{col}^2)\),对于 Transformer 模型即为 \(O(d_{hidden}^3)\),实现了关键的 \(d_{hidden}\) 倍加速。
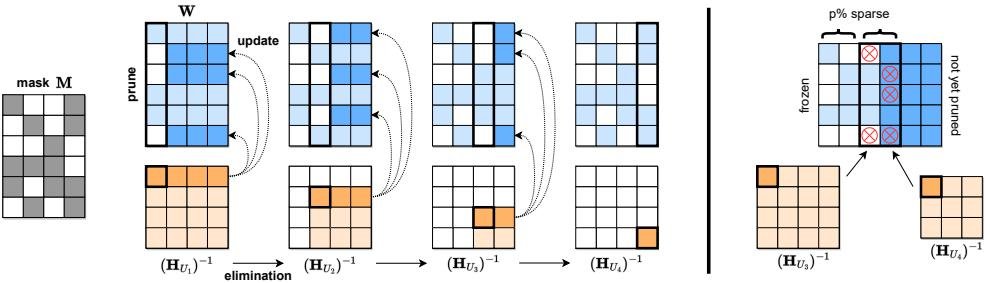 图4:SparseGPT 重构算法可视化。算法按列处理权重,并使用一系列共享的Hessian逆矩阵更新该列右侧的权重,以补偿剪枝误差。
图4:SparseGPT 重构算法可视化。算法按列处理权重,并使用一系列共享的Hessian逆矩阵更新该列右侧的权重,以补偿剪枝误差。
自适应掩码选择
为了进一步提升精度,SparseGPT 并非使用固定的剪枝掩码,而是采用自适应掩码选择策略。它以 \(B_s = 128\) 列为一个块 (block),在处理每个块之前,根据 OBS 误差准则(\(\varepsilon_m = w_m^2 / [H^{-1}]_{mm}\))为这个块内的所有权重动态选择剪枝掩码。这使得剪枝决策能够考虑到之前权重更新带来的影响,并且允许稀疏度在不同列之间非均匀分布,从而保护那些对模型性能至关重要的“离群特征 (outlier features)”。
扩展能力
- 半结构化稀疏:SparseGPT 可以轻松适应硬件友好的 n:m 稀疏模式(如 NVIDIA Ampere GPU 支持的 2:4 稀疏)。只需将块大小 \(B_s\) 设为 \(m\),并在每个 \(m\) 大小的权重组内,为每一行选择 \(n\) 个误差最小的权重进行剪枝。
- 联合量化:由于 SparseGPT 的列式贪心框架与先进的量化算法 GPTQ 兼容,本文将两者结合,实现剪枝与量化的联合处理。在同一次计算过程中,被剪枝的权重被设为0,未被剪枝的权重则被量化,其误差(剪枝误差+量化误差)被传播并由后续的权重进行补偿。这几乎不增加额外计算成本。
完整算法伪代码
算法1展示了集成所有优化技术的非结构化稀疏版 SparseGPT。
| 算法 1: SparseGPT 算法 |
|---|
| 输入: 权重矩阵 \(W\), 逆 Hessian \(H^{-1}\), 批更新块大小 \(B\), 自适应掩码块大小 \(B_s\), 稀疏度 \(p\) |
| \(M\) ← \(1^{d_{row} \times d_{col}}\) // 初始化二进制剪枝掩码 |
| \(E\) ← \(0^{d_{row} \times B}\) // 块误差 |
| \(H^{-1}\) ← \(Cholesky(H^{-1})^T\) // Cholesky分解以获取Hessian逆信息 |
| for \(i = 0, B, 2B, ...\) do |
| for \(j = i, ..., i + B - 1\) do |
| if \(j mod B_s == 0\) then |
| \(M[:, j:(j+B_s)]\) ← 根据 \(w_c^2 / [H^{-1}]_{cc}\) 在 \(W[:, j:(j+B_s)]\) 中选择 \((1-p)%\) 最大值的掩码 |
| end if |
| \(err\) ← \((W[:, j] - E[:, j-i]) / [H^{-1}]_{jj}\) // 计算剪枝误差 |
| \(E[:, j-i]\) ← \((1 - M[:, j]) \cdot err\) // 累积被剪掉权重的误差 |
| \(W[:, j:(i+B)]\) ← \(W[:, j:(i+B)] - E[:, j-i] \cdot H^{-1}_{j, j:(i+B)}\) // 更新权重 |
| end for |
| \(W[:, (i+B):]\) ← \(W[:, (i+B):] - E \cdot H^{-1}_{i:(i+B), (i+B):}\) // 批处理更新 |
| end for |
| \(W\) ← \(W \odot M\) // 将剪枝后的权重设为0 |
实验结论
本文在一系列超大规模模型(OPT 和 BLOOM 系列)上进行了广泛实验,所有实验均在单张 A100 GPU 上完成,结果令人瞩目。
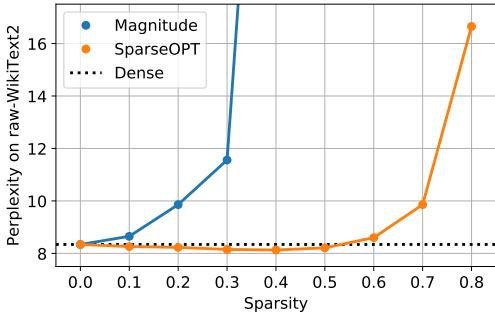 图1:OPT-175B 上 SparseGPT 与幅度剪枝的稀疏度-困惑度对比。
图1:OPT-175B 上 SparseGPT 与幅度剪枝的稀疏度-困惑度对比。
- 在大模型上的卓越性能:在 OPT-175B 上,SparseGPT 能达到 60% 的非结构化稀疏度,而困惑度 (Perplexity) 增加可忽略不计。相比之下,幅度剪枝在稀疏度超过 10% 后性能即开始显著下降,在 30% 时完全失效。在 BLOOM-176B 上也观察到类似趋势。这表明 SparseGPT 能够从这些模型中移除超过1000亿个权重,而几乎不影响其性能。
 图2:使用SparseGPT将OPT模型家族压缩到不同稀疏模式时的困惑度对比。
图2:使用SparseGPT将OPT模型家族压缩到不同稀疏模式时的困惑度对比。
- “越大越可压”的伸缩法则:实验揭示了一个重要趋势:模型规模越大,对剪枝的鲁棒性越强。如上图2所示,对于 50% 的稀疏度,OPT-175B 的困惑度几乎没有增加,而较小的模型则有明显性能下降。这表明大型模型的过参数化程度更高。
| OPT - 50% 稀疏度 | 125M | 350M | 1.3B | 2.7B | 6.7B | 13B | 30B | 66B | 175B |
|---|---|---|---|---|---|---|---|---|---|
| Dense | 27.66 | 22.00 | 14.62 | 12.47 | 10.86 | 10.13 | 9.56 | 9.34 | 8.35 |
| Magnitude | 193. | 97.80 | 1.7e4 | 265. | 969. | 1.2e4 | 168. | 4.2e3 | 4.3e4 |
| SparseGPT | 36.85 | 31.58 | 17.46 | 13.48 | 11.55 | 11.17 | 9.79 | 9.32 | 8.21 |
| SparseGPT 4:8 | 58.66 | 48.46 | 32.52 | 14.98 | 12.56 | 11.77 | 10.30 | 9.65 | 8.45 |
| SparseGPT 2:4 | - | - | - | 17.18 | 14.20 | 12.96 | 10.90 | 10.09 | 8.74 |
- 半结构化与联合压缩:SparseGPT 在硬件友好的 2:4 和 4:8 稀疏模式下同样表现出色,尤其是在最大的模型上,性能损失很小。与 4-bit 量化结合后,50%稀疏+4-bit量化的模型在精度上优于同等存储空间的 3-bit 量化模型。
| 方法 | 稀疏度 | Lambada | PIQA | ARC-e | ARC-c | Story. | 平均 |
|---|---|---|---|---|---|---|---|
| Dense | 0% | 75.59 | 81.07 | 71.04 | 43.94 | 79.82 | 70.29 |
| Magnitude | 50% | 00.02 | 54.73 | 28.03 | 25.60 | 47.10 | 31.10 |
| SparseGPT | 50% | 78.47 | 80.63 | 70.45 | 43.94 | 79.12 | 70.52 |
| SparseGPT | 4:8 | 80.30 | 79.54 | 68.85 | 41.30 | 78.10 | 69.62 |
| SparseGPT | 2:4 | 80.92 | 79.54 | 68.77 | 39.25 | 77.08 | 69.11 |
-
零样本任务验证:在多个零样本(ZeroShot)任务上的评估也验证了同样的趋势。SparseGPT 剪枝后的模型在各项任务上与原始模型表现相当,而幅度剪枝的模型则性能崩溃。
-
总结:本文首次证明了在不进行任何微调的情况下,通过一次性剪枝即可将百亿亿级参数的 GPT 模型压缩至高稀疏度,同时保持极高的精度。SparseGPT 作为一种高效、准确且可扩展的算法,为大规模语言模型的实际部署开辟了新的可能性,并揭示了这些模型中存在大量的冗余参数,可以在不依赖梯度信息的情况下被安全移除。