Spotlight Attention: Towards Efficient LLM Generation via Non-linear Hashing-based KV Cache Retrieval
-
ArXiv URL: http://arxiv.org/abs/2508.19740v1
-
作者: Ziyang Gong; Fei Chao; Wenhao Li; Gen Luo; Rongrong Ji; Yuxin Zhang
-
发布机构: Shanghai AI Laboratory; Shanghai Jiao Tong University; Xiamen University
TL;DR
本文提出Spotlight Attention,一种通过可学习的非线性哈希函数来高效检索KV缓存(Key-Value Cache)的方法,从而在几乎不损失性能的前提下,显著提升大语言模型(LLM)的推理速度。
关键定义
- Spotlight Attention: 本文提出的一种新型注意力机制。它不计算所有token的注意力,而是使用一个基于多层感知机(MLP)的非线性哈SHI函数,将查询(query)和键(key)编码成紧凑的二进制哈希码,通过计算哈希码之间的汉明距离快速检索出最重要的top-k个键值对,仅对这些选中的键值对进行注意力计算,从而大幅提升效率。
- MLP Hashing: Spotlight Attention的核心技术。它使用一个小型两层MLP替代传统方法中的线性投影,来生成哈希码。这种非线性变换能更好地拟合LLM中查询(Query)和键(Key)在高维空间中独特的“锥形分布”,从而用更短的哈希码实现更高的检索精度。
- Bradley-Terry Ranking Loss: 一种为优化MLP哈希函数而设计的排序损失函数。其目标并非精确重建原始注意力分数,而是确保基于哈希码估计出的top-k个token与真实注意力分数选出的top-k个token尽可能一致。具体而言,它只惩罚“非top-k”的token得分高于“top-k”的token得分的情况,从而将模型的学习能力集中在区分重要与非重要token上,而非不必要的内部排序。
相关工作
当前大型语言模型推理的主要瓶颈在于处理和存取巨大的键值缓存(KV Cache)。为了解决此问题,研究主要分为三类:
- 静态KV缓存剪枝:在推理前一次性压缩KV缓存。这类方法如FastGen和SnapKV,适用于长提示(prompt)短生成的场景,但无法应对需要持续生成长文本的任务。
- 带永久驱逐的动态剪枝:在解码过程中动态剪枝,并永久删除被认为不重要的token。这类方法如H2O,虽然灵活,但可能过早丢弃后续步骤中会变得重要的token,导致在长依赖任务中性能下降。
- 不带永久驱逐的动态剪枝:在每一步解码时动态选择一部分KV缓存参与计算,而不永久删除任何token。这是目前性能保持最好的方向。代表性工作如Quest在块(block)级别进行粗粒度选择,效率高但精度不足;MagicPIG实现了token级别的检索,但它使用的线性哈希(LSH)效率低下,因为LLM的Query和Key分布在两个几乎正交的窄锥形区域内,线性分割面效果差,导致需要极长的哈希码(如1024位)才能保证精度,带来了巨大的存储和计算开销。
本文旨在解决MagicPIG中线性哈希方法效率低下的问题,通过引入非线性哈希,以更短的哈希码实现更精确、更高效的KV缓存检索。
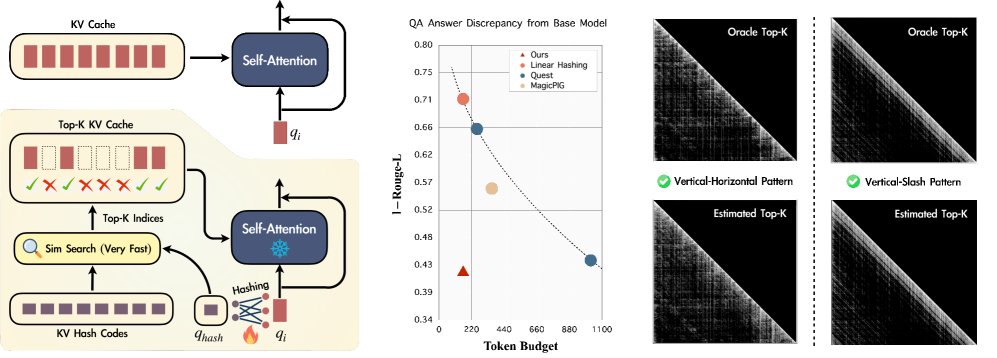 图1:概览 (左) Spotlight Attention在标准注意力机制基础上,为每一层增加了一个基于哈希码的检索模块。(中) 在问答数据集上,Spotlight Attention实现了最精确的检索,生成了与原始模型最接近的响应。(右) 即使面对任意复杂的注意力模式,本文方法也能很好地估计top-k序列。
图1:概览 (左) Spotlight Attention在标准注意力机制基础上,为每一层增加了一个基于哈希码的检索模块。(中) 在问答数据集上,Spotlight Attention实现了最精确的检索,生成了与原始模型最接近的响应。(右) 即使面对任意复杂的注意力模式,本文方法也能很好地估计top-k序列。
本文方法
本文方法Spotlight Attention的核心在于用一个经过优化的非线性哈希函数来代替现有方法中的线性哈希,以实现更高效准确的KV缓存检索。
创新点:非线性MLP哈希
与MagicPIG使用线性投影矩阵\(R\)生成哈希码(即 $\mathcal{H}(x)=\text{sign}(xR)$)不同,Spotlight Attention采用了一个两层的MLP网络来代替\(R\)。
\[\text{MLP}(x)=W_{2}\big{(}\text{SiLU}(W_{1}x+b_{1})\big{)}\]哈希码则通过以下方式计算:
\[\mathcal{H}(x)=\text{sign}(\text{MLP}(x))\]该设计的核心动机是:先前研究发现LLM中的Query和Key向量在高维空间中分别聚集在两个狭窄的、近乎正交的锥形区域内。传统的线性哈希使用超平面来划分空间,难以有效分割这种倾斜的、非均匀的分布,导致编码效率低下。而MLP能够学习到非线性的决策边界(弯曲的表面),可以更灵活、更紧凑地对数据空间进行划分,从而用更短的哈希码(本文使用128位)承载更多信息,提升检索的准确性。
 图2:动机 (a) 实验表明,将哈希函数从线性升级到MLP可带来巨大提升。(b) 这是因为Query和Key通常分布在空间中的两个小锥体内。(c) 在这种情况下,线性边界难以均匀地划分空间。(d) 而使用MLP哈希函数可以很好地解决这个问题。
图2:动机 (a) 实验表明,将哈希函数从线性升级到MLP可带来巨大提升。(b) 这是因为Query和Key通常分布在空间中的两个小锥体内。(c) 在这种情况下,线性边界难以均匀地划分空间。(d) 而使用MLP哈希函数可以很好地解决这个问题。
核心贡献:高效的训练框架与排序损失
为了让MLP哈希函数能够适配Query和Key的分布,本文设计了一个轻量级且高效的训练框架。
- 优化目标:本文没有采用计算成本高昂的语言模型损失,也没有采用易受离群值影响且会浪费模型能力的MSE重建损失。而是采用了受RankNet启发的Bradley-Terry排序损失。
- 损失函数:训练时,首先通过标准的注意力计算得到真实的top-k索引集。然后,将通过哈希码汉明距离计算出的估计得分分为top-k集合 \(B\) 和非top-k集合 \(C\)。损失函数的目标是让集合 \(B\) 中的每一个分数都高于集合 \(C\) 中的所有分数。
其中 \(β\) 和 \(α\) 为超参数,用于放大分数差异,促进收敛。这种损失函数只关注“是否属于top-k”的分类问题,而忽略集合内部的排序,从而避免了模型容量的浪费,使优化目标更明确。
- 可微性处理:由于\(sign\)函数不可导,在训练过程中,使用了一个平滑的\(softsign\)函数来替代它,而在推理时则换回原始的\(sign\)函数。
- 训练效率:该训练框架仅需优化轻量级的MLP参数,LLM主干模型保持冻结。训练过程可逐层独立进行,仅需少量校准数据(如8192个样本),在单张16GB显存的GPU上仅需8小时即可完成。
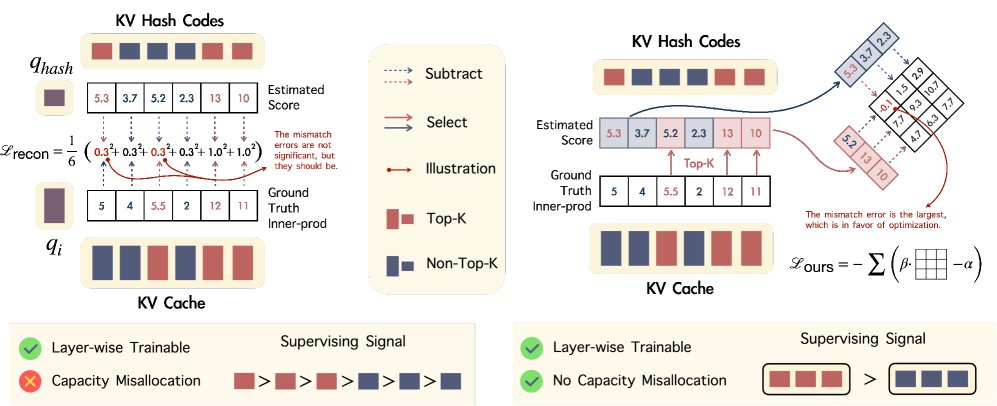 图3:优化 (左) 重建损失最小化估计与真实注意力得分之间的MSE,但对分数大小敏感且易受离群值影响,并浪费模型容量。(右) 本文提出的排序损失采用Bradley–Terry排序目标,对分数大小和离群值鲁棒,且仅专注于区分top-k和非top-k集合,监督更有效。
图3:优化 (左) 重建损失最小化估计与真实注意力得分之间的MSE,但对分数大小敏感且易受离群值影响,并浪费模型容量。(右) 本文提出的排序损失采用Bradley–Terry排序目标,对分数大小和离群值鲁棒,且仅专注于区分top-k和非top-k集合,监督更有效。
实验结论
实验在LLaMA、Qwen2.5等多个模型上验证了Spotlight Attention的性能和效率。
关键结果
- KV检索精度:在剪枝98% KV缓存的设定下,经过训练的MLP哈希(Spotlight)在检索准确率(IoU)上达到0.41,远高于经过训练的线性哈希(0.20)和未经训练的MLP哈希(0.05),证明了非线性结构和排序损失训练的有效性。
| LSH Top-2% | MLP Hashing Top-2% (本文) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 模型 | 原始PPL | Oracle Top-2% | 训练前 IoU/PPL | 训练后 IoU/PPL | 训练前 IoU/PPL | 训练后 IoU/PPL | |||
| LLaMA2-7B | 5.58 | 1.00 / 5.69 | 0.17 / 5.86 | 0.20 / 5.84 | 0.05 / 20.31 | 0.41 / 5.72 | |||
| LLaMA3-8B | 6.45 | 1.00 / 6.63 | 0.15 / 7.12 | 0.18 / 7.07 | 0.07 / 148.2 | 0.34 / 6.69 |
表1: KV检索精度对比(IoU越高越好,PPL越低越好)。训练对MLP哈希至关重要,且效果远超线性哈希。
- 语言模型困惑度(Perplexity):在PG19等数据集上,Spotlight Attention的性能远超Quest(使用了10倍的token预算),且优于MagicPIG。特别地,在移除局部窗口和sink token等启发式策略后,MagicPIG性能严重下降,而Spotlight能自主识别这些关键token,展现了更高鲁棒性。
 图4: NIAH测试结果。在使用LLaMA3-8B作为基础模型时,Spotlight Attention(仅依赖哈希检索)实现了与原始模型相当的响应准确率。
图4: NIAH测试结果。在使用LLaMA3-8B作为基础模型时,Spotlight Attention(仅依赖哈希检索)实现了与原始模型相当的响应准确率。
- 长文本问答与保真度:在LongBench测试中,Spotlight Attention的表现最接近原始模型。其生成内容的Rouge-L得分与原始模型相比达到0.58,显著高于MagicPIG的0.44和Quest的0.56(后者token预算是Spotlight的6倍)。
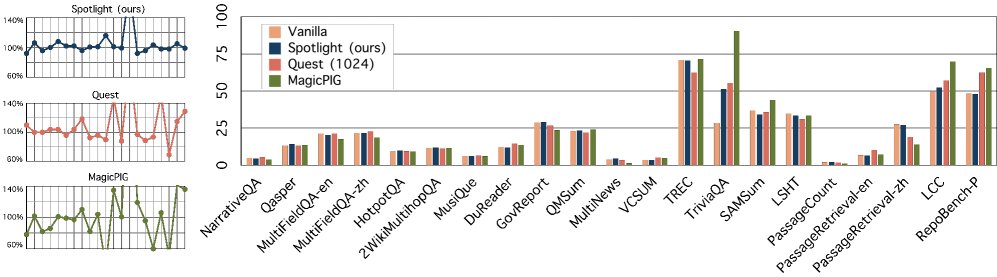 图5: 下游QA任务。(左) 各方法与原始模型基线的相对得分,Spotlight的点更接近于原始模型。(右) 各子任务上的绝对得分比较。
图5: 下游QA任务。(左) 各方法与原始模型基线的相对得分,Spotlight的点更接近于原始模型。(右) 各子任务上的绝对得分比较。
- 推理效率:通过专门的CUDA-kernel优化,哈希检索过程(512K tokens)耗时低于100μs。在端到端测试中,对于32K和128K序列长度,Spotlight Attention相比标准解码(vanilla decoding)实现了高达3倍的吞吐量提升。
 图6: 效率。(左) Spotlight Attention在不同批处理大小和上下文长度下均带来显著的吞吐量提升。(右) Spotlight哈希码尺寸远小于MagicPIG,且核心操作(位打包和相似度搜索)的延迟极低。
图6: 效率。(左) Spotlight Attention在不同批处理大小和上下文长度下均带来显著的吞吐量提升。(右) Spotlight哈希码尺寸远小于MagicPIG,且核心操作(位打包和相似度搜索)的延迟极低。
总结
实验结果全面验证了Spotlight Attention的优势。它通过非线性MLP哈希和高效的排序损失训练,成功解决了现有方法的局限性,用短得多的哈希码(至少缩短5倍)实现了更高的检索精度。该方法在语言建模、长文本问答等多个任务上保持了与原始模型高度一致的性能,同时将端到端推理吞吐量提升了最多3倍,展现了其在加速LLM推理方面的巨大潜力与实用价值。